Python 中的 DBSCAN 算法2025年03月17日 | 阅读 9 分钟 在本教程中,我们将学习如何在 Python 中实现和使用 DBSCAN 算法。 DBSCAN,即基于密度空间聚类应用(Density-Based Spatial Clustering of Applications with Noise),是一种聚类算法,于 1996 年首次提出,并于 2014 年荣获“测试之选”奖。DBSCAN 在数据挖掘会议 KDD 上获得了“测试之选”奖。在这里我们不会深入学习 DBSCAN 算法本身,而只讨论其在 Python 中的实现。但要理解 DBSCAN 算法的实现,我们至少需要对其有一个基本概念。因此,如果您不知道 DBSCAN 算法是什么或它是如何工作的,建议您先学习 DBSCAN 算法及其工作原理。 Python 中 DBSCAN 算法的实现在本节中,我们将进行 DBSCAN 算法的实现操作,并分步骤进行,以便于理解和学习。我们将使用一个数据集在此实现过程中执行各种操作(包括 DBSCAN 算法中的操作)。在开始实现过程之前,我们应该满足实现 Python 程序中 DBSCAN 算法的先决条件。 实现 DBSCAN 算法的先决条件在本节中,在继续进行 DBSCAN 算法的实现部分之前,我们需要满足以下先决条件: 1. Numpy 库:我们应该确保我们的系统已安装最新版本的 numpy 库,因为我们将使用 numpy 库的函数来处理我们在实现过程中使用的数据集。如果我们的系统没有 numpy 库或之前没有安装,我们可以在设备上的命令提示符终端中使用以下命令进行安装:  当我们按下回车键时,numpy 库将开始在我们的系统中安装。  过一段时间后,我们会看到 numpy 库已成功安装在我们的系统中(这里,我们的系统中已经存在 numpy 库)。 2. Panda 库:与 numpy 库一样,panda 库也是我们系统必需的库,如果我们的系统没有,我们可以使用以下命令在命令提示符终端中使用 pip 安装程序进行安装: 3. Matplotlib 库:在 DBSCAN 算法的实现过程中,它也是一个重要的库,因为这个库的函数将帮助我们显示数据集的结果。如果我们的系统没有 matplotlib 库,我们可以在命令提示符终端中使用以下命令使用 pip 安装程序进行安装: 4. Sklearn 库:在执行 DBSCAN 算法的实现操作时,Sklearn 库将是主要的必需品之一,因为我们需要从 Sklearn 库本身导入各种模块到程序中,例如预处理、分解等。因此,我们应该确保我们的系统存在 Sklearn 库,或者如果我们的系统没有,我们可以使用以下命令在命令提示符终端中使用 pip 安装程序进行安装: 5. 最后但同样重要的是,我们应该了解 DBSCAN 算法(它是什么以及它是如何工作的),如我们之前所讨论的,以便我们能够轻松理解它在 Python 中的实现。 在我们继续之前,我们应该确保我们已经满足了我们上面列出的所有先决条件,这样我们在遵循实现步骤时就不会遇到任何问题。 