Python 中的 Box-Cox 变换2025年3月17日 | 阅读 3 分钟 在我们的环境中,数据是随机分布的,其中一些数据指的是数据集曲线的峰值,而另一些数据点则指的是曲线的尾部。对于任何数据集,我们可以通过其方差和均值来计算分布,并且可以看到数据距离均值的分布程度。 通常,我们可以将数据的分布分为两种方式
正态分布在这种分布类型中,数据沿均值的分布非常一致。在这里,我们在均值处获得曲线的峰值,并且数据沿均值对称分布。 我们可以轻松地对正态分布的数据实现分析技术。 幂律分布在这种分布类型中,对于一些小型数据集,我们会得到曲线的峰值,然后对于大量数据集,我们会得到一条长尾曲线。 但是,在实际环境中,数据的性质并非总是正态分布的。因此,借助 box-cox 变换,我们可以使用一些数学公式将幂律分布的数据转换为正态分布的数据。 变换的数学分析是,我们将找到一个值,使得非正态分布的变换尽可能接近正态分布的数据集。 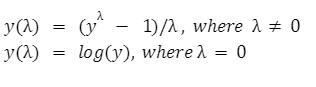 要实现 box-cox 变换,我们将使用 scipy 库,函数将是 scipy.stats.boxcox() 函数。 语法InputArray 这是我们想将其转换为正态分布数据集的数据集。 Lamda 如果 lambda 为 none,我们将找出使对数函数值最大化的 lambda 值;如果 lambda 不是 none,则在 lambda 值上执行变换。 Alpha 版 这是一个可选参数,取值在 0.0 到 1.0 之间的浮点数。如果 lambda 为 none,则将其考虑在内;如果 lambda 不是 none,则忽略它。 Optimizer 这是一个可选的、可调用的参数,在需要时会被调用。当 lambda 值为 none 时,此优化器用于查找最小化对数函数值的 lambda 值。 示例在此示例中,我们将采用非正态分布的数据集,然后将其转换为正态分布的数据集。 输出  说明 在上面的代码中,我们首先导入了文件中所需的模块,如 numpy、scipy、matplotlib 和 seaborn 来绘制曲线。现在,借助 numpy 的 random 函数,我们创建了 1200 个数据点的随机数据集。现在我们使用 boxcox() 函数,它将数据集作为参数,并返回变换后的数据集和 lambda 值。 现在,使用 histplot() 函数,我们绘制了原始数据集的曲线和变换后的数据集。histplot() 函数将数据集作为参数,并且还有许多其他属性,如 color、linewidth 等,它们定义了曲线的规格。现在,使用 show() 函数,我们显示了变换前和 boxcox 变换后的曲线。 对于上述随机数据集,我们得到的 lambda 值为 0.2872,接近于 0.28。 因此,在数据集中,新值将根据此公式计算: New Value = (Old Value^0.2872 -1)/0.2872 |
本文将讨论使用各种方法在 Python 中查找多个集合的对称差的问题。Python 中的集合 在 Python 中,集合是括在花括号 {} 中的无序、可变的唯一元素集合。集合中的每个元素都必须是可哈希的,这意味着...
7 分钟阅读
基础/必备知识简介:字典是 Python 中可用的数据类型之一。如果您熟悉集合和列表,那么字典就是另一种数据存储方式。从正式定义来看,字典是存储在...中的无序数据集合。
阅读 3 分钟
Python 的 random 模块允许生成随机数。生成的数字是伪随机数的序列,它们基于使用的函数。random 模块中有不同类型的函数用于生成随机数,例如 random.random()、random.randint()、random.choice()、random.randrange(start, stop,...
阅读 6 分钟
无论是哪种编程语言,参数(Arguments)和形参(Parameters)这两个词都会给程序员带来很多困惑。有时,这两个词会互换使用,但实际上,它们有两个不同但相似的含义。本教程解释了这两个词之间的区别以及...
阅读 6 分钟
两个字符串之间的“编辑距离”是将一个字符串转换为另一个字符串所需的最少操作数(插入、删除和替换)。此概念用于各种应用程序,例如拼写纠正、DNA 序列比对等。例如,字符串之间的编辑距离...
阅读 4 分钟
这是面试中最常被问到的编程问题。我们可以使用不同的方法在 Python 中反转整数。在这里,我们将编写一个程序,该程序接受输入的数字并将其反转。让我们了解以下反转整数的方法。使用 while...
阅读 3 分钟
简介 return 用于从函数返回一个值。用户只能在函数中使用 return 语句。它不能在 Python 函数之外使用。一个 return 语句包括 return 关键字和将在执行后返回的值...
阅读 3 分钟
严肃的软件开发需要性能优化。在优化应用程序性能时,我们无法回避性能分析器。性能分析器通过监控生产服务器或跟踪方法调用的频率和持续时间来进行全方位的分析。以下教程将介绍使用Python的基础知识...
阅读 17 分钟
os.path.basename() 是 Python os.path 模块中的一个方法,它返回文件路径的基本名称。基本名称是路径的最后一个组件,在剥离所有父目录和扩展信息之后。例如,如果路径是 /home/user/Documents/myfile.txt,则基本名称是...
阅读 3 分钟
scipy.stats.lognorm() 描述了对数正态连续随机变量。它是继承自通用方法的 rv_continuous 类的一个实例。它通过添加特定于此分布的详细信息来完善这些方法。给出对数正态分布的概率密度函数由下式给出:概率密度函数...
阅读 3 分钟
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
