机器学习中的森林覆盖类型预测2025年3月17日 | 阅读20分钟  在广阔多样的森林世界中,每一种植被类型都具有其独特的生态重要性。能够预测这些植被类型对于生态保护、自然资源管理以及加深我们对自然世界的理解至关重要。这正是机器学习发挥作用的地方。 眼前的任务是解密森林的秘密——根据各种环境特征预测特定区域的植被类型。机器学习算法是这项工作中现代的密码破解者,揭示了收集到的海量数据中隐藏的模式。这些覆盖类型可以是高大的云杉/冷杉树,也可以是耐寒的科鲁姆霍尔茨,每一种都在生态系统丰富的生物多样性中发挥着至关重要的作用。本质上,机器学习帮助我们揭示森林的奥秘,并为我们保护和管理这些重要的自然资源的努力做出贡献。 数据摘要研究区域包括位于科罗拉多州北部罗斯福国家森林的四个荒野地区。每个数据点代表一个 30m x 30m 的地块。任务涉及预测森林覆盖类型的整数分类,它可以属于七个类别之一: - 云杉/冷杉
- 黑松
- 黄松
- 棉白杨/柳树
- 白杨
- 花旗松
- 科鲁姆霍尔茨
训练数据集包含 15,120 个观测值,提供特征和 Cover_Type。另一方面,测试集仅包含特征,要求参与者预测测试集中 565,892 个观测值的 Cover_Type。 关键数据字段- 海拔: 以米为单位的高度测量值
- 坡向: 以度方位角表示方向的测量值
- 坡度: 以度表示坡度的测量值
- 距水文水平距离: 表示到最近水文特征的水平距离的测量值
- 距水文垂直距离: 表示到最近水文特征的垂直距离的测量值
- 距道路水平距离: 表示到最近道路的水平距离的测量值
- 山体阴影_上午9点,山体阴影_中午,山体阴影_下午3点: 表示夏至期间上午9点、中午和下午3点山体阴影指数的测量值
- 距火点水平距离: 表示到最近野火着火点的水平距离的测量值
- 荒野区域: 表示荒野区域存在(1)或不存在(0)的二进制列
- 土壤类型: 表示土壤类型存在(1)或不存在(0)的二进制列
- 覆盖类型: 表示森林覆盖类型(1-7)的名称
荒野区域分类如下 - 拉瓦荒野区域
- 尼奥塔荒野区域
- 科曼奇峰荒野区域
- 普德雷堡荒野区域
土壤类型为 - 大教堂家族 - 岩石露头复合体,极其多石。
- 瓦内特 - 拉塔克家族复合体,非常多石。
- 高山冰原土 - 岩石露头复合体,碎石多。
- 拉塔克家族 - 岩石露头复合体,碎石多。
- 瓦内特家族 - 岩石露头复合体,碎石多。
- 瓦内特 - 韦特莫尔家族 - 岩石露头复合体,多石。
- 哥特式家族。
- 主管 - 细枝家族复合体。
- 特劳特维尔家族 - 非常多石。
- 布尔瓦克 - 卡塔蒙特家族 - 岩石露头复合体,碎石多。
- 布尔瓦克 - 卡塔蒙特家族 - 岩石地复合体,碎石多。
- 勒高家族 - 岩石地复合体,多石。
