GBM 在机器学习中的应用2025年6月21日 | 9分钟阅读 机器学习是构建用于各种复杂回归和分类任务的预测模型最流行的技术之一。梯度提升机 (GBM) 被认为是最强大的提升算法之一。  尽管机器学习中有许多算法,但提升算法已成为全球机器学习界的主流。提升技术遵循集成学习的概念,因此它将多个简单的模型(弱学习器或基估计器)组合起来以生成最终输出。GBM 在机器学习中也用作集成方法,将弱学习器转换为强学习器。在本主题“机器学习中的GBM”中,我们将讨论梯度机器学习算法、机器学习中的各种提升算法、GBM 的历史、它的工作原理、GBM 中使用的各种术语等。但在开始之前,请先了解提升概念和机器学习中的各种提升算法。 机器学习中的提升是什么?提升是一种流行的学习集成建模技术,用于通过各种弱分类器构建强分类器。它首先从可用的训练数据集中构建一个主要模型,然后识别基模型中存在的错误。在识别错误后,构建第二个模型,然后在这个过程中引入第三个模型。通过这种方式,这个引入更多模型的过程会一直持续,直到我们获得一个可以正确预测的完整训练数据集。 AdaBoost(自适应提升)是机器学习历史上第一个将各种弱分类器组合成单个强分类器的提升算法。它主要专注于解决分类任务,如二元分类。 提升算法中的步骤提升算法包含以下几个重要步骤:
示例假设我们有三个不同的模型及其预测,它们的工作方式完全不同。例如,线性回归模型显示数据中的线性关系,而决策树模型试图捕捉数据中的非线性,如下图所示。 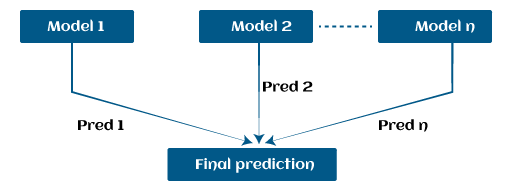 此外,如果我们不单独使用这些模型来预测结果,而是将它们以系列或组合的形式使用,那么我们将获得一个比所有基模型都包含正确信息的最终模型。换句话说,如果我们使用这些模型的平均预测而不是每个模型单独的预测,那么我们将能够从数据中捕获更多信息。这被称为集成学习,提升也基于机器学习中的集成方法。 机器学习中的提升算法机器学习中主要有 4 种提升算法。它们如下:
机器学习中的GBM是什么?梯度提升机 (GBM) 是机器学习中最流行的前向学习集成方法之一。它是用于回归和分类任务构建预测模型的强大技术。 GBM 帮助我们以决策树等弱预测模型的集成形式获得预测模型。每当决策树作为弱学习器运行时,得到的算法就称为梯度提升树。 它使我们能够组合来自各种学习器模型的预测,并构建具有正确预测的最终预测模型。 但是这里可能有一个问题:如果我们应用相同的算法,多个决策树如何能比单个决策树提供更好的预测?此外,每个决策树如何从相同的数据中捕获不同的信息? 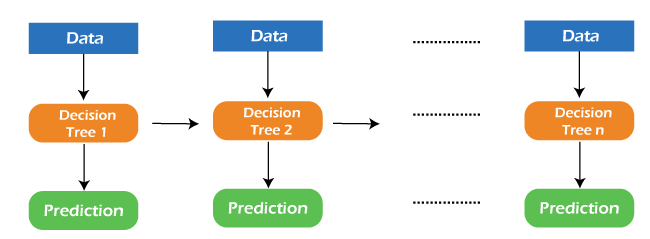 因此,这些问题的答案是,每个决策树的节点都使用不同特征子集来选择最佳分割点。这意味着每个树的行为不同,因此可以从相同的数据中捕获不同的信号。 GBM 如何工作?一般来说,大多数监督学习算法都基于单一预测模型,如线性回归、惩罚回归模型、决策树等。但机器学习中有一些监督算法通过集成将多个模型组合在一起。换句话说,当多个基模型贡献其预测时,提升算法会采用所有预测的平均值。 梯度提升机包含 3 个元素,如下所示:
让我们详细了解这三个元素。 1. 损失函数虽然机器学习中有大量的损失函数可供选择,具体取决于要解决的任务类型。损失函数的使用是通过条件分布的特定特性的需求来估计的,例如鲁棒性。在使用损失函数处理任务时,我们必须指定损失函数和计算相应负梯度的函数。一旦我们获得这两个函数,就可以轻松地将它们实现到梯度提升机中。然而,已经为 GBM 算法提出了几种损失函数。 损失函数的分类根据响应变量 y 的类型,损失函数可分为以下几类:
