随机森林算法2025年3月17日 | 阅读 8 分钟 随机森林是一个流行的机器学习算法,属于监督学习技术。它可用于机器学习中的分类和回归问题。它基于集成学习的概念,集成学习是一个结合多个分类器来解决复杂问题并提高模型性能的过程。 顾名思义,“随机森林是一个分类器,它包含在给定数据集的各种子集上的多个决策树,并通过取平均值来提高该数据集的预测准确性。” 随机森林不依赖于单个决策树,而是从每棵树获取预测,并基于预测的多数票来预测最终输出。 森林中树的数量越多,准确性越高,并能防止过拟合问题。 下图解释了随机森林算法的工作原理  注意:要更好地理解随机森林算法,您应该了解决策树算法。随机森林的假设由于随机森林结合了多个树来预测数据集的类别,因此有些决策树可能预测正确输出,而有些则可能不正确。但总的来说,所有树都能预测正确的输出。因此,以下是改进随机森林分类器的两个假设
为什么使用随机森林?以下几点解释了为什么我们应该使用随机森林算法
随机森林算法如何工作?随机森林的工作分两个阶段:第一阶段是创建随机森林,结合 N 个决策树;第二阶段是为第一阶段创建的每棵树进行预测。 工作过程可以通过以下步骤和图解进行解释 步骤 1:从训练集中选择 K 个随机数据点。 步骤 2:构建与选定的数据点(子集)相关的决策树。 步骤 3:选择要构建的决策树数量 N。 步骤 4:重复步骤 1 和 2。 步骤 5:对于新的数据点,找到每棵决策树的预测,并将新的数据点分配给在多数投票中获胜的类别。 通过以下示例可以更好地理解算法的工作原理 示例:假设有一个数据集包含多个水果图像。因此,此数据集被提供给随机森林分类器。数据集被分成子集并提供给每棵决策树。在训练阶段,每棵决策树都会产生一个预测结果,当出现新的数据点时,随机森林分类器会根据多数结果预测最终决策。请看下图  随机森林的应用随机森林主要用于以下四个领域
随机森林的优点
随机森林的缺点
随机森林算法的 Python 实现现在我们将使用 Python 实现随机森林算法。为此,我们将使用与之前分类模型中使用的相同数据集“user_data.csv”。通过使用相同的数据集,我们可以将随机森林分类器与其他分类模型进行比较,例如决策树分类器、KNN、SVM、逻辑回归等。 实现步骤如下
1.数据预处理步骤以上是预处理步骤的代码 在上面的代码中,我们已经预处理了数据。我们加载了数据集,该数据集是  2.将随机森林算法拟合到训练集现在我们将随机森林算法拟合到训练集。为了拟合它,我们将从 sklearn.ensemble 库导入 RandomForestClassifier 类。代码如下 在上面的代码中,分类器对象接受以下参数
输出 RandomForestClassifier(bootstrap=True, class_weight=None, criterion='entropy',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=10,
n_jobs=None, oob_score=False, random_state=None,
verbose=0, warm_start=False)
3.预测测试集结果由于我们的模型已拟合到训练集,因此现在我们可以预测测试结果。为了预测,我们将创建一个新的预测向量 y_pred。代码如下 输出 预测向量如下  通过检查上面的预测向量和测试集的真实向量,我们可以确定分类器做出的错误预测。 4.创建混淆矩阵现在我们将创建混淆矩阵来确定正确和错误的预测。以下是代码 输出 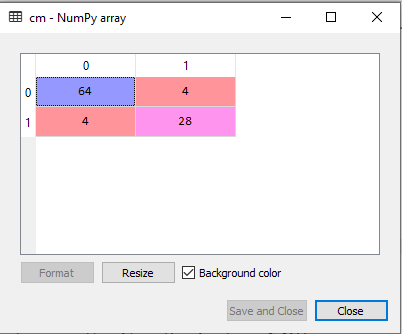 正如我们在上面的矩阵中看到的,有 4+4=8 个错误预测,而有 64+28=92 个正确预测。 5.可视化训练集结果在这里,我们将可视化训练集的结果。为了可视化训练集的结果,我们将绘制随机森林分类器的图。分类器将根据是否购买了 SUV 汽车的用户预测是或否,就像我们在逻辑回归中所做的那样。以下是代码 输出  上面的图像是随机森林分类器在训练集结果上工作的可视化结果。它与决策树分类器非常相似。每个数据点对应于 user_data 的每个用户,紫色和绿色区域是预测区域。紫色区域被分类为未购买 SUV 汽车的用户,绿色区域为购买了 SUV 的用户。 因此,在随机森林分类器中,我们使用了 10 棵树来预测“已购买”变量的“是”或“否”。分类器采用多数预测并提供结果。 6.可视化测试集结果现在我们将可视化测试集的结果。代码如下 输出  上面的图像是测试集的可视化结果。我们可以看到错误的预测(8 个)数量最少,没有过拟合问题。通过更改分类器中的树的数量,我们将得到不同的结果。 随机森林算法选择题练习1.在随机森林中,自助法的目的是什么?
答案 A) 创建多个决策树。 说明 自助法涉及通过对原始数据集进行有放回抽样来创建多个数据集,这些数据集用于训练随机森林中的各个决策树。 2.与单个决策树相比,随机森林如何减少过拟合?
答案 C) 通过平均多个决策树的预测。 说明 随机森林通过平均多个决策树的预测来减少过拟合,这有助于更好地泛化到未见过的数据。 3.在构建随机森林中的每个决策树时,使用随机特征选择的优点是什么?
答案 C) 它减少了各个决策树之间的相关性。 说明 随机特征选择有助于去相关决策树,从而产生更多样化的树集,并可能获得更好的性能。 4.随机森林如何处理数据集中的缺失值?
答案 D) 它用特征的平均值替换缺失值。 说明 随机森林可以通过在训练和预测期间用特征的平均值替换缺失值来处理缺失值。 5.以下关于随机森林算法的陈述哪一项是正确的?
答案 B) 它对特征缩放敏感。 说明 随机森林计算数据点之间的距离,因此对特征进行缩放以使其具有相似的范围很重要,以防止某些特征主导距离计算。 下一主题机器学习面试题 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