- 卡塔蒙特家族 - 岩石地 - 布尔瓦克家族复合体,碎石多。
- 肥沃灰土 - 水土复合体。
- 未在美国林务局土壤和ELU调查中指定。
- 冰水土 - 寒带土复合体。
- 盖特维尤家族 - 冰水土复合体。
- 罗杰特家族,非常多石。
- 典型冰水土 - 泥炭土复合体。
- 典型冰水土 - 典型冰水土复合体。
- 典型冰水土 - 莱坎家族,冰碛母质复合体。
- 莱坎家族,冰碛母质,极其多石。
- 莱坎家族,冰碛母质 - 典型冰水土复合体。
- 莱坎家族,极其多石。
- 莱坎家族,温暖,极其多石。
- 花岗岩 - 卡塔蒙特家族复合体,非常多石。
- 莱坎家族,温暖 - 岩石露头复合体,极其多石。
- 莱坎家族 - 岩石露头复合体,极其多石。
- 科莫 - 勒高家族复合体,极其多石。
- 科莫家族 - 岩石地 - 勒高家族复合体,极其多石。
- 莱坎 - 卡塔蒙特家族复合体,极其多石。
- 卡塔蒙特家族 - 岩石露头 - 莱坎家族复合体,极其多石。
- 莱坎 - 卡塔蒙特家族 - 岩石露头复合体,极其多石。
- 冰积土 - 岩石地复合体,极其多石。
- 冰育土 - 岩石露头 - 冰水土复合体。
- 布罗斯家族 - 岩石地 - 冰育土复合体,极其多石。
- 岩石露头 - 冰育土 - 冰积土复合体,极其多石。
- 莱坎 - 莫兰家族 - 冰水土复合体,极其多石。
- 莫兰家族 - 冰积土 - 莱坎家族复合体,极其多石。
- 40 莫兰家族 - 冰积土 - 岩石地复合体,极其多石。
现在,我们将尝试建立一个可以预测森林覆盖类型的模型。 使用机器学习预测森林覆盖类型的 Python 代码它指的是数据集关键数值特征和属性的摘要或描述。 输出  很明显,有 15,120 个实例,每个实例有 55 个属性。由于维度与数据描述一致,我们可以说数据已成功加载 输出 
 所有属性的数据类型都已推断为 int64。 输出 





 注意到以下观察结果 - 所有属性的计数都一致为 15,120,因此没有属性存在缺失值。因此,所有行都可以被利用。
- “距水文垂直距离”中存在负值,这使得某些测试(如卡方检验)不适用。
- “荒野区域”和“土壤类型”都经过了独热编码。因此,它们可能可以转换回来用于特定分析。“Soil_Type7”和“Soil_Type15”属性可以排除,因为它们保持不变。
- 并非所有属性都具有相同的尺度,这意味着对于某些算法,可能需要重新缩放和标准化。
输出 
 在这里,接近零的值表示最小的偏度。此外,“土壤类型”中的几个属性表现出显著的偏度。纠正这种偏度可能会有利于某些算法。 输出  我们观察到每个类别都得到了同等程度的表示,表明不需要进行类别再平衡。 在这里,我们将就相关性和散点图与数据集进行交互。 相关性 输出  在这里,相关性提供了关于不同环境变量之间如何相互关联的见解, 散点图输出 

