F1 分数的微、宏加权平均2025年3月17日 | 阅读 8 分钟 在分类任务中,有两种技术可以组合多个类别的 F1 分数:宏平均和微平均加权。模型的准确性由其 F1 分数决定,该分数考虑了精确率和召回率。它的范围从 0 到 1,1 代表最佳可能分数。它是精确率和召回率的调和平均值。 如果分类问题是多类的,则可以为每个类别单独计算 F1 分数。在不考虑每个类别 1 中样本百分比的情况下,每个类别 F1 分数的平均值称为宏平均 F1 分数。将所有类 1 的真正例、假正例和假负例加起来,可以得到微平均 F1 分数。按每个类别 1 中样本数量加权每个类别的 F1 分数的平均值是加权平均 F1 分数。 微 F1 分数在计算微 F1 分数时,会考虑所有类别中真正例、假负例和假正例的总数。通过将所有真正例、假负例和假正例加起来,可以全局计算 F1 分数。当您希望为每个数据点分配相同的权重而不考虑类别时,微 F1 分数是合适的。   其中: TPi:类别 i 的真正例 FPi:类别 i 的假正例 FNi:类别 i 的假负例 示例让我们通过一个例子来理解微 F1。假设我们有以下多类别问题的预测结果
正如您所见,每个类别的普通 F1 分数已经确定。我们只需要确定三个类别 F1 分数的平均值来得到宏 F1 分数,如下所示 微 F1 分数是 35 / (35 + 0.5 * (13 + 16)) = 0.71 宏 F1 分数所有类别的 F1 分数平均值决定了宏 F1 分数。 通过对为每个类别单独计算的 F1 分数取平均值来获得宏 F1 分数。在同等评估模型在每个类别的性能时,无论类别不平衡如何,宏 F1 分数都是合适的。 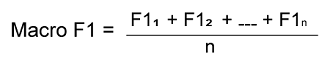 其中: n:类别总数 F1i:类别 i 的 F1 分数 示例让我们看一个例子来解决宏 F1 问题。使用以下多类别问题的预测结果。
正如您所见,每个类别的普通 F1 分数已经确定。我们只需要确定三个类别 F1 分数的平均值来得到宏 F1 分数,如下所示 宏 F1 分数是 (0.8+0.6+0.8)/3 = 0.73 加权 F1 分数?加权 F1 分数是在机器学习中用于评估模型性能的指标,特别是在存在类别不平衡的情况下。我们来分解一下 F1 分数F1 分数将精确率和召回率合并为一个值。它是通过精确率和召回率的调和平均值计算得出的。精确率表示阳性预测的准确性,而召回率衡量模型在多大程度上识别出实际的阳性案例。F1 分数的范围是 0 到 1,其中 1 是最好的。 加权平均 F1 分数加权平均 F1 分数会考虑每个类别的支持度(即数据集中类别的数量)。它是通过将所有类别 F1 分数的平均值与其支持度加权来计算的。例如,如果只有一条观测值的实际标签是 Boat,其支持度将是 12。 样本加权 F1 分数它非常适合类别不平衡的数据分布。它是类别 F1 分数的加权平均值,其中每个类别的样本数量决定了权重。请记住,F1 分数的范围仅在 0 和 1 之间,它是评估模型整体性能的有价值指标。 如何计算加权 F1 分数?通过根据每个类别的 F1 分数中的实例数量为其分配权重来计算加权平均值。 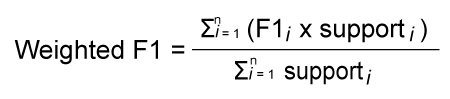 其中 N 是类别总数。 Supporti 是类别 i 中的实例数量。 通过 Python 代码计算这是一个 Python 代码示例,用于在 SkLearn IRIS 数据集上训练的模型上计算微平均和宏平均的精确率和召回率分数。该数据集包含三个不同的类别:setosa、versicolor 和 virginica。模型使用单个特征进行训练,以生成具有每个单元格中数字的混淆矩阵。观察分配给 iris 的训练数据 X.data[:, [1]]。 输出 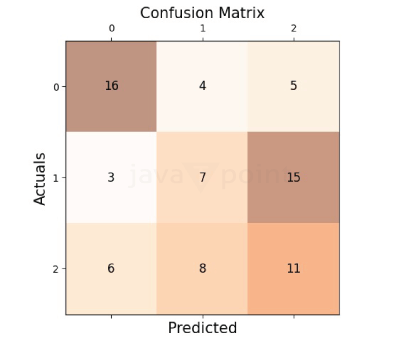 使用单个特征,在 IRIS 数据集上训练的模型将具有此混淆矩阵。用于计算微平均和宏平均精确率分数的 Python 代码如下所示 所有类别的真正例预测(对角线)precisionScore_manual_microavg, precisionScore_manual_macroavg Sklearn 的 recall_score、f1-score 和 precision_score 方法也可用于计算相同的内容。要找到微平均、宏平均和加权平均分数,必须将“average”参数传递三个级别。 输出 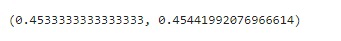 F1 分数,也称为 F 度量,是衡量分类模型性能的常用指标。在处理多类分类时,我们使用平均技术来计算 F1 分数,从而产生不同的平均分数,例如宏、微和加权分数。在分类报告中。下一节将描述平均分数,如何使用 Python 代码计算平均分数,以及为什么以及如何选择最佳分数。 不平衡数据集哪个更好?微 F1 和宏 F1 分数在不平衡数据集方面都有优点和需要考虑的方面
为什么 Scikit-Learn 分类报告没有微平均?是的,scikit-learn 的 classification_report 提供了精确率、召回率和 F1 分数的微平均。然而,分类报告的输出并没有专门将其标识为“Micro”。相反,它是所有类别精确率、召回率和 F1 分数的加权平均值,每个类别根据其出现的实例数量做出贡献。 它是如何工作的?
这些值根据每个类别的总实例数进行加权,表示所有类别的聚合性能指标,并在分类报告中显示,而没有明确标记为微平均。 微 F1 和宏 F1 的区别
我应该选择微 F1 还是宏 F1?在微平均和宏平均 F1 分数之间进行选择将取决于您的分类任务的具体情况以及您的目标 何时使用微 F1?
何时使用宏 F1?
结论F1 分数的加权平均、宏平均和微平均的选择取决于分类任务的目标和类别分布。虽然宏 F1 分数同等对待所有类别,但微 F1 分数优先考虑整体性能并倾向于较大的类别。加权平均会平衡类别大小。了解这些指标可以更轻松地选择最佳评估技术,并确保对模型进行全面评估。 下一主题线性回归的假设 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
