无监督机器学习17 Mar 2025 | 4 分钟阅读 在上一节中,我们学习了监督机器学习,即模型在训练数据的监督下使用标记数据进行训练。但很多情况下,我们可能没有标记数据,需要从给定的数据集中找到隐藏的模式。因此,为了解决机器学习中的这类问题,我们需要无监督学习技术。 什么是无监督学习?顾名思义,无监督学习是一种机器学习技术,其中模型不使用训练数据集进行监督。相反,模型本身会从给定的数据中发现隐藏的模式和见解。这可以与人类大脑在学习新事物时进行的学习相比较。它可以定义为: 无监督学习是一种机器学习类型,其中模型使用未标记的数据集进行训练,并允许在没有任何监督的情况下对该数据进行操作。 无监督学习不能直接应用于回归或分类问题,因为与监督学习不同,我们有输入数据但没有对应的输出数据。无监督学习的目标是**找到数据集的底层结构,根据相似性对数据进行分组,并将数据集表示为压缩格式**。 示例:假设无监督学习算法接收一个包含不同类型猫和狗图像的输入数据集。该算法从未对给定数据集进行过训练,这意味着它对数据集的特征一无所知。无监督学习算法的任务是自行识别图像特征。无监督学习算法将通过根据图像之间的相似性将图像数据集聚类到组中来执行此任务。  为什么要使用无监督学习?以下是说明无监督学习重要性的一些主要原因:
无监督学习的工作原理可以通过下图理解无监督学习的工作原理: 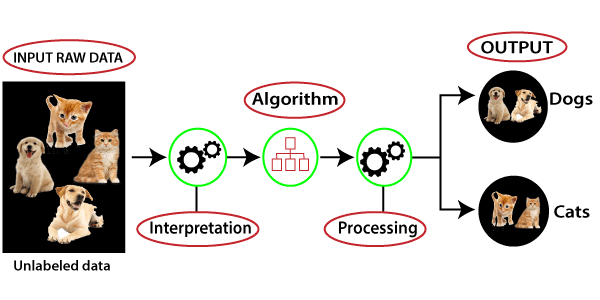 这里,我们采用了一个未标记的输入数据,这意味着它没有分类,也没有给出相应的输出。现在,将此未标记的输入数据馈送给机器学习模型以进行训练。首先,它将解释原始数据以查找数据中的隐藏模式,然后应用合适的算法,如 K-Means 聚类、决策树等。 一旦应用了合适的算法,算法就会根据对象之间的相似性和差异将数据对象分成组。 无监督学习算法的类型无监督学习算法可以进一步分为两类问题: 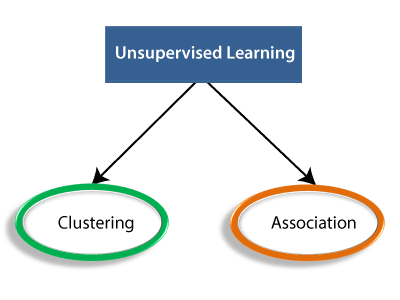
注意:我们将在后面的章节中学习这些算法。无监督学习算法以下是一些流行的无监督学习算法列表:
无监督学习的优点
无监督学习的缺点
下一主题监督学习与无监督学习 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
