机器学习中的过采样与欠采样2025年6月19日 | 阅读 10 分钟 在机器学习的许多实际应用中,确实会出现显著的类别不平衡。例如,在癌症检测应用中,假阳性输出的频率远高于真阳性,这意味着与稀缺的真阳性相比,大型数据集很可能包含许多假结果。类别不平衡对模型不利,尤其是在正确发现罕见实例时。当这些罕见点至关重要时,数据不足的问题就会变得关键。 选择良好的误差指标来惩罚模型在罕见观测值上的表现不佳非常重要。存在许多方法来处理不平衡数据集;最简单的是采样方法,它们以某种方式修改数据集:欠采样多数类、过采样少数类,或两者的组合。这些方法可用于改善模型在存在类别不平衡情况下的性能。 过采样当数据集中一个类别的实例数量远少于其他类别时,过采样被采纳为一种处理类别不平衡困难的方法。这种情况常见于欺诈检测、医学诊断和其他需要对模型性能而言罕见事件尤其重要的应用。总的来说,过采样的目的是增加少数类的存在,以便模型能更好地从这些实例中学习。 欠采样欠采样是用于处理数据集中类别不平衡的一种技术,尤其是在一个类别与其他类别相比非常庞大的情况下。它通常出现在欺诈检测、医学诊断以及更多应用中,在这些应用中,通过少数类预测正确结果非常重要。使用欠采样的主要原因是减少多数类的大小,以便模型能很好地从少数类中学习。 现在,为了更好地理解,我们将尝试实现过采样和欠采样。 输出  具有严重偏差的数据集可能偏向于一个或几个类别,而剩余类别则观测值很少;这可能导致模型失效,默认情况下,模型会预测大多数或所有点都属于占优类别,这在前面两个可视化图中有所体现。随着观测值在类别之间分布的更加均衡,模型的偏差会降低。 这实际上是一种克服罕见类别不平衡问题非常简单的方法,有时这种不平衡会引入扰乱输入到模型中的样本分布的错误。并非所有数据集都存在此问题,但尽早处理这种情况可以避免错误的建模结果。 获取样本数据出于演示目的,我们将使用以下数据集。 输出  基本过采样和欠采样`imbalanced-learn` 模块提供了一套数据采样技术,该模块已集成到 scikit-learn 中。该模块安装在基本的 sklearn 安装中,因此所有用户都可以访问。该模块的文档也非常详细。它在 `imblearn` 库中提供。过采样和欠采样可通过类来使用。 输出  输出  在第一张图中,过采样会复制稀有类别 2 和超稀有类别 3 的点,使这些类别的规模与多数类别 1 相同。这意味着重复了很多点,类别 2 只有 64 个唯一点,但需要等于类别 1 的 4700 个点。第二张图展示了欠采样,其中类别 1 和 2 的规模被减小,以匹配类别 3 的 64 个点。那么,您应该使用哪种技术来训练您的分类器?如果少数类的实例非常少,欠采样通常是更好的选择,以避免丢失其他类别中的重要信息。例如,如果类别 3 只有五个点,仅训练 15 个欠采样实例将非常困难。 在其他情况下,过采样和欠采样之间的差异通常几乎无关紧要。请记住,采样不会引入任何新信息,只是重新排列数据以改善模型的数值稳定性。 输出  默认情况下,观测值将被平衡:即,每个类别的出现次数相等。但是,还有一个 `ratio` 参数,您可以指定样本数据集中每个类别的绝对观测值数量——例如,“类别 1 的 60 个观测值”。它可以帮助您控制样本数据集中您希望包含的类别数量。例如 输出 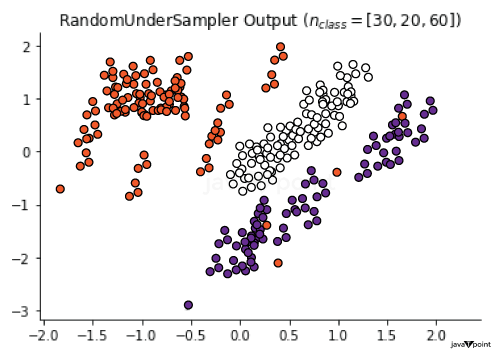 当训练集上的类别分布不能反映真实世界的类别分布,并且您有足够的数据可以“修剪”数据集时,这种重采样方法特别方便。但理想情况下,您不会处理如此有偏见的数据。然而,在实践中,这种情况发生得相当频繁。例如,考虑从临床环境中收集的肾脏健康评估数据集,该数据集的值为“健康”或“不健康”相对于某个分数。可以公平地假设,普通人群的肾脏比临床人群更健康。为了构建一个能很好地从广泛人群中泛化的模型,首先,重采样将是一个重要的步骤! 样本大小学习曲线在偏差和方差之间的权衡中,重采样旨在减少偏差或欠拟合,就像我们前面例子中非常简单的单类版本一样;但它不应该过度增加方差或过拟合,这在我们观察的次数更少或对同一组数据进行多次测量时可能会发生。在实践中,平衡可以通过学习曲线来量化。 学习曲线指示模型随着训练观测值的增加而拟合得如何。可以通过在逐渐增大的样本上训练模型并在完整的测试集上进行评估来观察性能变化。