机器学习中的客户流失预测2025年3月17日 | 阅读 14 分钟  客户流失(也称为客户流失)是指客户停止使用公司产品或服务的情况。 客户流失会影响盈利能力,尤其是在收入高度依赖订阅的行业(例如银行、电话和互联网服务提供商、付费电视公司、保险公司等)。据估计,获取新客户的成本可能高达保留现有客户的五倍。 因此,客户流失分析至关重要,因为它可以帮助企业
一系列机器学习技术,包括逻辑回归、决策树、随机森林、支持向量机和神经网络,被广泛应用于客户流失的预测。这些算法分析历史客户数据和相关特征,以开发能够有效地将客户分类为流失客户或非流失客户的模型。 代码 导入库输出  参数和变量拥有一些默认参数和变量会很方便。 函数由于我们将重用部分代码,定义一些函数会很有帮助。 导入数据集输出  我们的 DataFrame 包含 14 个特征/属性和 10,000 名客户/实例。最后一个特征“Exited”是目标变量,表示客户是否流失(0 = 否,1 = 是)。其余特征的含义可以从其名称中轻松推断出来。 特征“RowNumber”、“CustomerId”和“Surname”是客户特有的,可以删除。 输出  输出  我们的 DataFrame 中没有缺失值。 输出  最重要的事情是:
EDA 将帮助我们更好地理解我们的数据集。但是,在我们进一步查看数据之前,我们需要创建一个测试集,将其放在一边,并仅用于评估我们的机器学习模型。 分割数据集我们将使用 scikit-learn 的 train_test_split() 函数将数据集拆分为训练集和测试集,该函数实现了随机抽样。我们的数据集足够大(尤其与特征数量相比),因此我们不必担心引入抽样偏差。 输出  探索性数据分析目标变量(“Exited”)已编码,可以取两个可能的值:
输出 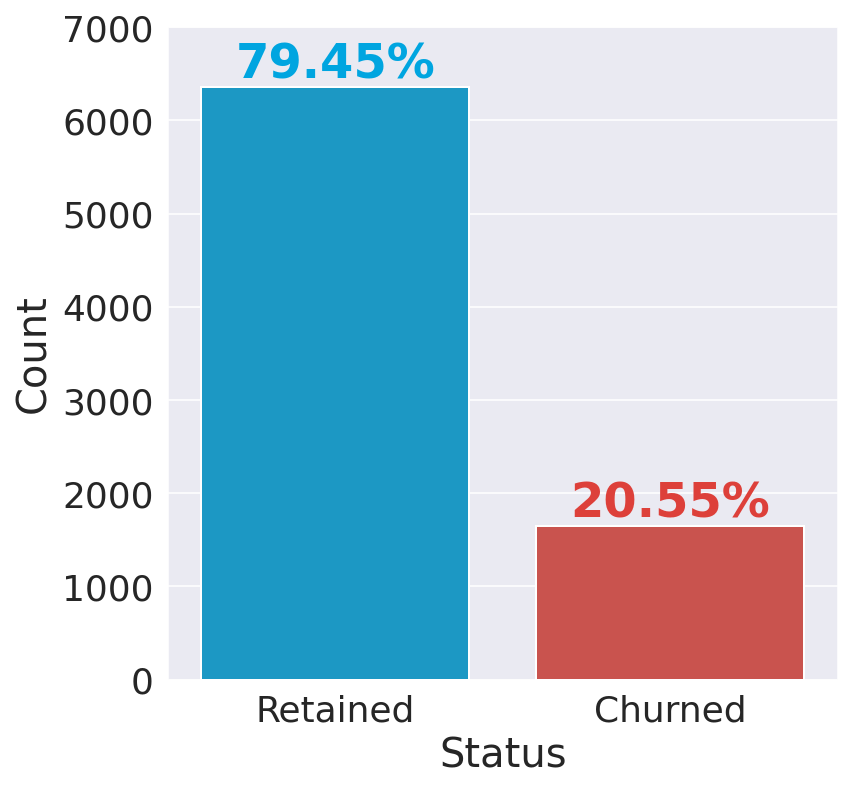 银行保留了 80% 的客户。 请注意,我们的数据集存在倾斜/不平衡,因为“保留”类别中的实例数量远多于“流失”类别中的实例数量。因此,准确性可能不是衡量模型性能的最佳指标。 不同的可视化技术适用于不同类型的变量,因此区分连续变量和分类变量并将它们分开查看会很有帮助。 输出  连续变量输出 
