二元决策树2025年3月17日 | 阅读 3 分钟 二叉决策树是一种决策图,它遵循从根节点开始并以叶节点结束的顺序。叶节点代表我们希望通过决策实现的结果。它直接受到二叉树的启发。由于二叉树中每个节点最多可以有两个节点,同样,在每一步中,我们有一个或两个步骤,我们将在其中选择一个。 当数据量很大且我们希望在每一步处理后获得结果时,它是一种用于机器学习的决策算法。 如果没有适当的约束,决策树可能会扩展,直到每个节点只包含一个样本(或非常少的样本)。由于这种情况,模型变得过拟合并失去了准确泛化的能力。通过使用一致的测试集、交叉验证和最大允许深度可以避免这个问题。类平衡是另一个需要考虑的关键因素。当一个类占主导地位时,决策树可能会产生不准确的结果,因为它们对不平衡的类很敏感。可以使用重采样技术之一,或 scikit-learn 实现提供的类权重选项来缓解此问题。通过避免偏差,可以按比例惩罚占主导地位的类。 假设在一个数据集中,我们有 n 个数据点,每个点有 m 个特征。那么决策树可能看起来像这样,其中 t 是阈值  单分裂节点因此,在二叉决策树中,每个节点都应该以这样一种方式选择,即我们为该节点选择的特征应该能够以最佳方式分离数据。如果我们选择这样的节点,它会减少步骤数,并且我们可以在更少的步骤和更低的复杂性下获得目标。 在现实生活中,选择或找到一个能最小化二叉决策树结构的特征是非常困难的。树的结构取决于我们选择的特征和阈值。 例如:我们有一个学生班级,所有男生都有黑发,女生都有绿发。黑发的学生有不同的长度,红发的学生也有不同的长度。如果我们的目标是获取黑发和绿发的数据组成,那么一个简单的二叉决策树可能看起来像这样  在上面的树中,我们根据头发长度进行划分,然后根据发色进行划分。由于我们不需要根据头发长度进行分离,所以这被称为杂质。杂质节点被添加到树中,这不必要地使结构更大更复杂。如果杂质节点在目标节点下方,则没有问题。 所以我们可以得到上面例子中的最优树,像这样 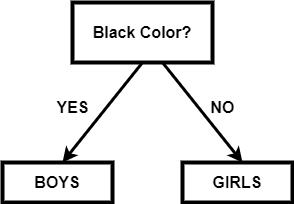 如果我们需要关于头发长度的数据,那么这个节点可以很容易地添加到叶节点下方。 注意:所以,每个节点的选择可以用以下形式表示在上面的等式中,我们有两个值,其中 i 表示我们想要分割的数据集的索引。在根节点中,我们将有一个完整的数据集,所以 i 将为零,在后续步骤中,数据集将减少。tk 表示我们分割数据集的阈值。所以我们在选择阈值时必须非常小心,因为阈值决定了树的结构。如果我们的阈值不好,那么我们可能需要一棵很长的树才能达到目标。 我们可以测量总杂质,我们的目标将是尽快减少总杂质以达到期望的节点。 我们可以通过以下公式获得总杂质度量  这里 D 代表我们正在处理的完整数据集。Dleft 和 Dright 代表根据阈值分割后创建的左节点和右节点数据集。 I 代表节点的总杂质度量。 下一个主题C++ 中布尔值转字符串 |
使用 C++ 中的 accumulate,我们可以高效地查找数组的总和 () 数组是一个线性数据结构,包含内存连续流中的相同数据类型元素。数组中所有元素的总和称为数组总和。C++ 中有几种方法……
阅读 3 分钟
数组是 C++ 中的重要数据结构,因为它们允许在单个变量中存储和操作多个值。它们用于存储一组元素,这些元素都具有相同的数据类型,并且存储在连续的内存中...
阅读 4 分钟
C++ 中的实际参数和形式参数分别指传递给函数和从函数接收的值。函数定义指定其形式参数的数量、类型和名称,而函数调用提供相应的实际参数。将实际参数与……匹配的过程。
阅读 3 分钟
foreach 循环用于快速迭代容器(数组、向量等)的元素,而无需进行初始化、测试或增量/减量。Foreach 循环通过对每个元素执行某项操作而不是执行 n 次操作来工作。尽管 C++ 中没有 foreach 循环,但...
阅读 4 分钟
C++ 编程语言的基础基于面向对象编程 (OOP) 的概念。由于 C++ 提供了清晰的结构,用户可以轻松开发和理解程序的概念。此外,由于函数是紧凑的代码片段,因此该概念已被......
阅读 4 分钟
在本文中,我们将讨论 C++ 和 JavaScript 之间的区别。但在讨论区别之前,我们必须了解 C++ 和 JavaScript 的优缺点。简介:C++:C++,或 CPP,是一种通用、静态类型、面向对象的编程语言。在 AT&T(美国)的贝尔实验室...
5 分钟阅读
在本文中,我们将讨论 C++ 中的游戏引擎,包括其历史、制作和不同方面。什么是游戏引擎?“游戏引擎”是指一组软件工具。它主要用于简化视频游戏的创建。这些引擎可以……
阅读 16 分钟
在 C++ 中,ungetc() 函数用于将字符推回输入流。此函数是标准输入/输出库的一部分,通常与文件输入流 (FILE* 流) 一起使用。它是标准输入/输出库的一部分,并且用于...
14 分钟阅读
介绍:C++ 面向对象编程的关键组件之一是数据隐藏,它使我们能够隐藏内部对象特性,例如数据成员,并禁止程序函数直接访问对象的内部表示、数据成员和成员函数。访问修饰符定义了限制...
11 分钟阅读
活动选择是一个组合优化问题。该问题可以表述如下:给定一组具有开始和结束时间的活动,选择一个人可以执行的最大数量的活动,假设一个人只能...
阅读 4 分钟
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India

