使用 Python 预测网约车费用2025年03月17日 | 阅读 9 分钟 出租车服务市场最近蓬勃发展,预计很快将有实质性扩张。涌现了许多公司来满足日益增长的乘车需求。然而,一些公司会为相同的行程收取更高的费用。即使成本本可以更低,但客户被迫支付过高的费用。主要目标是在预订出租车之前预测行程费用,以保持透明度和防止不公平的做法。 项目倡议
 美国第一个揭示 Lyft、Uber 和 Via 等公司详细的网约车统计数据的城市是芝加哥。这些信息于 2019 年 4 月首次公开,涉及自 2018 年 11 月开始的行程。行程、驾驶员和车辆数据库可以提供关于网约车公司定价策略的信息,以及对乘客行为的洞察。 关于定价(路透社-Uber 司机提高票价)和乘客行为(网约车数据)的一些文章。路透社的调查表明,共享行程的涨价主要影响芝加哥的低收入社区。与此同时,Storybench 的研究发现,行程通常集中在夜间通勤高峰和“夜生活”时段。在这些背景下,我正在努力开发预测网约车价格的人工智能模型。 数据集行程数据中包含了每次行程的详细信息,例如开始时间、结束时间、行驶距离、起点和终点等。您可以在在线资源中找到更详细的数据说明和数据来源。 芝加哥进行了许多数据修改,包括剔除人口普查区(Census Tracts)并将时间四舍五入到最近的 15 分钟。每趟行程的费用增加 2.50 美元,小费增加 1 美元。建模数据包含超过 700 万行,由 2019 年 12 月进行的行程组成。
天气数据芝加哥 2019 年 12 月的天气信息来自 NOAA(国家环境信息中心),包括降水量、温度、每小时能见度、每小时风向和每小时风速。为了简化,所有关于芝加哥的信息都从位于奥黑尔国际机场的一个气象站收集。 数据整理由于天气数据的时间间隔不规律,必须将数据重新配置为 15 分钟均匀间隔的时间序列,然后才能与行程日期结合。以下是一些可以使数据均匀间隔的代码。 行程的开始和结束时间被输入 RStudio 作为因子,上午和下午的时间以 12 小时制表示。这些必须转换为具有本地时区和 24 小时格式的日期。对于行程,我们还定义了骑行日、小时、每周的星期几和日期的变量。 源代码片段 输出:填补缺失值后,天气数据如下所示
可视化为了确保没有错误、数据缺失等,我们倾向于先可视化完整数据集。skimr、visdat 和 inspectdf 这三个程序非常有用。所有这三个包都提供了广泛的工具来显示您的数据和底层因子分布。 源代码片段 输出  源代码片段 输出  按一天中的小时可视化行程我们想看到一周内(周、天或一天中的时间)两个级别的行程。下图显示了一周中每天每小时的行程次数。 具体来说,therides.chicago_citydata 数据框通过管道(%>%)传递给 ggplot2 函数,以创建直方图,然后按一周中的天数分面,以显示每天每小时的行程细分。 源代码片段 输出  下图显示了在不同行程时长下给出的小费。我们可以使用 dplyr::sample_frac() 函数对数据进行采样,以获得一个更易于管理的数据集。我们将这些数据按两个感兴趣的变量(tipper 和 ride_category1)分组,然后计算行程时长(mean_tour_mins1)的平均值,以便在这些组之间进行更易于解释的可视化。 源代码片段 输出  鼓励乘客给小费是为司机带来收入的另一个来源。目前,不给小费的情况比给小费更常见,了解影响小费行为的指标可能很有趣。 机器学习模型我们评估了三个著名的基于树的模型:模型名称 - 随机森林,模型名称 - 梯度提升,模型名称 - XGBoost。下面是每个模型设置的一些代码片段,以及对每个模型的简要概述。 1. 随机森林一组决策树被称为随机森林。每个决策树都使用数据集的随机样本进行训练。然后,使用集成技术,通过对树的预测进行平均来从整个森林中进行预测。 源代码片段 2. 梯度提升机另一个基于决策树的集成技术是 GBM。通过依次添加树来尝试提高集成的理论性能。 源代码片段 3. XGBoost另一种集成方法是 XGBoost,它采用基于决策树的增强梯度框架。由于 XGBoost 包含许多复杂参数,因此在使用 XGBoost 时,调整超参数以选择最佳配置至关重要。 源代码片段 结果 这些基于树的模型具有强大的预测能力,从测试数据集中获得的 R 方值高于 95% 证明了这一点。行程里程和秒数是两个最关键的因素,这并不奇怪。天气相关数据的价值需要更高。在这种情况下使用未经修改的温度和降水量数据,例如没有考虑降水随时间的变化,可能会降低这些变量的预测能力。
