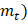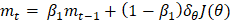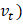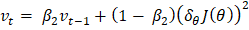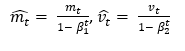深度学习中的 AdaGrad 优化器2025年8月11日 | 阅读 6 分钟 优化器在深度学习中起着至关重要的作用。它们通过更新神经网络每个输入相关的权重和偏差来减少损失函数的误差。在本文中,我们将探讨一种称为 Adagrad 优化器的优化技术,也称为自适应梯度算法。 理解 AdaGrad也称为自适应梯度算法,它是一种基于梯度的算法,可以在参数的基础上改进学习率。如果各种参数集在输出中没有改变,该算法会提供较小的更新。传统的梯度下降方法使用固定的学习率来优化权重,而这对于稀疏特征并不总是有效。稀疏特征的大多数值为零,并且存在大量缺失信息。 AdaGrad 专门设计用于处理这类数据,因为它适应数据的稀疏性,这使得学习重要属性变得容易。 为什么要使用 AdaGrad?AdaGrad 的最大潜力在于它通过调整学习率来处理稀疏数据。考虑一个只有少数特征(如 CGPA 或 IQ)具有非零值的数据集,而大多数其他特征的值为零,这会导致使用传统方法进行学习的过程缓慢。AdaGrad 根据梯度历史更新每个参数的学习率,这使其能够专注于有意义的值并忽略相关特征。 AdaGrad 的工作原理AdaGrad 使用不同的学习率来更新每个权重的参数。它通过将学习率除以其过去平方梯度的累积总和的平方根来更新每个参数,从而有效地降低了梯度较大的参数的学习率,使其能够专注于变化较小的特征。 公式如下: 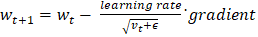 其中:
用于说明 AdaGrad 的示例考虑一个具有三列的数据集:IQ、CGPA 和就业套餐。对于非学生,IQ 和 CGPA 特征有时为零,这使得这些特征具有稀疏性。对于这些特征,AdaGrade 优化器从正常的学习率开始。但是,当 IQ 的梯度变为零时,它会自动降低学习率。这使得算法能够专注于 CGPA 和就业套餐,同时减少对 IQ 的关注。 AdGrad 在以下方面非常有效:
此外,在处理首选学习率恒定的问题时,使用 RMSProp 或 Adam 等变体可能会很有用。 AdaGrad 优化器的不同变体为了处理 AdaGrad 的问题,已经引入了 AdaGrad 优化器的各种版本 1. RMSProp(均方根传播)RMSProp 通过展示梯度平方的指数衰减平均值而不是使用总和来解决学习率消失的问题。这可以防止学习率过快地降低,从而使算法更适合训练。RMSProp 的更新公式如下: 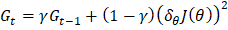 其中,
参数的更新规则是 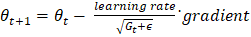 2. AdaDeltaAdaDelta 是 AdaGrad 的另一个改进版本,侧重于减少前向梯度的使用。它基于先前梯度的移动平均来改进学习率,并使用更稳定和改进的规则。 3. Adam(自适应矩估计)Adam 利用了 AdaGrad 和基于动量的方法的优势。它同时使用梯度移动平均和平方梯度来适应学习率。Adam 被广泛使用,因为它在大多数机器学习任务中提供了鲁棒性和有效的性能。 Adam 具有以下更新规则
参数更新 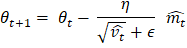 AdaGrad 优化器实现让我们使用 TensorFlow 和 PyTorch 库来实现 AdaGrad 优化器。 1. 使用 TensorFlow 实现在 TensorFlow 中,实现 Adagrad 更容易,因为它已包含在 API 中。下面是一个演示 AdaGrad 优化器的示例 代码 输出 Epoch 1/5 1875/1875 ━━━━━━━━━━━━━━━━━━━━ 7s 3ms/step - accuracy: 0.8180 - loss: 0.7198 Epoch 2/5 1875/1875 ━━━━━━━━━━━━━━━━━━━━ 6s 3ms/step - accuracy: 0.9190 - loss: 0.2882 Epoch 3/5 1875/1875 ━━━━━━━━━━━━━━━━━━━━ 11s 3ms/step - accuracy: 0.9305 - loss: 0.2530 Epoch 4/5 1875/1875 ━━━━━━━━━━━━━━━━━━━━ 6s 3ms/step - accuracy: 0.9388 - loss: 0.2207 Epoch 5/5 1875/1875 ━━━━━━━━━━━━━━━━━━━━ 11s 3ms/step - accuracy: 0.9441 - loss: 0.202 说明 在上面的代码中,
使用 PyTorch 实现 AdaGradPyTorch 提供了 torch.optim.AdaGrad 类,下面是展示 AdaGrad 实现的代码 代码 输出 100%|██████████| 9.91M/9.91M [00:00<00:00, 34.6MB/s] 100%|██████████| 28.9k/28.9k [00:00<00:00, 1.08MB/s] 100%|██████████| 1.65M/1.65M [00:00<00:00, 9.74MB/s] 100%|██████████| 4.54k/4.54k [00:00<00:00, 4.22MB/s] Epoch 1 finished Epoch 2 finished Epoch 3 finished Epoch 4 finished Epoch 5 finished 说明 在上面的代码中,数据使用 datasets.MNIST() 方法加载,图像使用 ToTensor() 方法转换为张量。在PyTorch 中,它接受张量作为输入,并使用 lambda() 函数来展平这些张量。批次加载器的使用是为了对数据进行混洗和分批。FeedForwardNet() 类定义了一个简单的网络,包含两个具有ReLU 函数的线性层,并使用 CrossEntropyLoss 来评估分类损失。为了改进训练数据,使用了 AdaGrad 优化器。 AdaGrad 的优点以下是 AdaGrad 优化器在深度学习中的一些主要优点
AdaGrad 的局限性以下是 AdaGrad 的主要缺点
AdaGrad 优化器的常见用途AdaGrad 提供了调整每个参数学习率的特殊能力,这使其在各种情况下都非常有效。
下一主题机器学习中的模式识别 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India

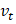 表示过去平方梯度的总和
表示过去平方梯度的总和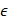 表示一个小的常数,用于防止除零错误。
表示一个小的常数,用于防止除零错误。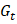 用于梯度
用于梯度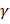 表示衰减因子(通常设置为 0.9)
表示衰减因子(通常设置为 0.9)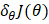 显示了梯度
显示了梯度