使用 Python 介绍 Trie2025年3月17日 | 阅读 15 分钟 一种名为 "Trie" 的树形信息结构,被描述为用于存储字符串集合并对其进行快速搜索。名称 "Trie" 来自于动词 "Retrieval"(检索),意指查找或获取某物的行为。 Trie 遵循一个规则,即如果两个字符串共享一个前缀,那么它们在 Trie 中将拥有相同的祖先。Trie 可以用来查找 Trie 中是否存在具有特定前缀的字符串,也可以用来按字母顺序对字符串集合进行排序。 为什么需要 Trie 数据结构?Trie 数据结构用于数据存储和检索;类似的操作也可以使用哈希表数据结构来完成。然而,Trie 在执行这些任务时更有效。此外,Trie 相比哈希表有其自身的优势。基于前缀的查找可以使用 Trie 数据结构完成,而使用哈希表则不可能实现。 Trie 的基本结构是一种树状排列,其中每个节点代表一个字符串的单个字母或部分。从代表空字符串的根节点开始,当您沿着树向下移动时,字符被添加以创建完整的单词或短语。这种分层组织使得基于字符串的操作能够快速准确地进行。 Trie 的一个显著特点是其能够快速完成诸如查找具有相同前缀的单词或识别字典中满足特定模式的所有术语等任务。这些操作的时间复杂度取决于查询字符串的长度,而不是数据集的大小,这使得 Trie 在处理需要大量字符串集合的任务时非常高效。 此外,Trie 还用于字典和自动完成功能,这在聊天平台、代码编辑器和搜索引擎等应用程序中增强了用户体验。它们高效的前缀匹配能力可以实现实时建议,提高了用户交互的可用性和效率。 Trie 还有其他类型,如常规 Trie、压缩 Trie 和三叉搜索树,每种类型都旨在优化特定的用例。例如,压缩 Trie 通过合并共同前缀来最小化空间复杂度,而三叉搜索树则非常擅长有效管理大型词汇表。 Trie 有许多应用,包括 IP 路由、拼写检查和自然语言处理。理解 Trie 对于提高文本相关计算的速度和准确性以及优化基于字符串的算法仍然至关重要。 总而言之,Trie 是一种至关重要的数据结构,它能实现高效的基于字符串的操作。由于其在各种应用中的适应性和速度,它们提高了依赖于字符串匹配、搜索和索引的系统的性能。在不断扩展的计算机科学和信息技术领域,掌握 Trie 对于利用其强大功能和优化文本相关任务的算法至关重要。 Trie 信息结构相比哈希表有几个优势。 Trie 信息结构在以下方面优于哈希表
Trie 数据结构的属性我们知道 Trie 的组织结构像一棵树。因此,了解其特性至关重要。 下面列出了 Trie 信息结构的一些关键特性
Trie 信息设计  Trie 数据结构是如何工作的?我们知道,Trie 信息结构中可以使用任何数量的字符,包括字母、数字和特殊字符。但是,这里我们将专注于包含字母 a 到 z 的字符串。因此,每个节点需要 26 个指针,其中第 0 个索引表示字母 "a",第 25 个索引表示字符 "z"。 任何小写英文单词都可能以从头到尾的字母之一开始,然后是单词的第三个字母,同样是从 a 到 z 的字母之一,依此类推。为了存储一个单词,我们必须使用一个大小为 26 的数组(容器)。由于一开始没有单词,数组中的字符都是空的,如下所示。  让我们看看 Trie 数据结构如何存储 "and" 和 "ant" 这两个词 1. 在 Trie 数据结构中存储 "and"
2. 在 Trie 数据结构中存储 "ant"
存储 "and" 和 "ant" 这两个词后,Trie 将如下所示  Trie 节点的表示每个 Trie 节点包含一个字符指针数组或哈希映射,以及一个标志,指示单词是否在该节点结束。但如果单词只包含小写字母(即 a-z),我们可以使用数组来创建 Trie 节点,而不是使用哈希映射。 Trie 数据结构的基本操作
1. Trie 数据结构的插入操作此操作将新字符串添加到 Trie 数据结构中。让我们先测试一下这个 让我们尝试在这句话中添加 "and" 和 "ant"  在上面显示的插入表示中,单词 "and" 和 "ant" 有一个共同的节点(即 "an")。这是由于 Trie 数据结构的特性,即如果两个字符串共享一个前缀,它们将有相同的祖先。 现在让我们尝试插入 "dad" 和 "do"  在 Trie 数据结构中实现插入 算法