DBSCAN 算法的实现步骤现在,我们将在 Python 中实现 DBSCAN 算法。但如前所述,我们将分步进行,这样实现部分就不会过于复杂,我们可以很容易地理解它。为了在 Python 程序中实现 DBSCAN 算法及其逻辑,我们需要遵循以下步骤: 步骤 1:导入所有必需的库 首先,也是最重要的,我们需要导入我们在先决条件部分安装的所有必需库,以便在实现 DBSCAN 算法时可以使用它们的函数。 在这里,我们首先在程序中导入了所有必需的库或库模块。 步骤 2:加载数据 在此步骤中,我们需要加载数据,我们可以通过导入或加载(DBSCAN 算法需要处理的)数据集来完成。要将数据集加载到程序中,我们将使用 **read.csv()** 函数的 panda 库,并打印数据集中的信息,如下所示: 输出 BALANCE BALANCE_FREQUENCY ... PRC_FULL_PAYMENT TENURE 0 40.900749 0.818182 ... 0.000000 12 1 3202.467416 0.909091 ... 0.222222 12 2 2495.148862 1.000000 ... 0.000000 12 3 1666.670542 0.636364 ... 0.000000 12 4 817.714335 1.000000 ... 0.000000 12 [5 rows x 17 columns] 当我们运行程序时,上述输出中的数据将被打印出来,我们将处理从加载的数据集中获取的数据。 步骤 3:数据预处理 现在,在此步骤中,我们将使用 Sklearn 库的预处理模块中的函数开始对数据集进行数据预处理。在用 Sklearn 库函数进行数据预处理时,我们需要使用以下技术: 步骤 4:降低数据维度 在此步骤中,我们将降低缩放和标准化数据的维度,以便在程序中轻松可视化数据。我们需要按照以下方式使用 PCA 函数来转换数据并降低其维度: 输出 C1 C2 0 -0.489949 -0.679976 1 -0.519099 0.544828 2 0.330633 0.268877 3 -0.481656 -0.097610 4 -0.563512 -0.482506 正如我们在输出中看到的,我们使用 PCA 将标准化数据转换成了两个分量,即两列(我们可以在输出中看到它们)。之后,我们使用 panda 库的 **dataframe()** 函数从转换后的数据创建了数据框。 步骤 5:构建聚类模型 现在,这是实现中最重要的一步,因为在这里我们需要构建数据的聚类模型(我们正在对其进行操作),我们可以使用 Sklearn 库的 DBSCAN 函数来实现,如下所示: 步骤 6:可视化聚类模型 输出   正如我们在输出中看到的,我们使用数据集的数据点绘制了图形,并通过用不同颜色标记数据点来可视化聚类。 步骤 7:调整参数 在此步骤中,我们将通过更改我们在 DBSCAN 函数中之前给出的参数来调整模块的参数,如下所示: 步骤 8:可视化更改 现在,在调整了我们创建的聚类模型的参数后,我们将通过用不同颜色标记数据集中的数据点来可视化聚类中出现的更改,就像我们之前所做的那样。 