机器学习中的情感分析2025年3月17日 | 阅读 15 分钟  情感分析,通常被称为意见挖掘,是一个利用机器学习能力来理解和评估文本数据中表达的人类情感、态度和观点的引人入胜的领域。在我们生活节奏快、动态变化的数字世界中,每天在社交媒体、客户评论和反馈等各种在线平台上都会产生大量的文本。对于企业、研究人员和组织来说,情感分析已成为获取公众情绪和意见宝贵见解的关键工具。理解人们如何看待和感受产品、服务或事件,对于做出明智的决策和在这个竞争激烈的环境中保持领先地位至关重要。 通过使用先进的语言处理方法和机器学习算法,情感分析可以轻松地将文本分类为积极、消极或中性情感。这是通过彻底检查模式、上下文线索和语言特征来实现的,使这些模型能够准确地检测和评估文本中表达的情感。 情感分析可分为几种类型,每种类型都有其独特的方法。例如,文档级情感分析旨在理解整个文档中表达的情感。另一方面,句子级情感分析则专注于单个句子,以掌握它们传达的情感。此外,子句或短语级情感分析更深入地研究更细粒度级别的情感,从而更深入地理解小型文本单元背后的情感。 现在我们将尝试对电影评论数据集进行情感分析。 在此,情感标签为
使用 Python 进行机器学习中的情感分析
让我们验证数据集中存在的示例和属性的数量。 输出  输出  从以上内容,我们观察到,为了稍后训练模型,文件只需要“短语”和“情感”两列。因此,我们在拟合转换器时将使用它们作为特征 (X) 和标签 (Y)。 如果任何列中存在空值或空白值,我们需要将其删除。为了识别此类值,我们将使用“info()”函数。 输出  输出  数据集看起来状况良好。重要的是要检查标签中五种类别的分布情况,以确定其是否平衡。 输出  输出  标签的分布明显不平衡,只有“中性”类别占实例的 50% 以上,并且略微偏向正面评论。这表明要预测的类别将偏向于更常见的类别。因此,我们将需要一种文本平衡技术,例如数值特征的“SMOTE”,来解决这种不平衡。 让我们继续确定评论中的词数,以获得更好的见解。我们将为每个类别绘制直方图,以更有效地理解分布。 输出  在这五个直方图中,我们观察到随着我们在 x 轴上移动,分布遵循类似于负指数函数的递减模式。值得注意的是,“负面评论”类别似乎在“短语”列中拥有最长的句子,接近 52 个词。为了确认最长的句子,我们将使用 max() 函数。 输出  确实,最长的句子是 52 个词。如果我们要按词对文本进行分词,max_length 应设置为 52。但是,transformer 使用子词分词,这意味着实际的 token 数量可能会更高,可能达到 60 个或更多,具体取决于句子中使用的特定词。在建模过程中需要考虑这一点,因为它可能会显著影响训练时间。找到训练时间和性能之间的合适权衡对于确保高效且有效的模型训练至关重要。 输出  我们观察到 352 条评论的词数超过 40 个,只有 18 条评论超过 50 个词。这些数字占总实例 (156,060) 的一小部分,因此基于它们设置限制不会对分类过程产生显著影响。下面,我们可以找到一个包含 52 个词的句子的示例。值得注意的是,该句子包含拼写错误的单词、首字母缩略词以及一些可以进一步分解为子词的单词。 输出 
在这里,我们将开发、训练并比较以下算法
这些模型各有优缺点。其中,BERT 因其均衡的性能而广受青睐和使用。另一方面,RoBERTa 和其他模型以取得更好的错误指标而闻名,而 DistilBERT 则以其更快的训练速度而脱颖而出。我们将仔细考虑所有这些特性,以选择最适合我们数据集的模型。 从 `tensorflow.keras` 中需要以下组件 接下来,我们将从数据集中提取两个相关列(短语和情感)用于训练目的。 我们现在将数据集划分为训练集和验证集。由于该文件包含超过 15 万个实例,我们可以为验证选择一小部分,同时仍然拥有大量实例。为此,我们将 test_size 设置为 10%。 BERT首先,我们需要导入构建 Bert 模型所需的组件,包括 Model、Config 和 Tokenizer。这些组件对于准确构建模型至关重要。 我们将使用 'bert_base_uncased' 模型,并且选择的最大长度设置为 45,因为数据集中只有少数较长的序列。 输出  加载模型后,我们现在可以使用 Keras 的函数式 API 根据我们的数据集和任务来构建和微调它。如下所示,输入层考虑序列的最大长度,然后将其馈送到 BERT 模型。添加了一个 dropout 层,其速率为 0.1 以减少过拟合,然后是一个具有等于我们标签类别数量(即 5)的神经元数量的密集层。 