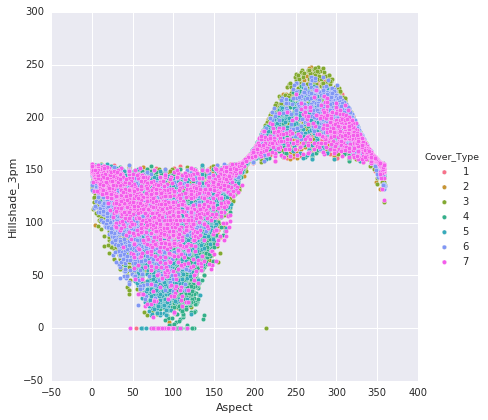



 以下是根据上述图表得出的要点 - 这些图表说明了数据点如何分类到各自的类别中。图表中类别的分布存在一些重叠。
- 山体阴影图案相互比较时呈现出吸引人的椭圆形。
- “坡向”和“山体阴影”属性共同创建了 S 形图案。
到水文的水平距离和垂直距离显示出几乎线性的关系。 现在,我们将用小提琴图可视化我们的数据,然后我们将对独热属性进行分组。 箱线图和密度图 输出 





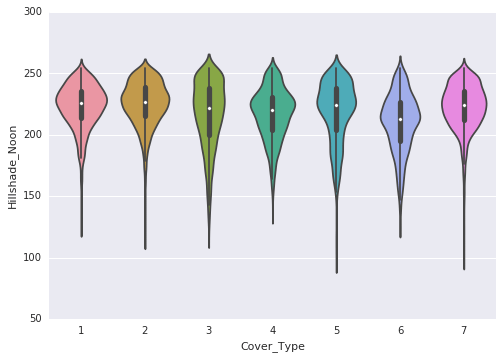

 以下是通过小提琴图得出的观察结果 - 海拔对大多数类别都表现出独特的分布。它与目标变量高度相关,使其成为一个重要属性。
- 坡向在几个类别中显示出多个正态分布。
- 到道路和水文的水平距离遵循相似的分布。
- 上午 9 点和中午的山体阴影表现出左偏。
- 下午 3 点的山体阴影遵循正态分布。
- 到水文的垂直距离存在大量零值。
- Wilderness_Area3 没有提供清晰的类别区分,因为它缺少值。然而,其他荒野区域为区分类别提供了一些潜力。
- 某些 Soil_Type 值,特别是 1、5、8、9、12、14 和 18-22,以及 25-30 和 35-40,由于在许多类别中缺失,有助于类别区分。
独热编码属性分组 输出 
 - 以下是我们从图中可以得出的结论
- 在 cover_type 4 中存在大量的 WildernessArea_4,表明存在很强的类别区分。
- WildernessArea_3 不提供显著的类别区分
- 土壤类型 1-6、10-14、17、22-23、29-33、35 和 38-40 对类别区分有显著贡献,因为它们在某些情况下计数显著偏高。
现在我们将删除不必要的列。 输出  以上是已删除的列。 在这里我们将执行以下操作 - 原始
- 删除缺失值或进行插补
- StandardScaler(标准缩放器)
- MinMaxScaler(最小-最大缩放器)
- Normalizer(归一化器)
这是机器学习数据预处理阶段的关键一步。它涉及从数据集中选择最相关和信息量最大的特征(变量或列)子集,同时丢弃不相关或冗余的特征。 输出 


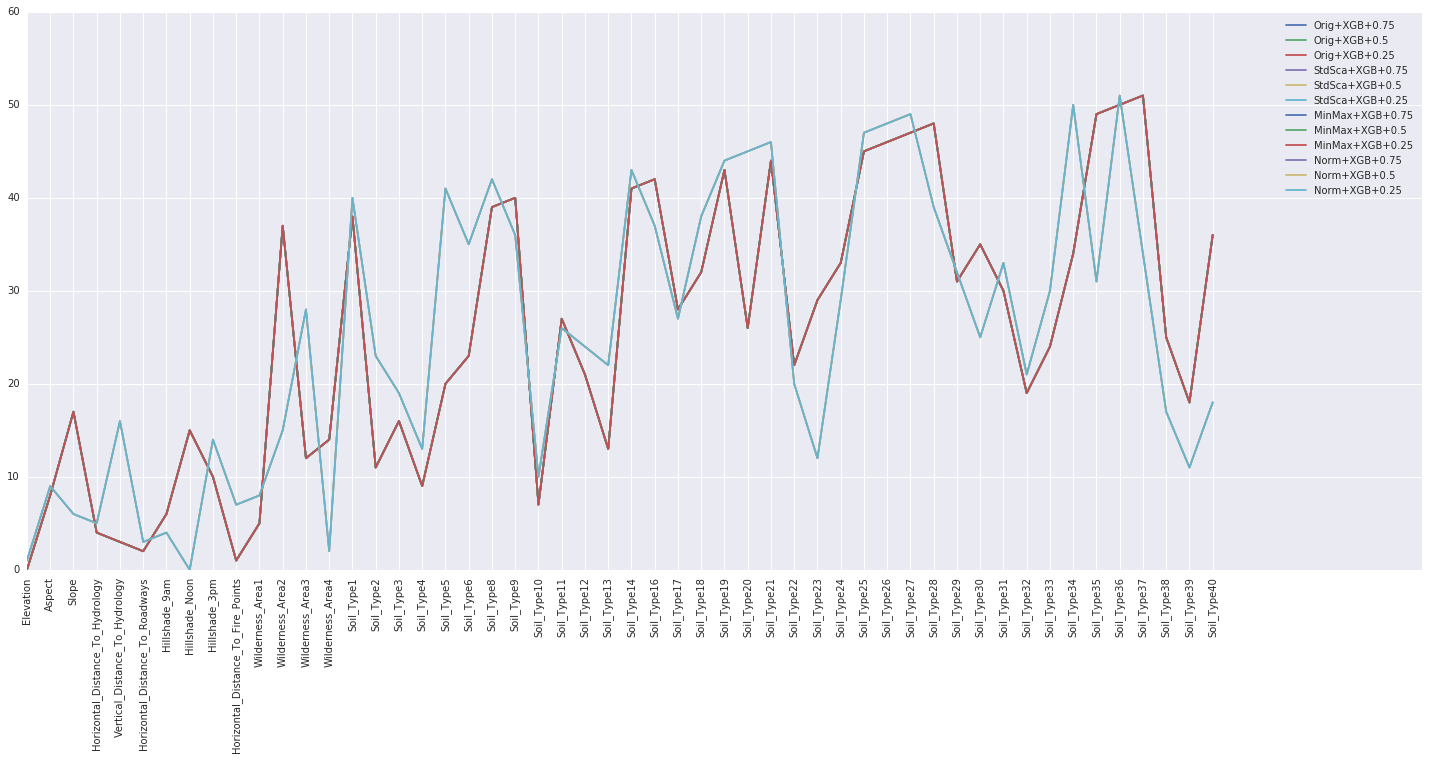 排名摘要是一份报告或列表,提供数据集中各个特征(变量)的重要性或排名信息。此摘要对于理解每个特征对机器学习任务的相关性和贡献,以及决定在预测模型中包含或排除哪些特征至关重要。 输出  基于中位数对特征进行排名根据特征的中位数对其进行排名是一种直接的特征选择方法。 输出 
 最高中位数(变异性最大) 最低中位数(变异性最小) 现在我们将根据中位数排名选择特征,因为它在其他特征选择方法中看起来是最好的情况。