输出  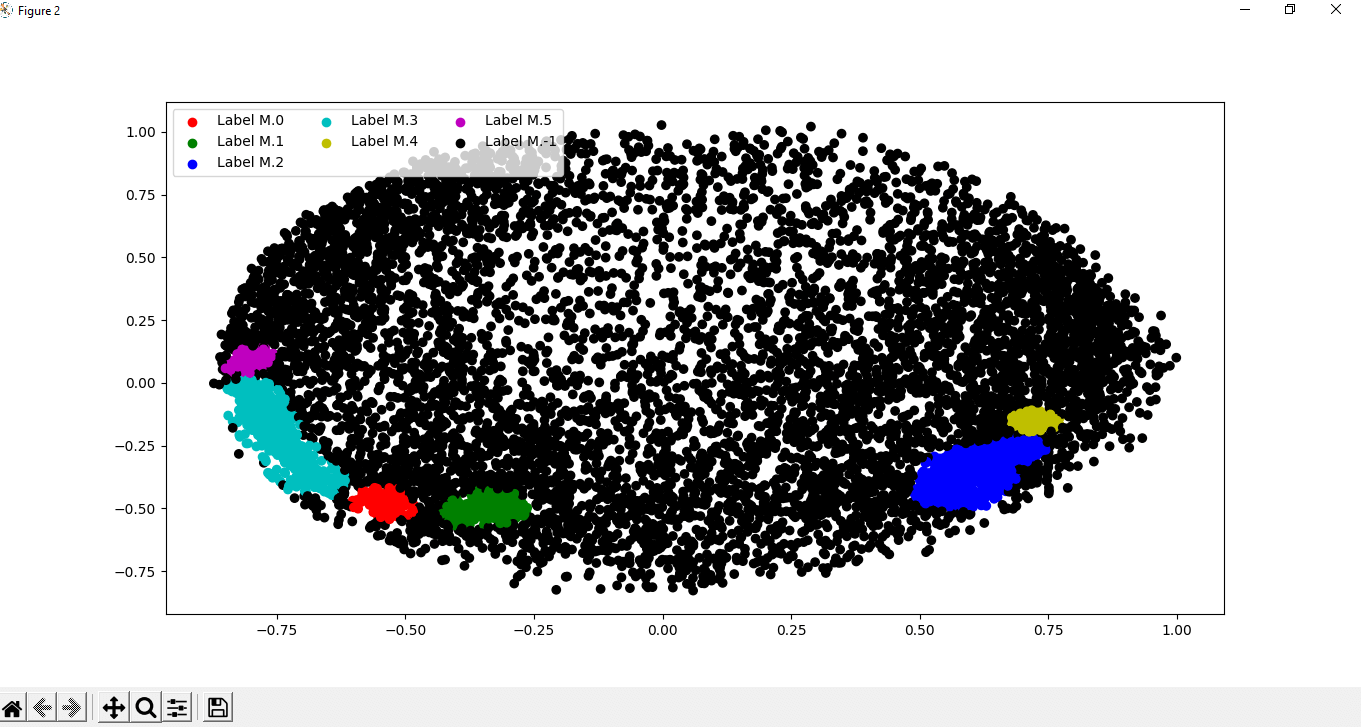 通过查看输出,我们可以清楚地观察到通过调整 DBSCAN 函数的参数而发生的聚类散点图的变化。当我们观察到这些变化时,我们还可以了解 DBSCAN 算法是如何工作的,以及它如何有助于可视化数据集中存在的聚类散点图。 |
障碍对象允许一组线程在继续执行之前相互等待。它对于需要按特定顺序执行的任务,或需要同步以避免竞争条件的任务非常有用。它们用于...
阅读 3 分钟
在本文中,我们讨论了。计数器是一个跟踪相同值添加频率的字段。Python Counter 优雅是 Collections 模块的一部分,也是 Dictionary 的子类。作为输入传递的列表或字符串将返回字典形式的输出,...
阅读 3 分钟
名片仍然是各种专业场合中进行人际交往和交换联系信息的重要工具。然而,手动处理和整理各种名片中的信息可能耗时且容易出错。为了克服这些挑战,我们将探讨...
7 分钟阅读
Python是一种可以服务于不同目的的编程语言,用它几乎可以做任何事情。Python也可以用于开发游戏。开发游戏是学习如何编写程序的好方法。在下面的教程中,我们将学习如何...
阅读 13 分钟
任何使用 Python 编程语言的开发人员都应该优先编写简短、高效、清晰且可读的代码行。为了使事情更容易,Python 提供了三元运算符,它提供了一种更短、更方便的编写条件...
阅读 6 分钟
os.walk() 是 Python 的 OS 模块中的一个函数,它通过自顶向下或自底向上遍历目录树来生成目录树中的文件名。它可以用于在目录层次结构中搜索文件,或对目录中的所有文件执行操作。
阅读 4 分钟
称为天线的设备被制造用来传输和接收无线电波。它们被用于许多不同的系统,包括雷达和导航系统以及无线通信。天线是任何无线通信系统的重要组成部分,其设计和性能对于...
7 分钟阅读
? 使用 Python 内置的 type() 方法,您可以确定变量的类型。type() 函数将变量的数据类型作为字符串返回。以下是使用 type() 函数的示例:x = 5 print(type(x)) 输出:<class 'int'> 在此示例中,我们创建了一个变量 x 并赋值...
阅读 3 分钟
介绍 一种用于计算机科学的复杂算法方法,称为所有后缀的 Trie,它允许我们快速在文本中搜索特定的模式。为了实现快速模式匹配,这种方法将 Trie(前缀树)数据结构的思想与后缀相结合。一个...
阅读 4 分钟
Python 字典是一种数据结构,包含所有以键值对形式存在的元素。每个键值对将键映射到其关联的值。因此,它也被称为 Python 字典的关联数组。字典的所有元素都包含在花括号内...
阅读9分钟
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