相关性我们将计算每对(连续)特征之间的标准相关系数。 输出  我们的特征之间没有显著的相互关联,因此我们**不必**担心多重共线性。 年龄输出  有趣的是,年龄组之间存在明显差异,因为年龄较大的客户更有可能流失。这一观察结果可能表明偏好随年龄而变化,而银行未能调整其策略以满足老年客户的需求。 信用分数输出  在信用分数方面,保留客户和流失客户之间没有显著差异。 余额输出 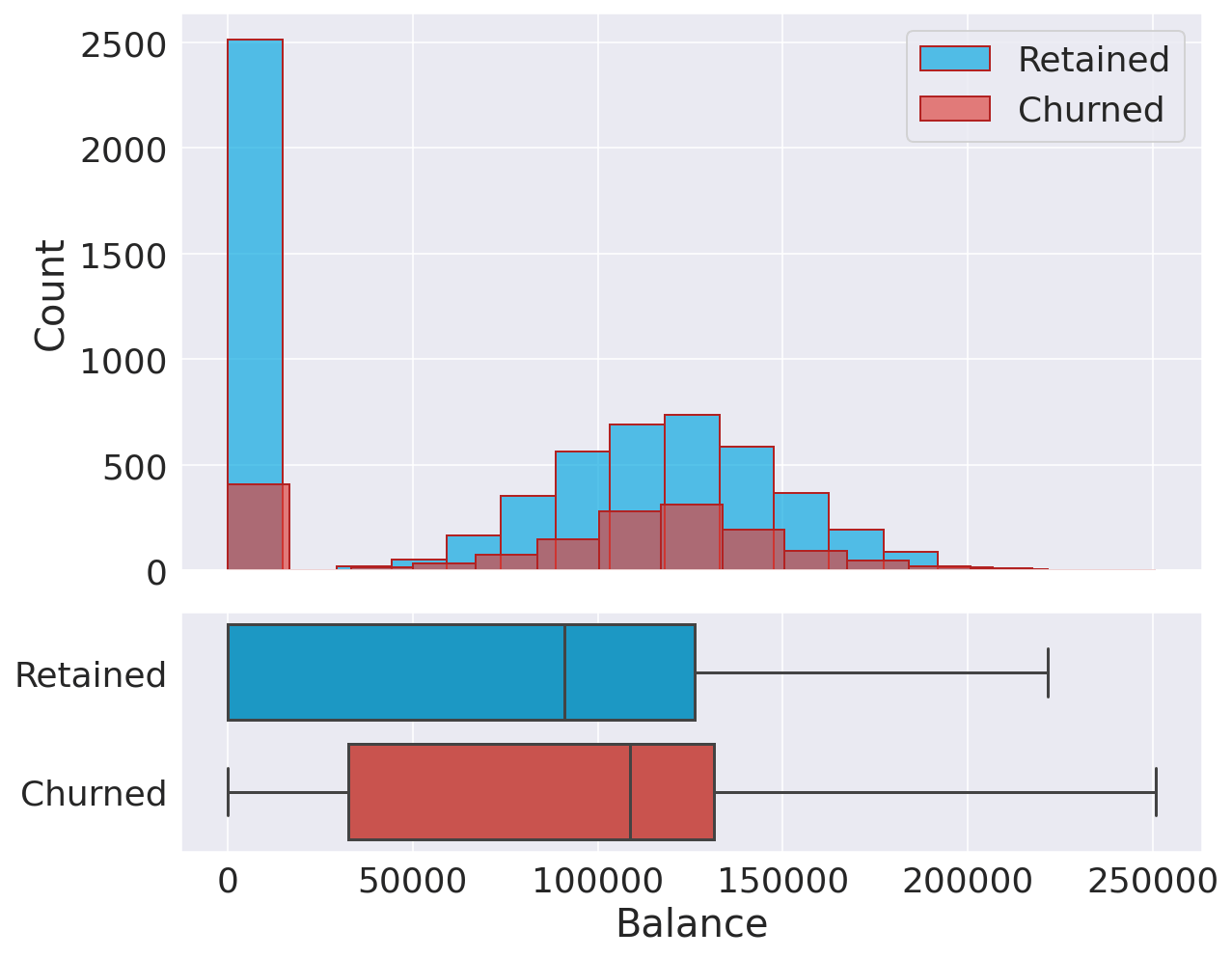 这两个分布非常相似。有很大比例的非流失客户账户余额较低。 估计薪资输出 无论是流失客户还是保留客户,其薪资分布都显示出相似的均匀分布。因此,我们可以得出结论,薪资对流失的可能性没有显著影响。 分类变量输出  要点
地理学输出  德国的客户比其他两个国家的客户更有可能流失(流失率几乎是西班牙和法国的两倍)。造成这一发现的原因有很多,例如竞争加剧或德国客户的偏好不同。 性别 (Gender)输出  女性客户更有可能流失。 客户保有期输出  客户保有期(年数)似乎不会影响流失率。 产品数量输出  有趣的是,拥有 3 或 4 种产品会显着增加流失的可能性。我不确定如何解释这个结果。这可能意味着银行无法妥善支持拥有更多产品的客户,从而增加了客户的不满。 持卡人输出  拥有信用卡似乎不会影响流失率。 活跃会员输出  不活跃客户更有可能流失,这不足为奇。相当一部分客户不活跃,因此银行将受益于改变其政策,使更多客户活跃起来。 数据处理数据预处理是将原始数据转换为易于阅读的格式,适用于构建和训练机器学习模型的流程。 特征选择EDA 揭示了几个可以删除的额外特征,因为它们对预测目标变量没有价值。
输出  “客户保有期”和“持有信用卡”的卡方检验值较小,p 值大于 0.05(标准截止值),证实了我们最初的假设,即这两个特征不包含任何有用的信息。 编码分类特征机器学习算法通常要求所有输入(和输出)特征都是数字。因此,在构建模型之前,需要将分类特征转换为(编码为)数字。 我们的数据集中有两个需要编码的特征:
缩放特征缩放是用于标准化数据集中特征范围的技术。 处理类别不平衡如前所述,待预测的类别存在不平衡,一个类别(0 - 保留)比另一个类别(1 - 流失)更为普遍。 输出  类别不平衡通常是一个问题,并且在许多现实世界的任务中都会发生。使用不平衡数据进行分类会偏向多数类,这意味着机器学习算法很可能会得到除预测最常见类别之外几乎无用的模型。