一旦稳定,就意味着样本量足以捕捉底层数据分布而不损害准确性。这里有一个使用我们合成数据集样本数据绘制的学习曲线的简单例子 输出  学习曲线表明,模型的性能稳定在每类大约 30 个观测值。此时,在采样数据上训练的 SVM 的决策边界将不再剧烈波动。因此,我们使用的 64 点 RandomUnderSampler 可能不会引入过少的方差,从而浪费了噪声。因此,如果通过欠采样来解决罕见类别的偏差,那么它就是一种有用的技术。 创建和分析学习曲线相当简单且非常有价值。请注意,对于相对简单、二维的正态数据,需要更少的观测值来获得稳定性;对于更复杂的数据集,可能需要更大的样本量来达到稳定性。 集成采样器简单的采样方法,如过采样和欠采样,被组合起来创建固定大小的样本,这些样本可以根据需要进行自定义。例如,您可以使用多个采样器迭代地对一个类别进行过采样,然后对另一个类别进行欠采样,必要时使用 `ratio` 参数进行微调。 但这变得单调乏味。为了简化事情,scikit-learn 提供了一些称为“集成采样器”的更高级抽象。其中最原始的是 EasyEnsemble。此采样器是数据集特征的朴素重采样。这有助于简化过程。以下是将 EasyEnsemble 应用于合成数据集的方法 输出 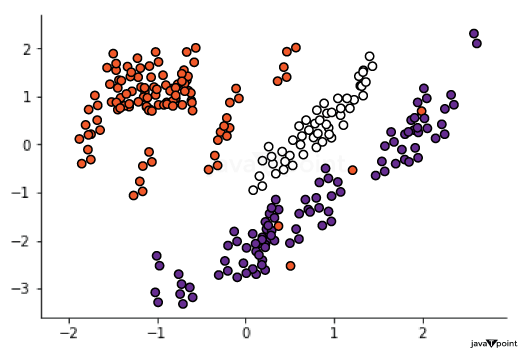 EasyEnsemble 有趣之处在于,它会进行十次重采样,并为您提供十个不同的样本集。这里显示的图只是第一个样本,您可以通过更改 `n_subsets` 参数来控制迭代次数。EasyEnsemble 进一步实现了无放回抽样。 默认情况下,EasyEnsemble 的行为类似于 RandomUnderSampler 类,它将多数类别欠采样到最小类别中的可用样本数量。也就是说:如果类别 3 只有 64 个样本,则生成的样本每个类别有 64 个,因此每个样本的数据集形状会从 (5000, 2) 缩小到 (192, 2)。您可以通过传递一个字典来指定每个类别的所需观测值数量,进一步使用 `ratio` 参数来优化这一点。另一方面,我认为 EasyEnsemble 的 API 有点令人困惑,因为它本身不支持对一个类别进行过采样和对另一个类别进行欠采样的组合。然而,EasyEnsemble 能够进行有放回抽样的独特能力是基本采样方法所不具备的,尽管我对其实际效用持怀疑态度,但这是可以做到的。 或者,您可以使用 BalanceCascade,它是 EasyEnsemble 的计算实现。此算法要求您提供一个估计器,该估计器随后用于预测输出类别。执行采样时,错误分类的观测值会被替换到数据集中,而正确分类的观测值则被保留。结果是一组偏向于复制更难分类的观测值的样本。 EasyEnsemble 可以有放回和无放回地进行过/欠采样,而 Balance Cascade 则进行智能替换。如果您对罕见类别的挑战性实例的性能感兴趣,那么它是一种特别有用的技术,可以通过在分类器性能不佳的相同数据点上重复训练并测量差异来研究分类器的数值稳定性问题。 输出  过采样和欠采样的应用到目前为止,我们已经讨论了采样数据的基本原理,并介绍了 sklearn 中提供的欠采样和过采样功能。接下来,让我们探讨一个实际应用。为了简化可视化,我们将只关注前两个预测变量列 V1 和 V2。 输出  输出  信用卡欺诈实例相对较少,因此在训练一个有效的模型时,必须使用某种方法来处理这种类别不平衡。否则,支持向量机很可能无法工作:它根本无法在此数据中找到强特征。 输出  我们可以对数据进行重采样,以看到一个更明显和显著的模式。看起来,V2 值较大的交易几乎总是欺诈。 输出  当我们在此重采样数据上训练 SVM 时,这种学习的洞察力现在将使算法对这种模式敏感,从而选择反映其所学知识的分离超平面。 输出  假设您正在构建一个“早期预警”系统,以隔离可能为欺诈但需要进一步检查的交易。我们的分析师在他们的市场研究和成本分析中确定,52:1 的假阳性与真阳性之比是可以接受的。我们可以为此目的制定专门的分类指标。在此可能但假设的成本场景中,我们会发现,即使我们错误地分类了大量真实记录,采样后模型的成本也几乎与预处理模型相同。 输出  输出  下一主题印度机器学习公司列表 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
