隔离森林17 Mar 2025 | 5 分钟阅读 Isolation Forest 是一种新颖的异常检测方法,旨在定位数据集中的异常值或异常情况。与之前分析正常数据点的方法不同,Isolation Forest 提供了一种新方法,直接识别异常。Isolation Forest 的核心前提是,异常通常不常见且与常规情况不同,这使得它们更容易分离。 Isolation Forest 工作流程包括创建一组隔离树,每棵树通过随机选择特征并分割数据点来构建,直到每个点都隔离在其自己的叶节点中。异常旨在比典型实例需要更少的划分才能隔离,这使得它们更容易根据所有树上较低的平均路径长度进行识别。 代码 现在,我们将借助 Isolation Forest 优雅地查找和消除异常值(异常)。 导入库读取数据集输出  在运行 IsolationForest 之前,下一步是进行一些小的预处理。我们删除 NaN 数量较多(>1000)的列,并填充所有特征的缺失值。最后,我们验证没有缺失数据。 输出  隔离算法当树从数据集的子集而不是完整数据集生成时,Isolation Forest (IF) 方法表现最佳。这与几乎所有其他策略都大相径庭,后者依赖于数据,并且需要更多数据才能提高准确性。子采样在这种方法中效果奇好,因为常规实例可能通过更接近异常值来扰乱隔离过程。在此示例中,我们将 max_samples=100,导致 Isolation Forest 为每个特征生成 100 个样本来训练基础估计器。
stats 数据框仅包含原始样本值、其分数、IF 是否将其视为异常值,以及一些基本特征统计信息,例如最小值、最大值和中值。  输出   让我们看看结果。
接下来,我们利用 pandas 的剪裁功能在输入级别去除异常值。它通过为该特定特征设置最小值和最大值来操作。所有值小于最小值的观测值将被分配为最小值,而所有值大于最大值的观测值将被分配为最大值。这些只是示例;您可以根据需要更改设置。 现在我们重新训练 IsolationForest 分类器,以测试剪裁值是否改善了异常值评分。请注意,在我们剪裁示例特征后,IsolationForest 生成的异常值分数有所降低。 输出 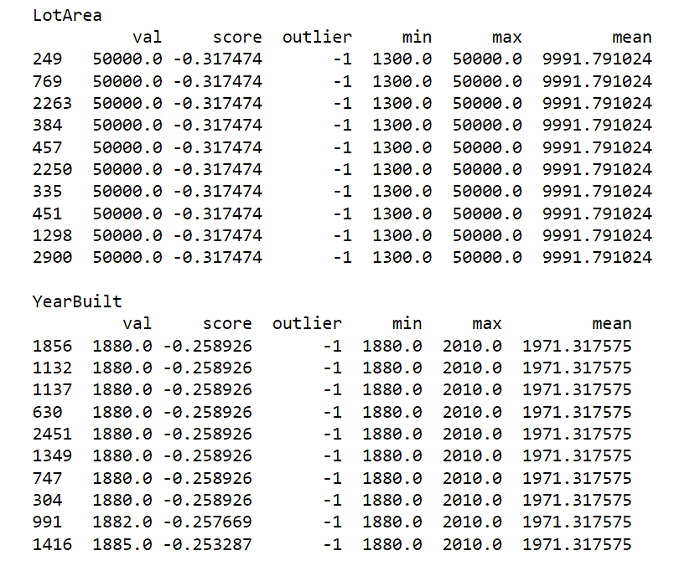  我们演示了如何使用 Isolation Forest 检测数据集中的异常值。我们以房价数据集为例。Isolation Forest 在子采样数据上表现出色,并且不需要从完整数据集构建树。它在子采样数据上表现良好。该技术运行速度非常快,因为它不依赖于计算量大的操作,例如距离或密度计算。训练步骤具有线性时间复杂度和低常数,使其适用于任何大规模数据处理应用程序。 下一个主题McNemar 检验 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