此外,在处理类别不平衡数据时,常用指标可能会产生误导(例如,如果一个数据集中有 99.9% 的 0 和 0.01% 的 1,那么总是预测 0 的分类器将具有 99.9% 的准确率)。 输出  建模我们首先创建两个简单的模型来估计训练集上的基线性能。 输出  注意:我们可以使用更多(更强大)的分类器,例如随机森林或/和 XGBoost。然而,我们宁愿在这个阶段排除它们,因为它们的默认参数使它们更容易过拟合训练集,从而提供不准确的基线性能。1. 逻辑回归输出   2. 支持向量分类器输出   3. 随机森林分类器输出   4. 梯度提升分类器输出   5. XGBoost 分类器输出   6. LGBM 分类器输出   集成学习我们可以组合所有这些分类器的预测,以确定与每个单独的组成分类器相比,我们是否能获得更好的预测性能。这是集成学习背后的主要动机。 输出  特征重要性输出  “年龄”和“产品数量”似乎是所有分类器中最有用的特征,其次是“活跃会员”和“余额”。另一方面,“信用分数”是最不重要的特征,对于 LGBM 以外的所有估计器,其值都非常接近于零。 性能比较输出  输出  所有其他分类器的召回率都高于 70%(基线性能)。XGB 是召回率最高的模型(78.5%)。然而,LGBM 分类器具有最高的准确率、精确率和 AUC,整体性能最佳。 输出  虚线对角线代表纯随机分类器;一个好的分类器应尽可能远离该线(朝向左上角)。 在我们的案例中,除逻辑回归外,所有分类器的表现都相似。LGBM 的表现似乎略好,如稍高的 AUC(0.888)所示。 输出  此图显示,如果我们以模型预测的 50% 最有可能流失的客户为目标,模型将选出 80% 实际流失的客户,而随机选择只能选出 50% 的目标客户。 在测试集上评估输出  输出  输出  所有模型在测试集上的性能与训练集相似,这证明我们没有过拟合训练集。因此,我们可以预测客户流失,召回率约为 78%。 结论总而言之,使用机器学习进行客户流失预测是企业优化客户保留策略、提高客户满意度并推动长期增长的宝贵工具。通过利用机器学习算法的力量,企业可以深入了解客户行为,并采取主动措施来保留其宝贵的客户群。 下一主题使用机器学习进行地震预测 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
