决策树分类算法2025年3月17日 | 阅读 10 分钟
注意:决策树可以包含分类数据(是/否)和数值数据。 为什么要使用决策树?机器学习中有各种算法,因此选择最适合给定数据集和问题的算法是创建机器学习模型时要记住的主要一点。以下是使用决策树的两个原因:
决策树术语决策树算法如何工作? 在决策树中,为了预测给定数据集的类别,算法从树的根节点开始。该算法将根属性的值与记录(实际数据集)属性进行比较,并根据比较结果沿着分支跳转到下一个节点。 对于下一个节点,算法再次将属性值与不同的子节点进行比较并进一步移动。它继续这个过程,直到到达树的叶节点。可以使用以下算法更好地理解完整的过程:
示例:假设有一位候选人收到了工作机会,并想决定是否接受。因此,为了解决这个问题,决策树从根节点(由 ASM 的薪资属性)开始。根节点根据相应的标签进一步分裂成下一个决策节点(到办公室的距离)和一个叶节点。下一个决策节点进一步分裂成一个决策节点(出租车服务)和一个叶节点。最后,决策节点分裂成两个叶节点(接受的报价和拒绝的报价)。请参考下图  属性选择度量在实现决策树时,主要问题是如何为根节点和子节点选择最佳属性。因此,为了解决这类问题,有一种技术称为属性选择度量或 ASM。通过这种度量,我们可以轻松地为树的节点选择最佳属性。ASM 有两种流行技术,它们是:
1. 信息增益
熵:熵是衡量给定属性中不纯度的度量。它表示数据的随机性。熵可以计算为: Entropy(s)= -P(yes)log2 P(yes)- P(no) log2 P(no) 其中,
2. 基尼指数
Gini Index= 1- ∑jPj2 剪枝:获得最优决策树剪枝是从树中删除不必要节点的過程,以获得最优决策树。 太大的树会增加过拟合的风险,而太小的树可能无法捕获数据集的所有重要特征。因此,一种在不降低准确性的情况下减小学习树大小的技术称为剪枝。主要有两种树剪枝技术:
决策树的优点
决策树的缺点
决策树的 Python 实现现在我们将使用 Python 实现决策树。为此,我们将使用我们在之前的分类模型中使用的“user_data.csv”数据集。通过使用相同的数据集,我们可以将决策树分类器与其他分类模型进行比较,例如KNN SVM、LogisticRegression 等。 步骤也将保持不变,如下所示:
1. 数据预处理步骤预处理步骤的代码如下: 在上面的代码中,我们对数据进行了预处理。其中我们加载了数据集,如下所示:  2. 将决策树算法拟合到训练集现在我们将模型拟合到训练集。为此,我们将从 sklearn.tree 库导入 DecisionTreeClassifier 类。代码如下: 在上面的代码中,我们创建了一个分类器对象,其中我们传递了两个主要参数:
下面的输出是: Out[8]:
DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False,
random_state=0, splitter='best')
3. 预测测试结果现在我们将预测测试集结果。我们将创建一个新的预测向量 y_pred。代码如下: 输出 在下面的输出图像中,给出了预测输出和实际测试输出。我们可以清楚地看到预测向量中存在一些值,它们与实际向量值不同。这些是预测错误。  4. 测试结果的准确性(创建混淆矩阵)在上面的输出中,我们看到存在一些错误的预测,所以如果我们想知道正确和错误预测的数量,我们需要使用混淆矩阵。代码如下: 输出 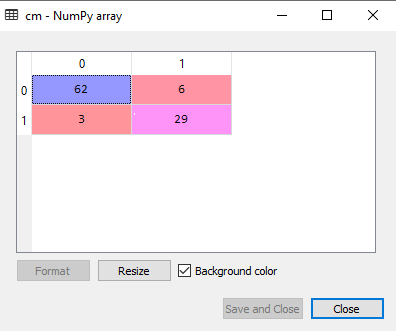 在上面的输出图像中,我们可以看到混淆矩阵,它有6+3=9 次错误预测,62+29=91 次正确预测。因此,我们可以说,与其它分类模型相比,决策树分类器做出了一个不错的预测。 5. 可视化训练集结果在这里,我们将可视化训练集结果。为了可视化训练集结果,我们将为决策树分类器绘制一个图。分类器将预测购买或未购买 SUV 汽车的用户的“是”或“否”,就像我们在逻辑回归中所做的那样。代码如下: 输出  上面的输出与其他分类模型完全不同。它既有垂直线又有水平线,这些线根据年龄和估计的薪资变量分割了数据集。 正如我们所见,树试图捕获每个数据集,这是过拟合的情况。 6. 可视化测试集结果测试集结果的可视化将与训练集的可视化相似,只是训练集将被替换为测试集。 输出  如上图所示,在紫色区域内有一些绿色数据点,反之亦然。所以,这些是我们曾在混淆矩阵中讨论过的错误预测。 关于决策树分类算法的选择题练习1. 基尼指数使用什么标准来确定决策树中节点的纯度?
答案 c) 类别概率之间的平方差 说明 基尼指数通过计算类别概率之间的平方差,求和,然后从 1 中减去来衡量节点纯度。 2. 以下哪种剪枝技术常用于避免决策树的过拟合?
答案 c) 预剪枝和后剪枝 说明 预剪枝和后剪枝是通过限制树的生长或在树完全生长后移除树的一部分来防止过拟合的技术。 3. 断言 (A):决策树容易过拟合。 原因 (R):决策树可以通过分割数据以完美匹配所有训练点来创建过于复杂的模型。 选项
答案 a) A 和 R 都正确,R 是 A 的正确解释。 说明 决策树可能通过创建完美匹配训练数据的复杂模型而过拟合,从而捕获噪声而不是潜在模式。这会导致高方差和对新数据泛化能力差。 4. 在决策树中,更高的信息增益表明某个特征具有什么特点?
答案 b) 该特征能更好地分离类别 说明 更高的信息增益表明该特征能更好地分离类别,从而提高分裂的纯度。 5. 在决策树的背景下,使用随机森林的目的是什么?
答案 c) 降低方差并提高泛化能力 说明 随机森林结合了多个决策树来降低方差并提高模型的泛化能力。 下一主题机器学习面试题 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
