机器学习在儿童医疗保健中预测腺病毒疾病17 Mar 2025 | 6 分钟阅读 机器学习是人工智能的一个分支,它帮助计算机从过去的数据中学习。它使用不同的算法来构建数学模型并利用先前的数据进行预测。机器学习用于诸如疾病预测、语音识别、电子邮件过滤、推荐系统等任务。 使用机器学习模型预测疾病是一项重要任务,有助于通过其诊断和预防措施来促进医疗保健。不同的机器学习算法分析患者数据,以识别可以预测疾病及其状况的模式。 在本文中,我们将学习使用机器学习算法进行儿童医疗腺病毒疾病的预测。它将利用以往的数据,帮助人们检测和预防腺病毒疾病。该模型的一个显著特点是,当个体输入其生物学参数时,它能够准确识别腺病毒感染,从而可能减少对医院进行物理检查的需求。这在医生不易获得的农村地区尤为重要。 什么是腺病毒疾病?腺病毒,即DNA病毒,引起呼吸道感染、胃肠道或结膜感染。腺病毒是由腺病毒引起的一组感染,可以感染人类。腺病毒大致分为 50 种不同类型,每种类型都可能引起一组独特的症状。腺病毒感染在幼儿中最常见,但任何人都有可能发生。 腺病毒感染的症状包括:
腺病毒疾病预测数据集该数据集包含5434个样本和八个不同的参数。其中,4484个样本为感染,950个样本为健康。我们将对给定的数据集训练各种机器学习算法。 腺病毒疾病预测为了使用不同的机器学习算法预测腺病毒疾病,我们需要执行以下不同的步骤: 步骤 1. 导入所需的库和数据集。 代码 输出  说明 我们安装了pandas、numpy 和 sklearn 等库,用于数据帧和机器学习模型,以及matplotlib 和 seaborn 用于数据可视化。然后,我们加载了我们的数据集并将其存储在数据帧中。 第二步:数据预处理 此步骤包括数据清理、了解数据集的结构等等。 首先,我们将检查数据集中是否存在任何空值。info() 方法将显示数据集的基本结构。 代码 输出 <class 'pandas.core.frame.DataFrame'> RangeIndex: 5434 entries, 0 to 5433 Data columns (total 9 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Breathing Problem 5434 non-null object 1 Pink Eye 5434 non-null object 2 Pneumonia 5434 non-null object 3 Fever 5434 non-null object 4 Acute Gastroenteritis 5434 non-null object 5 Dry Cough 5434 non-null object 6 Sore throat 5434 non-null object 7 Bladder Infection 5434 non-null object 8 Adenoviruses 5434 non-null object dtypes: object(9) memory usage: 382.2+ KB 说明 info() 函数用于获取基本结构,以检查数据集中是否存在空值。 现在,我们将使用 describe 函数检查数据集的描述性统计视图。 代码 输出 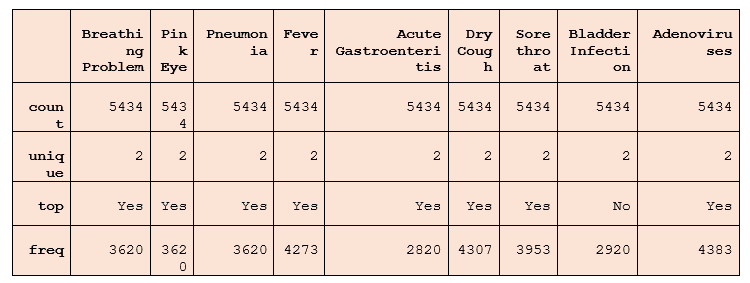 说明 describe() 方法提供了数据集的描述性统计视图。它提供了计数、唯一值、顶部值和频率信息。 步骤 3:数据操作 数据操作涉及将数据集转换为机器学习算法分析所需的合适参数。它包括缩放、编码、归一化和降维。这有助于提高数据质量和模型性能。 代码 输出  说明 我们导入了LabelEncoder 来转换数据集。它对数据集进行了缩放,以便机器学习模型更容易分析和理解。 步骤 4:计算相关性 在此步骤中,我们将使用 corr() 方法计算特征之间的相关性。 代码 输出  说明 我们打印了不同特征之间的相关性,这描述了一个特征与另一个特征的关系。 步骤 5:拆分数据集 我们将使用 sklearn 库的 train_test_split 模块将数据集拆分为训练数据和测试数据。 代码 说明 我们从 sklearn 库导入了不同的模型,包括用于拆分数据集的train_test_split,用于构建混淆矩阵的 metrics,以及用于获取准确率的 accuracy_score。 步骤 6:模型构建 我们将使用不同的算法构建我们的腺病毒疾病预测模型,并选择准确率最高的最佳模型。 1. 逻辑回归 代码 输出 92.5353485861814 说明 我们将逻辑回归作为第一个模型,其准确率为 92%。 2. 随机森林回归器 代码 输出 68.89109966539078 说明 我们将随机森林回归器作为第二个模型,其准确率为 68%。 3. K-近邻分类器 代码 输出 92.91628534826306 说明 我们将 KNeighbours Classifier 作为第三个模型,其准确率为 92%。 4. 支持向量机 (SVM) 代码 输出 90.93532382704692 说明 我们将支持向量机作为第四个模型,其准确率为 90%。 5. 决策树分类器 代码 输出 93.56325158663642 说明 我们将决策树分类器作为第五个模型,其准确率为 93%。 步骤 6:模型准确率 代码 输出 Model Score 4 Decision Tree 93.56325158663642 2 KNN 92.91628534826306 0 Logistic Regression 92.5353485861814 3 Support Vector Machines 90.93532382704692 1 Random Forest 68.89109966539078 说明 我们按升序打印了每个模型的准确率。 步骤 7:模型准确率分析 我们将数据集分为训练数据(80%)和测试数据(20%)。然后,我们应用了不同的机器学习模型并检查了它们的准确率。我们发现决策树分类器的准确率为 93%。KNN 的准确率为 92.9%。逻辑回归的准确率为 92.5%。支持向量机的准确率为 90%,随机森林的准确率为 68%。 在所有模型中,决策树的准确率最高。它比所有其他算法都更有效。 步骤 8:预测腺病毒疾病 我们发现决策树是最有效的机器学习模型。因此,我们使用决策树来预测儿童医疗的腺病毒疾病。 测试用例 1 输出 The Patient is Adenovirus Positive(+ve) 测试用例 2 输出 The Patient is Adenovirus Negative(-ve) 下一个主题用于序列标注的 RNN |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