模型我们将继续采用一系列机器学习算法。 01. 线性判别分析02. 逻辑回归03. KNN04. 朴素贝叶斯05. 决策树分类器06. 支持向量机07. 袋装决策树08. 随机森林分类器09. 极端随机树10. AdaBoost(提升)11. 梯度提升分类器12. 投票分类器13. XGBoost模型评估输出  以下是模型评估得出的观察结果 - 线性判别分析: 在不进行任何转换的情况下使用所有特征时,最高估计性能达到 65%。然而,MinMax 缩放和归一化技术的性能明显低于预期。
- 逻辑回归: 使用逻辑回归 (LR) 并在 C 值等于 100、考虑所有属性并对数据进行标准化的情况下,最高估计性能接近 67%。此外,性能倾向于随着 C 值的增加而提高。相反,归一化和 MinMax Scaler 方法的性能通常不尽如人意。
- KNN: 当 n_neighbors 设置为 1 且数据经过归一化时,最佳估计性能徘徊在 86% 左右。
- 朴素贝叶斯: 最高估计性能约为 64%。即使只使用 50% 的子集,原始数据集也优于所有朴素贝叶斯 (NB) 转换变体。
- 决策树分类器: 最高估计性能接近 79%,在最大深度设置为 13 且使用原始数据集时实现。
- SVM: 训练时间明显长于其他算法。对于原始数据集,性能明显不足,这强调了数据转换的重要性。当 C 设置为 10,并使用 StandardScaler 和 0.25 的子集时,最佳估计性能约为 77%。
- 袋装决策树: 在使用原始数据集且 n_estimators 为 100 时,最高估计性能接近 82%。
- 随机森林: 100 个 n_estimators 的最高估计性能几乎达到 85%。
- 极端随机树: 在 100 个 n_estimators、StandardScaler 和 0.75 的子集下,最高估计性能接近 88%。
- AdaBoost: 100 个 n_estimators 的最高估计性能约为 38%。
- 梯度提升: 训练时间过长。当深度设置为 7 时,最佳估计性能接近 86%。
- 投票分类器: 最高估计性能接近 86%。
- XGBoost: 在使用 300 个 n_estimators、0.25 的子样本和 0.75 的子集时,最高估计性能接近 80%。
KNN、投票分类器、极端随机树和随机森林算法在预测森林覆盖类型方面表现最佳,因此我们可以使用这些算法中的任何一种来进行未来的森林覆盖预测。 结论使用机器学习预测森林覆盖类型是保护和可持续管理森林的重要工具。它使我们能够做出明智的决策,保护生物多样性,并确保这些关键生态系统的长寿。随着技术和数据的不断进步,我们理解和保护对地球生命至关重要的森林的能力也将随之提高。
|