2. 弱学习器弱学习器是基学习器模型,它们从过去的错误中学习,并有助于构建用于机器学习中提升算法的强大预测模型设计。通常,决策树在提升算法中用作弱学习器。 提升被定义为一个框架,该框架持续致力于改进基模型的输出。许多梯度提升应用程序允许您“插入”各种类别的弱学习器。因此,决策树最常用于弱(基)学习器。 如何训练弱学习器机器学习使用训练数据集来训练基学习器,并根据前一个学习器的预测,通过关注前一个树错误或残差最大的训练数据行来提高性能。例如,浅层树被认为是决策树的弱学习器,因为它包含较少的分割点。通常,在提升算法中,具有最多 6 个分割点的树是最常见的。 以下是训练弱学习器以提高其性能的序列,其中序列中的每个树都与前一个树的残差相关。此外,我们引入每个新树,以便它可以从前一个树的错误中学习。它们如下:
继续这个过程,直到某个机制(即交叉验证)告诉我们停止。最终模型是 b 个单独的树的阶段性加性模型 f(x)=B∑b=1fb(x)因此,树是贪婪地构建的,选择基于纯度分数(如 Gini)的最佳分割点或最小化损失。 3. 加性模型加性模型被定义为向模型添加树。虽然我们一次不应该添加多棵树,但只能添加一棵树,以便现有树不被更改。此外,我们还可以优先使用梯度下降方法通过添加树来减少损失。 在过去的几年里,梯度下降法被用来最小化一组参数,例如回归方程的系数和神经网络中的权重。计算出误差或损失后,权重参数用于最小化误差。但最近,大多数机器学习专家倾向于使用弱学习器子模型或决策树作为这些参数的替代。在这种情况下,我们必须在模型中添加一棵树来减少误差并提高该模型的性能。通过这种方式,新添加树的预测与现有树系列的预测相结合,以获得最终预测。这个过程一直持续到损失达到可接受的水平或不再需要改进为止。 此方法也称为函数式梯度下降或带函数的梯度下降。 极端梯度提升机 (XGBM)XGBM 是梯度提升机的最新版本,其工作方式与 GBM 非常相似。在 XGBM 中,树是按顺序(一次一个)添加的,它们从前一棵树的错误中学习并改进它们。尽管 XGBM 和 GBM 算法在外观和感觉上相似,但它们之间仍有一些区别,如下所示:
Light Gradient Boosting Machines (Light GBM)Light GBM 是梯度提升机的更高级版本,因为它高效且速度快。与 GBM 和 XGBM 不同,它可以毫无复杂性地处理大量数据。另一方面,它不适合数据点数量较少的情况。 Light GBM 偏爱树节点的叶向生长,而不是层向生长。此外,在 light GBM 中,主节点被分割成两个次节点,然后它选择一个次节点进行分割。次节点的分割取决于哪个节点具有更高的损失。 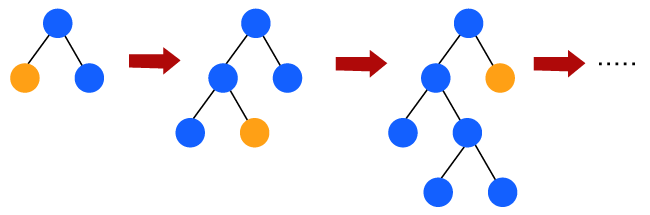 因此,由于叶向分割,在处理大量数据的情况下,通常首选 Light Gradient Boosting Machine (LGBM) 算法。 CATBOOSTCatboost 算法主要用于处理数据集中的分类特征。尽管 GBM、XGBM 和 Light GBM 算法适用于数值数据集,但 Catboost 设计用于将分类变量转换为数值数据。因此,Catboost 算法包含一个必要的预处理步骤,用于将分类特征转换为数字变量,而其他算法都不具备此功能。 提升算法的优点
提升算法的缺点以下是提升算法的一些缺点:
结论通过这种方式,我们了解了机器学习中用于预测建模的提升算法。此外,我们讨论了 ML 中使用的各种重要提升算法,如 GBM、XGBM、light GBM 和 Catboost。此外,我们还看到了各种组件(损失函数、弱学习器和加性模型)以及 GBM 如何与它们协同工作。提升算法在实际场景中的部署有哪些优势等等。 下一个主题机器学习中的嵌入是什么 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