以下是上述算法的执行过程 2. Trie 数据结构搜索搜索操作与 Trie 中的插入操作唯一的不同之处在于,每当我们发现 curr 节点中的指针数组不指向单词的当前字符时,我们返回 false,而不是为该字符创建一个新节点。 使用此策略,您可以检查一个字符串是否存储在 Trie 信息结构中。Trie 信息结构有两种不同的搜索技术。
这两种方法都使用类似的研究模式。将一个单词完全转换为字母,并将每个字母与从根节点开始的 trie 节点进行比较,是 Trie 查找给定单词的初始步骤。如果找到了当前字符,则继续到该节点的子节点。持续这样做,直到找到所有字符。 2.1 Trie 数据结构前缀搜索:在 Trie 数据结构中查找前缀 "an"。  Trie 数据结构中的前缀搜索实现 2.2 在 Trie 数据结构中进行完整单词搜索 这与前缀搜索类似,但我们还必须确定单词是否在最后一个字符处结束。 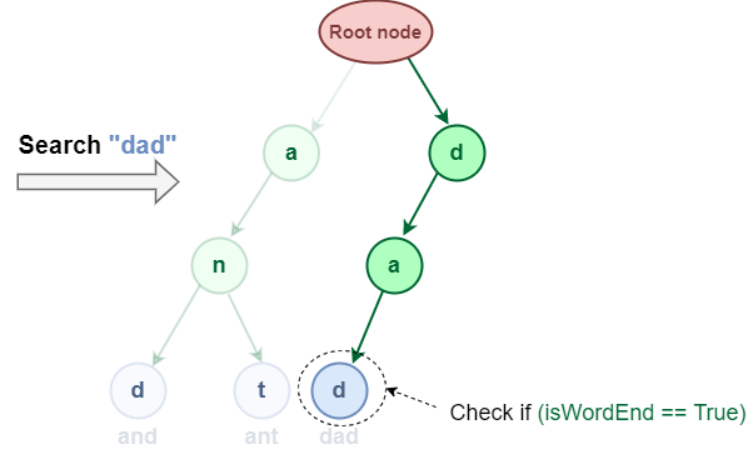 使用搜索算法与 Trie 数据结构 3. Trie 数据结构删除字符串可以使用此方法从 Trie 数据结构中删除。从 Trie 中删除一个单词时,有三种情况。
示例 3.1 被删除的单词是其他 Trie 单词的前缀。 如附图所示,被删除的单词 "an" 与单词 "and" 和 "ant" 共享一个完整的前缀。  在这种情况下,通过在单词结束节点处将单词计数减 1 来执行删除操作。 3.2 被删除的单词与 Trie 中的其他单词有共同的前缀。 如附图所示,被删除的词 "and" 有几个前缀,与以 "ant" 开头的其他词相同。它们都以 "an" 开头。 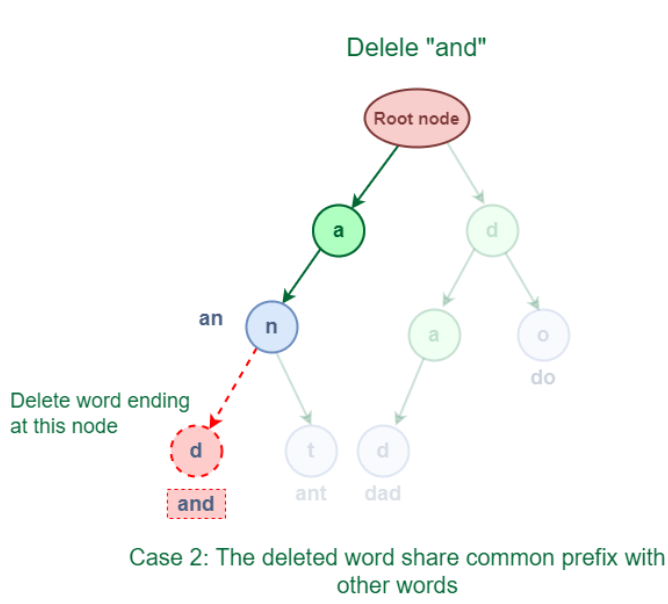 3.3 被删除的单词与任何其他 Trie 术语没有共同的前缀。 如附图所示,术语 "java" 与任何其他单词没有共同的前缀。  在这种情况下,只需删除每个节点即可解决问题。 下面显示了处理上述所有情况的实现 Trie 数据结构是如何实现的?
输出 Query String: do The query string is present in the Trie Query String: java The query string is present in the Trie Query String: bat The query string is not present in the Trie Query String: java The query string is successfully deleted Query String: tea The query string is not present in the Trie Trie 数据结构复杂度分析
注意:在上面的复杂度图中,"n" 和 "m" 分别代表字符串长度和存储在 Trie 中的字符串数量。Trie 数据结构的应用包括1. 自动完成功能: 自动完成功能根据您输入的搜索词提供建议。自动完成功能是使用 trie 数据结构实现的。  2. 拼写检查器: 如果单词没有出现在字典中,它们会根据您输入的内容提供建议。 它有3个步骤,如下所示
Trie 保存字典数据,促进了字典术语搜索算法的开发,并提供了一个可接受的建议词列表。 3. 最长前缀匹配: 它通常被称为最长前缀匹配算法,是 IP 网络中使用的一种路由技术。连续掩码对于网络路由优化是必要的,它将搜索时间复杂度限制为 O(n),其中 n 是 URL 地址的位数。 为了加快搜索过程,开发了多种位 Trie 方法,通过更快地进行多位查找来提速。 Trie 数据结构的优点
Trie 数据结构的缺点
|
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