输出  在下一步中,我们将对训练集和验证集的句子进行分词,将标签设置为分类,然后继续进行模型训练。 输出  模型训练了 2 个 epoch,整个训练过程总共花费了 27 分钟 20 秒。 在验证集上进行评估我们将计算验证集上的错误指标,以了解模型的性能。 输出  输出  输出  为了生成分类报告和混淆矩阵,我们将矩阵转换为单个列,该列代表每行的 argmax。 输出  由于我们数据集中的类别不平衡,我们的预测严重偏向最常见的类别,在本例中是类别 2(“中性”)。因此,模型在预测类别 0 或 4 时的性能不佳,使其对这项任务几乎无用。在下面可以看到,这两个类别的大量错误分类是显而易见的。 输出  对于接下来的三个模型,我们将遵循与前一个模型相同的方法,并添加一些特定于每个模型的附加代码行。 Roberta 输出  输出  输出  模型完成了 2 个 epoch 的训练,耗时 26 分钟。 在验证集上进行评估输出  输出  输出  输出  该模型的整体准确率为 68%,加权平均 F1 分数为 69%。宏平均 F1 分数(平等对待所有类别)为 61%。这些指标表明,该模型在预测类别 2(中性)方面表现相对较好,这是数据集中最常见的类别。然而,对于类别 0(非常消极)和类别 4(非常积极),其性能较低,精度和召回率分数不如预期。可能需要进一步改进以提高模型的准确性,并平衡其在所有类别中的预测。 输出  DitstilBert输出  在 DistilBERT 的默认模型中,没有池化层可以直接将输出形状从 (None, 45, 768) 转换为 (None, 768)。为了获得所需的输出形状,我们将手动选择“层 0”的第一和第三个维度。后续层将与之前相同。 输出  输出  模型完成了 2 个 epoch 的训练,耗时 14 分钟。 在验证集上进行评估输出  输出  输出  输出  在此评估中,该模型实现了 68% 的准确率,表明它对数据集中 68% 的实例进行了正确预测。每个类别的精确率、召回率和 F1 分数是衡量模型对属于该类别的实例进行分类的性能的指标。 对于类别 0,精确率为 36%,这意味着当模型将实例预测为类别 0 时,只有 36% 的实例是正确的。召回率为 58%,这意味着模型识别出实际属于类别 0 的实例的 58%。F1 分数(同时考虑精确率和召回率)为 44%。 输出  XLNet输出  与 DistilBERT 模型类似,当前模型也需要将默认模型第一层的输出形状转换为所需的 (None, 768) 形状。为了实现这一点,我们使用了 tf.squeeze 函数。 输出  输出  模型完成了 2 个 epoch 的训练,耗时 31 分钟 16 秒。 在验证集上进行评估输出  输出  输出  输出  总的来说,该模型在测试集上取得了 69% 的准确率。类别 2(对应于“中性”情感)的精确率、召回率和 F1 分数最高,表明该类别表现良好。另一方面,类别 0(“非常消极”)和类别 4(“非常积极”)的精确率和召回率值较低,表明模型在准确预测这些类别时遇到了困难。所有类别的加权平均值显示了均衡的性能,但在不太常见的类别方面仍有改进空间。宏平均值考虑了数据集的不平衡性,其 F1 分数为 0.61,考虑到类别分布,表明性能尚可。 输出 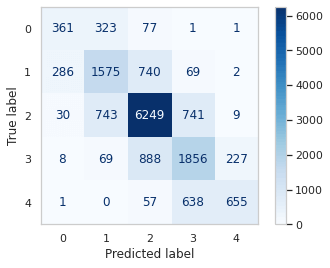 这四种模型的性能相当,表明 BERT 在准确性和训练时间之间取得了平衡。DistilBERT 是速度最快的模型,但其准确率低于其他模型,准确率约为 95%,而 BERT 则更高。另一方面,RoBERTa 和 XLNet 表现出最高的准确率,但训练时间也更长。HuggingFace 对 DistilBERT 准确率较低的解释是,它的准确率约为 BERT 的 95%。 结论机器学习中的情感分析已成为理解文本数据中表达的人类情感和观点的有力工具。它在从营销和客户服务到政治分析和市场研究的各个领域都有应用。随着机器学习的不断发展,情感分析领域必将实现更高的精度和深度,为明智的决策和丰富用户互动提供宝贵的见解。随着数据可用性的扩展和机器学习算法的不断改进,情感分析将继续在解读数字领域的情感方面发挥关键作用。随着技术的发展,情感分析提供有意义见解的潜力只会增长,从而加深我们对数字空间中人类情感的理解。 下一个主题使用机器学习的网络入侵检测系统 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
