Light Gradient Boosted Machine (LightGBM)2025年6月20日 | 阅读 7 分钟 LightGBM 是一个使用树结构预测模型的梯度提升框架。它被设计为分布式和高效的。因此,这种方法带来了许多优势,例如更快的训练速度、高效率、低内存使用量、更好的准确性、对并行和 GPU 学习的支持,以及在处理大规模数据集方面的许多其他优势。LightGBM 在众多决策树机器学习算法中,已成为 Kaggle 竞赛的王者,而 Kaggle 竞赛在很大程度上依赖于 XGBoost 等更强大的框架。自 Microsoft 发明以来,LightGBM 获得了大量关注,现在比 XGBoost 更受欢迎。它的速度比 XGBoost 快六倍,并且受到大多数数据科学家和 Kaggle 竞赛者的青睐。 LightGBM 算法相对较新,并且拥有大量的参数。这可以在 LightGBM 的文档中看到。随着数据集大小呈指数级增长,传统的数据科学算法正难以提供有效的结果。因此,LightGBM,因其快速和低内存需求而被称为“Light”,非常适合大型数据集。它的准确性,以及对 GPU 学习的支持,是它在数据科学应用中被广泛使用的另一个原因。尽管 LightGBM 有许多优点,但并非没有局限性。不建议将其用于小型数据集,因为它容易过拟合,从而可能产生次优结果。然而,对于数据科学家来说,LightGBM 将继续是一个强大而高效的工具,用于在大型问题上实现高准确性和性能。 导入库下面是一个分类任务的手动示例:我们将尝试捕获信用卡欺诈。数据集极其不平衡,因为我们可以看到相对于负样本的数量,正样本非常少。在这种情况下,GBDTs 的开发证明特别有用。我们标准化 Amount 特征,并移除 Time 特征,因为它对我们的目的没有用。此外,数据集高度不平衡,但如果提供了类别权重,GBDTs 非常适合不平衡数据集。最后,我们将数据分为训练集和验证集。 输出 0.17% of the data are positive examples import lightgbm as lgb # Use LightGBM Datasets to wrap our training and validation sets. train_lgb = lgb.Dataset(train_X, train_y, data_free_raw=False) val_lgb = lgb.Dataset(val_X, val_y, reference=train_lgb, data_free_raw=False) 影响梯度提升机训练的主要变量如下,并附有每个变量的摘要。 我们现在可以使用 LightGBM 来训练一个梯度提升 决策树。一个训练 GBDT、为我们绘制训练结果并为每次迭代提供 GBM 和验证结果的函数被封装在训练调用中。 输出  我们的第一个模型表现不佳。为了提高性能、加快训练速度或减少过拟合,我们可以调整许多参数。 参数下面描述并解释了各种模型参数,其中一些参数经过调整以提高模型的准确性。
输出 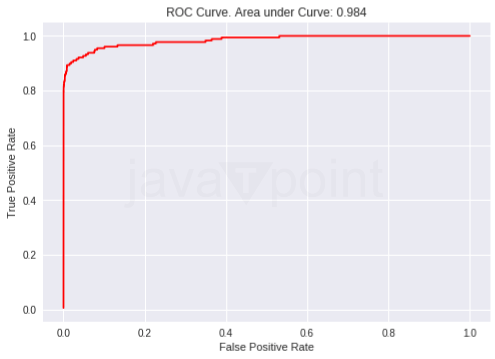 我们对参数的调整显著提高了模型的性能。上述设置提高了模型的准确性,但可以通过降低 max_bin 和指定 bagging_freq 来提高其速度。 输出  可以将现有模型作为 init_model 参数传递给训练函数以继续训练它。 代码 输出  代码 输出  大多数决策树学习算法是逐层增长树的,即树是深度优先生长的。这个过程涉及在继续到下一层之前分割当前深度的所有节点。也就是说,必须在深入之前构建树的每一层。逐层树生长的一个直观说明将更有效地描绘在这种方法中,所有特定层级的节点在进入下一层之前同时分裂的性质。 代码 输出  如果我们生长完整的树,最佳优先(叶子优先)和深度优先(层级优先)将产生相同的树。区别在于树的展开顺序。由于我们通常不会将树生长到其完整深度,因此顺序很重要。应用早期停止条件和修剪方法可能会导致非常不同的树。由于叶子优先的拆分纯粹基于对全局损失的贡献,而不是局部分支上的损失,因此它们通常(但不总是)能够比层级优先的选择更快地“学习”到低错误率的树。对于少数节点,叶子优先的性能可能优于层级优先系统。如果我们添加显著更多的节点,但不进行停止和修剪,我们可以预期收敛到相同的性能,因为那时它们实际上是在构建相同的树。 下一个主题机器学习中的堆叠(Stacking) |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
