机器学习算法2025 年 5 月 27 日 | 阅读 8 分钟 机器学习算法是能够从数据中学习隐藏模式、预测输出并自主提高性能的程序。机器学习中有不同的算法可用于不同的任务,例如可用于预测问题(如股票市场预测)的简单线性回归,以及可用于分类问题的KNN 算法。 在本主题中,我们将概述一些流行且最常用的机器学习算法,并介绍它们的用例和类别。 机器学习算法的类型机器学习算法可大致分为三类
下图说明了不同的机器学习算法及其类别 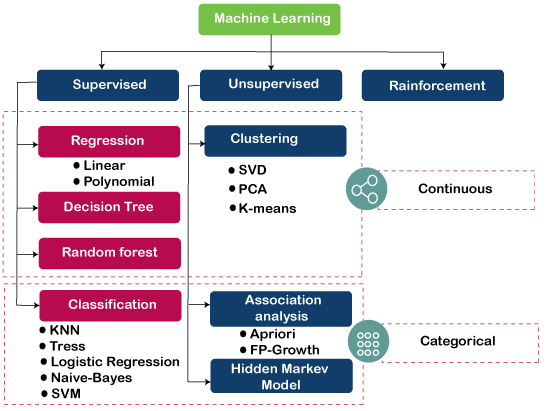 1) 监督学习算法监督学习是一种机器学习类型,在这种类型中,机器需要外部监督才能学习。监督学习模型使用带标签的数据集进行训练。一旦完成训练和处理,就会通过提供样本测试数据来测试模型,以检查它是否预测了正确的输出。 监督学习的目标是将输入数据与输出数据进行映射。监督学习基于监督,这与学生在老师的监督下学习事物相同。监督学习的例子是垃圾邮件过滤。 监督学习可进一步分为两类问题 一些流行的监督学习算法的例子是简单线性回归、决策树、逻辑回归、KNN 算法等。了解更多.. 2) 无监督学习算法这是一种机器学习类型,在这种类型中,机器不需要任何外部监督即可从数据中学习,因此称为无监督学习。无监督模型可以使用未标记的数据集进行训练,这些数据集未分类或未分类,算法需要在没有任何监督的情况下处理这些数据。在无监督学习中,模型没有预定义的输出,它试图从大量数据中找到有用的见解。它们用于解决关联和聚类问题。因此,进一步可将其分为两类:
一些无监督学习算法的例子是K-均值聚类、Apriori 算法、Eclat 等。了解更多.. 3) 强化学习在强化学习中,智能体通过产生动作与环境进行交互,并通过反馈进行学习。智能体获得的反馈是奖励的形式,例如,每个好的动作都会获得积极的奖励,每个坏的动作都会获得消极的奖励。智能体没有获得任何监督。Q-Learning 算法用于强化学习。了解更多… 流行的机器学习算法列表
1. 线性回归线性回归是最流行且简单的机器学习算法之一,用于预测分析。这里,预测分析定义了某事的预测,而线性回归对连续数字进行预测,例如薪水、年龄等。 它显示了因变量和自变量之间的线性关系,并显示了因变量 (y) 如何根据自变量 (x) 变化。 它试图在因变量和自变量之间拟合一条最佳直线,这条最佳直线称为回归线。 回归线的方程为 y= a0+ a*x+ b 其中,y= 因变量 x= 自变量 a0 = 直线截距。 线性回归进一步分为两种类型
下图显示了用于根据身高预测体重的线性回归:了解更多..  2. 逻辑回归逻辑回归是一种监督学习算法,用于预测分类变量或离散值。它可用于机器学习中的分类问题,逻辑回归算法的输出可以是“是”或“否”、“0”或“1”、“红”或“蓝”等。 逻辑回归与线性回归相似,只是它们的使用方式不同,例如,线性回归用于解决回归问题并预测连续值,而逻辑回归用于解决分类问题并用于预测离散值。 它不是拟合最佳直线,而是形成一条介于 0 和 1 之间的 S 形曲线。S 形曲线也称为逻辑函数,它使用阈值概念。高于阈值的值将趋向于 1,低于阈值的值将趋向于 0。了解更多.. 3. 决策树算法决策树是一种监督学习算法,主要用于解决分类问题,但也可用于解决回归问题。它可以处理分类变量和连续变量。它显示了一个树状结构,包括节点和分支,从根节点开始,然后展开到叶节点。内部节点用于表示数据集的特征,分支表示决策规则,叶节点表示问题结果。 决策树算法的一些实际应用是识别癌细胞和非癌细胞,向客户推荐购买汽车等。了解更多.. 4. 支持向量机算法支持向量机或 SVM 是一种监督学习算法,也可用于分类和回归问题。然而,它主要用于分类问题。SVM 的目标是创建一个超平面或决策边界,可以将数据集分割成不同的类别。 有助于定义超平面的数据点称为支持向量,因此将其命名为支持向量机算法。 