Python 中的梯度下降优化器2025年3月17日 | 阅读 8 分钟 梯度下降使用迭代算法来找到模型的最佳参数。其主要目标是通过找到该函数的参数值来最小化给定的函数。这些被称为最优参数。我们可以使用梯度下降来处理任何维度的函数,例如一维、二维或三维。在本教程中,我们将重点关注使用梯度下降算法确定众所周知的线性回归方程的理想参数。
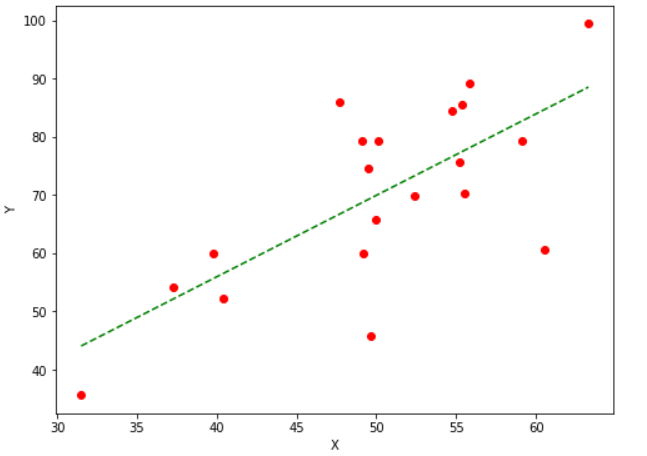
现在我们知道了算法所需的参数。为了完全理解梯度下降的工作原理,让我们将这些参数与算法进行映射,并手动处理一个示例。让我们以抛物线方程 y = 4x2 为例。通过将这些值代入函数,可以看到当 x = 0 时,即 x = 0, y = 0 时,该抛物线函数最低。因此,我们的抛物线函数 y = 4x2 的局部最小值在 x = 0 处。现在让我们看看梯度下降优化器的算法以及如何使用它来找到我们抛物线函数的局部最小值。 梯度下降算法该算法在一个方向上工作,该方向基于当前位置处函数梯度负值的比例(沿梯度相反方向前进),以找到任何函数的局部最小值。梯度上升是一种通过以与函数梯度正值成比例的步长(沿梯度方向移动)来达到函数局部最大值的方法。 重复此块,直到收敛到所需值。   步骤 1:我们首先需要初始化所有重要参数。然后,我们必须为我们的抛物线函数 y = 4x2 推导出梯度函数。这是一个基本推导。4x2 的导数是 2x,因此导数将是 dy/dx = 8x。 x0 = 4 (x 的随机值) learning_rate = 0.02(这将决定算法为达到局部最小值而采取的步长) gradient = 步骤 2:例如,我们将执行三次梯度下降函数迭代。 对于每次迭代,我们必须根据前一次迭代的梯度下降值更新 x 的值。 第一次迭代 x1 = x0 - (learning_rate * gradient_equation) x1 = 4 - (0.02 * (8 * 4)) x1 = 4 - 0.64 x1 = 3.36 第二次迭代 x2 = x1 - (learning_rate * gradient_equation) x2 = 3.36 - (0.02 * (8 * 3.36)) x2 = 3.36 - 0.54 x2 = 2.82 第三次迭代 x3 = x2 - (learning_rate * gradient) x3 = 2.82 - (0.02 * (8 * 2.82)) x3 = 2.82 - 0.45 x3 = 2.37 从这三次梯度下降迭代中,我们可以看到 x 在每一步都在下降,并且通过继续进行梯度下降算法的更多迭代,它将逐渐收敛到 0,这是所需的值。下一个问题是算法需要多少次迭代才能收敛到给定函数的局部最小值? 我们可以设置一个阈值。这是两个 x 值之间的差,即当前值和前一个值。当这个差值小于阈值时,函数将停止迭代。我们将梯度下降应用于机器学习和深度学习模型的成本函数。其目的是最小化该成本函数。现在我们知道了梯度下降的幕后工作原理。让我们来看看它在 Python 中的实现。如前所述,我们将最小化线性回归模型的成本函数并找到最佳拟合线。在这种情况下,我们的参数将是 w 和 b。 预测函数线性回归算法中的成本函数是直线的方程,即方程 因此,预测函数将是 这里,x 用于自变量 y 用于因变量 w 用于与自变量相关的权重 e 用于误差 成本函数大多数机器学习模型都会进行某种预测或分类。在两种情况下,模型都会给出一些输出值。我们将这些预测值与我们拥有的观测值进行比较。模型中的损失定义为这两个值之间的差异,即预测值和观测值。对于线性回归,我们使用均方误差公式来计算损失。均方误差是通过找到观测值和预测值之间平方差的平均值来计算的。成本函数的方程如下所示。  这里,n 是样本数量。Y 是预测值,y 是观测值。 偏导数(梯度) 现在我们将计算成本函数相对于权重和误差项的偏导数。结果是   参数更新 参数将使用我们之前使用的公式进行更新。通过将学习率与其梯度相乘的结果减去参数。   在 Python 中实现梯度下降为了实现上述算法,我们将定义两个函数。一个将使用上述成本函数返回成本值。该函数将以因变量的观测值和预测值作为参数。第二个函数将是实现梯度下降算法的函数。该函数将以自变量和因变量作为输入参数,并返回线性回归方程的权重和误差参数的最优值。 因此,它将为我们的数据提供最佳拟合线。我们可以调整梯度下降函数的参数,如迭代次数、学习率和停止阈值,使其更有效。为了实现这些函数,我们将创建自己的数据。我们已经取了一些近似线性相关的随机值。 使用梯度下降函数,我们将找到线性回归模型方程的最优参数,以找到此数据的最佳拟合线。迭代次数指定函数更新权重和误差值的次数;停止阈值是任何两个连续迭代中成本或损失值的变化的阈值或最小值。 