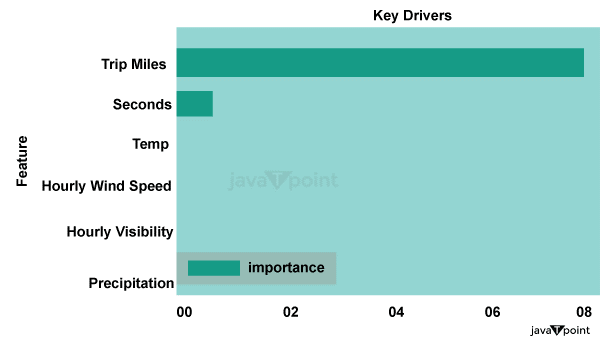 行程里程是可视化随机森林模型树时最重要的属性。  下一步我们观察到了什么?网约车行程通常发生在“夜生活”时段和清晨通勤时间。“星期五”和“星期六”的“夜生活”时段行程量尤其多,而“星期日”晚上则明显减少,这并不奇怪。 此外,行为差异会影响乘客对商品和司机的参与度。小费是其中一种行为。总的来说,小费并不常见,但一天中的时间比行程时长更能影响乘客给小费的意愿。较长的行程通常发生在每周初,这增加了乘客本周可能需要进行首次行程的可能性。 通过这些可视化,我们确定了芝加哥网约车数据中的时间、频率和行为之间的某些趋势和关联。下一步可能是制作一份静态报告、PPT 演示文稿或 PDF。理想情况下,我们可以开发一种干预措施,规划一项实验,并创建一个显示持续研究结果和实时数据的仪表板。 结论我们测试并评估了基于树的机器学习模型,以确定它们在预测网约车价格方面的表现。尽管这些模型具有出色的预测能力,但通过转换天气相关变量和使用更精确的位置数据,可以取得进一步的进展。 |
作为数据科学家和计算机科学家,我们即使没有意识到,也经常在日常工作中处理寻根算法。这些算法旨在定位特定值的近似值、局部/全局最大值或最小值。我们在订单中利用寻根算法...
阅读 16 分钟
字符串定义 Python 中的字符串是包含在引号中的字符序列。字符串是用于表示文本的基本数据类型。它们可以使用单引号(')、双引号(")或三引号(''' 或 """,用于多行字符串)来定义。在 Python 语言中...
11 分钟阅读
?字典是 Python 中键值对的集合。字典的键可用于访问其值。但是,有时您希望提取键值对并将其分配给变量。这就是字典解包的作用。要解包一个...
阅读 2 分钟
Python是一种高级编程语言,广泛用于数据科学、机器学习和Web开发。数据科学中一个常见的操作是将浮点值四舍五入到两位小数。在处理金融数据或任何其他数字时,此操作很有用...
阅读 3 分钟
在 Python 中实现 Kruskal 算法 Kruskal 算法可用于查找加权无向图的最小生成树。在所有可能的生成树中,最小生成树是跨越图中所有顶点的且总权重最低的树。该算法通过对...进行排序来工作
阅读 8 分钟
在本教程中,我们将学习一些操作字符串的酷操作。我们将看到如何以 Python 风格操作字符串。字符串是每个 Python 程序员都使用的基本且必不可少的数据结构。在 Python 中,字符串是一个序列...
5 分钟阅读
当我们编写大型脚本或多行代码时,内存管理应该是我们的首要任务。因此,除了良好的编程知识外,我们还应充分了解如何高效地处理内存。Python 中有许多函数可以获取大小...
阅读 3 分钟
在接下来的教程中,我们将了解 Ansible 及其优点以及如何使用它。Ansible 简介 Ansible 是一个开源平台或自动化工具,用于执行 IT 任务,如部署应用程序、管理配置、编排服务内部通信和资源调配。自动化是关键...
阅读 4 分钟
? 在 Python 中,“NaN”代表“非数字”,是一个特殊值,用于表示缺失或未定义的数值数据。它是 IEEE(电气和电子工程师协会)浮点算术标准定义的一个特殊值。它通常用于表示...
阅读 3 分钟
Python 和 C++ 是两种流行的编程语言,它们具有不同的优点和缺点。Python 以其简单易用而闻名,而 C++ 以其性能和低级功能而闻名。在某些情况下,将 Python 代码转换为 C++ 可能需要,例如,...
阅读 4 分钟
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