SVM 的一些实际应用是人脸检测、图像分类、药物发现等。考虑下图  如上图所示,超平面已将数据集分类为两个不同的类别。了解更多.. 5. Naïve Bayes 算法朴素贝叶斯分类器是一种监督学习算法,用于基于对象的概率进行预测。该算法之所以命名为朴素贝叶斯,是因为它基于贝叶斯定理,并遵循‘变量彼此独立’的朴素假设。 贝叶斯定理基于条件概率;这意味着在给定事件 (B) 已发生的情况下,事件 (A) 发生的可能性。贝叶斯定理的方程为  朴素贝叶斯分类器是提供给定问题良好结果的最佳分类器之一。构建朴素贝叶斯模型很容易,并且非常适合处理大量数据集。它主要用于文本分类。了解更多.. 6. K-Nearest Neighbour (KNN)K-Nearest Neighbour 是一种监督学习算法,可用于分类和回归问题。该算法通过假设新数据点与可用数据点之间的相似性来工作。基于这些相似性,新数据点被归入最相似的类别。它也称为懒惰学习者算法,因为它存储所有可用数据集,并通过 K 个邻居对每个新案例进行分类。新案例被分配给具有最大相似性的最近类别,任何距离函数都测量数据点之间的距离。距离函数可以是欧几里得距离、闵可夫斯基距离、曼哈顿距离或汉明距离,具体取决于要求。了解更多.. 7. K-Means ClusteringK-Means 聚类是最简单的无监督学习算法之一,用于解决聚类问题。数据集根据相似性和不相似性分为 K 个不同的簇;这意味着具有最多共同点的数据集保留在一个簇中,而与其他簇的共同点非常少或没有。在 K-Means 中,K 指的是簇的数量,Means 指的是对数据集取平均值以查找质心。 它是一种基于质心的算法,每个簇都与一个质心相关联。该算法旨在减小数据点与其簇内质心之间的距离。 该算法从一组随机选择的质心开始,这些质心最初形成簇,然后执行迭代过程来优化这些质心的位置。 它可用于垃圾邮件检测和过滤、识别假新闻等。了解更多.. 8. Random Forest AlgorithmRandom forest 是一种监督学习算法,可用于机器学习中的分类和回归问题。它是一种集成学习技术,通过组合多个分类器提供预测并提高模型的性能。 它包含多个决策树,用于处理给定数据集的子集,并通过求平均值来提高模型的预测准确性。随机森林应包含 64-128 棵树。树的数量越多,算法的准确性就越高。 要对新的数据集或对象进行分类,每棵树都会给出分类结果,算法根据多数票预测最终输出。 Random forest 是一种快速的算法,可以有效地处理丢失和不正确的数据。了解更多.. 9. Apriori AlgorithmApriori 算法是一种无监督学习算法,用于解决关联问题。它使用频繁项集来生成关联规则,并设计用于处理包含事务的数据库。借助这些关联规则,它可以确定两个对象之间的连接有多强或有多弱。该算法使用广度优先搜索和哈希树来高效地计算项集。 该算法通过迭代过程从大型数据集中查找频繁项集。 Apriori 算法由R. Agrawal 和 Srikant 于 1994 年提出。它主要用于市场篮子分析,有助于了解可以一起购买的产品。它也可用于医疗保健领域,以查找患者的药物反应。了解更多.. 10. 主成分分析主成分分析 (PCA) 是一种无监督学习技术,用于降维。它有助于减少包含许多相互关联特征的数据集的维度。它是一个统计过程,通过正交变换将相关特征的观测值转换为一组线性不相关的特征。它是用于探索性数据分析和预测建模的流行工具之一。 PCA 通过考虑每个属性的方差来工作,因为高方差显示了类之间的良好划分,因此它降低了维度。 PCA 的一些实际应用包括图像处理、电影推荐系统、优化各种通信信道中的功率分配。了解更多.. |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