代码 输出 At iteration 1: The value of cost: 4490.368112564136, weight: 0.7732901495653765, and the error is: 0.023058581526390003 At iteration 2: The value of cost: 1131.6506097576817, weight: 1.0973277566276178, and the error is: 0.02933947690034616 At iteration 3: The value of cost: 353.6864536509919, weight: 1.2532789421408856, and the error is: 0.0323584432495475 At iteration 4: The value of cost: 173.49022435062597, weight: 1.3283343812503887, and the error is: 0.033807525620796475 At iteration 5: The value of cost: 131.75220717474858, weight: 1.3644567422091003, and the error is: 0.03450106252964878 At iteration 6: The value of cost: 122.08462343134752, weight: 1.3818415966647506, and the error is: 0.03483097452170135 At iteration 7: The value of cost: 119.84536542439749, weight: 1.3902085628198768, and the error is: 0.034985883049982396 At iteration 8: The value of cost: 119.32669605130852, weight: 1.394235447257572, and the error is: 0.03505656685253503 At iteration 9: The value of cost: 119.20655864249093, weight: 1.3961735600573946, and the error is: 0.03508671544159867 At iteration 10: The value of cost: 119.17873134396095, weight: 1.3971063998600626, and the error is: 0.03509735547518664 At iteration 11: The value of cost: 119.17228540809819, weight: 1.397555427176545, and the error is: 0.03509860655236391 At iteration 12: The value of cost: 119.170791938096, weight: 1.3977716077711553, and the error is: 0.0350953389803933 At iteration 13: The value of cost: 119.17044558479306, weight: 1.3978757251232417, and the error is: 0.03508989671506608 At iteration 14: The value of cost: 119.17036493281425, weight: 1.397925909268681, and the error is: 0.035083407843062374 At iteration 15: The value of cost: 119.17034582400478, weight: 1.3979501367245375, and the error is: 0.035076415283989484 At iteration 16: The value of cost: 119.1703409701581, weight: 1.3979618718813835, and the error is: 0.035069180331332335 At iteration 17: The value of cost: 119.17033941812645, weight: 1.3979675948100971, and the error is: 0.0350618287390411 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India

 (梯度函数的计算)
(梯度函数的计算)