机器学习中的安置预测2025年7月30日 | 阅读 10 分钟  随着科技渗透到我们生活的方方面面,机器学习的应用在我们当今快节奏的社会中日益普及。招聘预测是机器学习众多应用之一。利用机器学习算法,招聘预测根据包括学业成绩、技能组合和过往工作经验在内的各种标准,确定学生被公司录用的可能性。 机器学习招聘预测的工作原理
回归分析是一种用于确定两个或多个变量之间关系的统计方法。在招聘预测中,回归分析用于确定包括学业成绩、技能组合、过往工作经验以及被公司录用可能性在内的多个变量之间的联系。 决策树是一种机器学习算法,它使用树状结构模拟决策和潜在结果。在招聘预测场景中,决策树被用于模拟企业在招聘过程中的决策制定。 受到人脑结构和功能的启发,机器学习算法被称为神经网络。在招聘预测中,神经网络被用于表示影响被公司录用可能性的众多因素之间的复杂联系。 在模型训练完成后,会使用测试数据对其进行测试以评估其性能。算法的有效性通过多种指标进行评估,包括准确率、精确率、召回率和 F1 分数。这些指标可以反映算法在预测学生录用可能性方面的有效性。 使用机器学习进行招聘预测的优势使用机器学习算法预测招聘结果有诸多优势。
代码实现在这里,我们尝试实现机器学习技术和方法,以找出被录用和未被录用的学生之间的关系和模式。 1. 导入库2. 读取数据集输出  我们有 2966 行,8 个特征。 输出  输出  输出 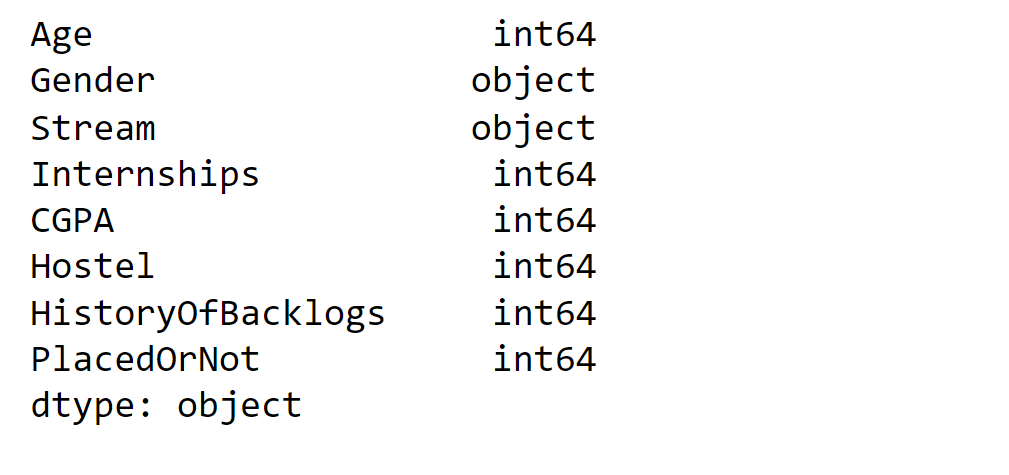 输出  输出  输出  “是否录用”与学生的 CGPA 关系最密切。 3. 预处理预处理是机器学习中的一个重要步骤,意味着在将数据馈送给算法进行学习之前,要使其准备好并干净。预处理是将原始数据转换为适合分析和建模格式的过程。 现在,我们将检查数据集中是否存在任何缺失值或重复值。 输出  输出  输出  4. EDA探索性数据分析是机器学习中的一个重要阶段,涉及检查和可视化数据以了解其构成、特征和趋势。它在开发实际的机器学习模型之前进行,对于发现潜在问题和选择正确的预处理和特征工程策略至关重要。 输出  输出 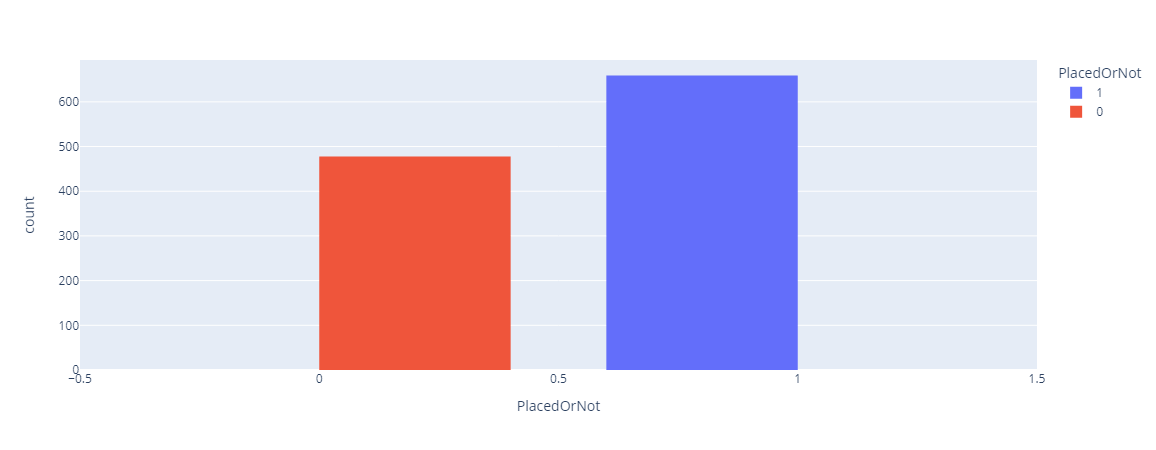 输出  输出  输出  输出  5. 表示统计表示过程涉及使用统计测量和可视化来以有意义且易于理解的方式呈现数据,主要目的是使用户能够理解数据中的洞察和模式,并使用数据做出明智的决策。 输出  输出  输出  6. 将分类变量编码为数值变量在机器学习中,将分类变量编码为数值变量是常见的预处理步骤。它需要将代表类别的质量属性变量转换为数值变量,该变量可用于数学运算和模型。 输出  输出  7. 提取输入和输出列输出  输出  输出  9. 缩放值10. 模型训练与评估模型的训练和评估是机器学习中决定模型准确性和性能的两个关键步骤。这些步骤需要仔细的规划、对细节的关注和严格的评估,才能开发出能够很好地泛化到新的、未见过的数据的模型。 在这里,我们将尝试不同的机器学习算法并找出它们的准确率。 1. 逻辑回归 输出  2. 决策树分类器 输出  3. 随机森林分类器 输出  4. 支持向量机 输出  输出  5. 朴素贝叶斯 输出  输出  输出  输出  6. KNN 输出  11. SGD 分类器 输出  输出  输出 
因此,模型中最好的准确率来自随机森林分类器。 输出 
使用GridsearchCV 进行超参数调优,调整随机森林的参数并获得最佳参数。 输出 
输出  使用 CV 的模型准确率为 83%,不使用 CV 的模型准确率为 80%。 我们可以说,我们创建的模型准确率相当高。 结论使用机器学习进行招聘预测可以预测学生被公司录用的可能性。机器学习算法的应用为招聘流程提供了一种更具数据驱动性和客观性的方法,使企业能够发现通过传统招聘技术可能被忽略的潜在应聘者。机器学习在各个行业的普及程度越来越高,使用机器学习算法进行招聘预测必将成为招聘流程中的一项重要工具。 下一主题理解多头注意力机制 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
