理解多头注意力机制2025年7月30日 | 阅读8分钟 多头注意力是Transformer架构的一个重要组成部分,最初由Vaswani等人于2017年提出的著名论文《Attention is all you need》中引入。它极大地增强了模型并行识别输入序列不同部分的能力,因此在机器翻译、文本生成等序列应用中非常强大。 什么是注意力机制?在解释多头注意力之前,理解普通自注意力(也称为缩放点积注意力)的概念至关重要。 在自注意力中,输入向量序列被用于计算注意力分数,显示序列中的每个元素应该在多大程度上关注其他元素。这个过程涉及三个关键要素:
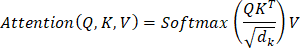 什么是多头注意力?多头注意力是自注意力机制的扩展,因为它使模型能够同时关注表示的不同子空间中包含的信息。它通过将输入分解为多个“头”来实现这一点,这使得模型能够描绘出序列中更广泛的关系和模式。 每个头的工作方式如下: 线性变换 通过使用不同的学习到的权重矩阵,将输入X线性投影到多个降维子空间,形成几组查询(Q)、键(K)和值(V)。 独立注意力计算 各个头分别在其各自的Q、K和V矩阵上执行缩放点积注意力。这将使不同的头能够关注序列的不同方面。 拼接 每个注意力头的输出在特征维度上被连接起来。 最后的线性变换 这个连接后的输出被馈送到另一个线性层,以生成与输入模型时具有相同维度的最终输出(即恢复到原始嵌入维度)。 Transformer中的多头注意力多头注意力是Transformer模型应用的关键部分,用于执行以下操作: 1. 编码器自注意力 使编码器能够学习输入序列中所有词之间的上下文关系,无论它们的位置如何。 2. 解码器自注意力 允许解码器一方面关注先前生成的输出的相关部分,同时保持自回归约束(即不超前)。 3. 编码器-解码器注意力 使解码器能够关注编码器的输出,以便能够根据输入序列做出上下文相关的预测。 为什么多头比单头更好?与单头注意力相比,多头注意力具有许多重要的优势:它为现代深度学习架构提供了重要的功能。 1. 捕捉多方面特征 每个头关注输入的不同区域的能力,使得模型能够学习更广泛的模式和关联。例如,一个头可能学习局部依赖关系,而另一个头可能学习长距离交互。这种多样性使模型更具代表性,更能学习复杂数据。 2. 增加焦点分配 多个头允许将注意力更均匀地分配到整个输入序列。这使得模型不会过度关注有限数量的token,而是以更平衡的方式进行关注。因此,模型对整个序列有更广泛的感知。 3. 减轻过拟合 拥有多个头可以带来一种自调节的元素。让模型从不同视角学习可以减少记住训练数据集特定部分的倾向。这有助于更通用的学习,并提高在未见过样本上的性能。 4. 更好的多尺度洞察 不同的注意力头可以获取不同抽象层次的信息。一个头可能关注词级别的关联,而另一个头可能捕捉更大范围的句子或段落级别的上下文。这种多尺度视图尤其适用于需要细粒度和高级知识的任务。 5. 改善梯度流和训练稳定性 多头注意力通过信息处理的多种途径,改善了训练过程中的梯度流。这可以避免梯度消失或爆炸,从而在许多情况下使训练更稳定并更快地收敛。 6. 并行处理和性能 由于没有显著的额外计算成本,注意力头可以并行使用,以一次性提取多个特征。通过有效的设计,在增加头数的同时,性能指标可以提高,而不会损失性能、速度或规模。 如何在PyTorch中使用多头注意力?由于存在nn.MultiheadAttention模块,在PyTorch中实现多头注意力只需一行代码即可。 示例 1 输出 Output shape: torch.Size([10, 2, 64]) 示例 2 输出 Output shape: torch.Size([5, 3, 128]) 示例 3 输出 Output shape: torch.Size([6, 4, 32]) 多个注意力头的优势多头注意力是一项关键贡献,它使Transformer模型能够获得更好的性能和更高的灵活性。 1. 促进广泛的关系 不同的注意力头能够关注输入序列的不同元素,这使得在学习过程中能够分析各种依赖关系和交互。 2. 高效学习 模型通过基于不同子空间的并行流计算注意力,从而学习到输入更复杂、更细微的表示。 3. 增强鲁棒性 多个头减少了模型过度依赖一种注意力类型的风险。因此,它们不太可能过拟合。 4. 更好的泛化能力 在训练过程中看到了多个视角后,模型在未见过的数据上能更好地泛化。 5. 辅助复杂模式识别 既有局部上下文的头,也有长程上下文的头,它们增强了对分层和结构化信息的理解。 6. 改进的表现力 多头注意力赋予模型更强的表示能力,因为它能够学习单头注意力会丢失的更复杂的关系。 多头注意力的应用多头注意力是一种有效的工具,由于其能够对数据中的复杂依赖关系进行建模,因此被广泛应用于许多领域。一些主要应用包括: 1. 机器翻译 多头注意力在Google Translate等翻译模型中非常有用,因为它允许这些模型同时关注句子中的不同单词。这提高了生成输出的质量和流畅度。 2. 文本摘要 通过关注最重要的部分,它允许模型提取长文本中的重要信息,并合成简短、有意义的摘要。 3. 对话式AI和聊天机器人 多头注意力确保聊天机器人能够理解多轮对话的上下文,从而使它们对客户的响应更加恰当和自然。 4. 视觉Transformer (ViT) ViT对图像块而不是传统的卷积使用多头注意力。这使得模型能够学习图像不同元素之间的连接,使其适用于图像分类或对象检测等任务。 5. 图像字幕 在图像字幕中,多头注意力被用来帮助模型将语言和视觉特征关联起来,对图像的关键区域进行关注,从而生成描述性和有用的字幕。 6. 图像分割 为了识别不同的对象或区域,模型依赖于多头注意力,它被用于突出图像的特定区域。这使得医学成像或场景解释等详细视觉分析任务更加准确。 7. 语音转文本 更先进的语音转文本版本,如OpenAI的Whisper,就采用了多头注意力。它有助于模型将音频属性与相关文本匹配,使转录准确流畅,即使在高噪声或多语言环境下。 8. 语音助手 Siri或Alexa等语音助手中的多头注意力通过保持上下文,有助于更好地理解用户的询问。这导致更准确的解释和更自然的对话流程,使其回应更加相关。 结论多头注意力是一项主要贡献,它提高了Transformer模型的性能,因为它们能够同时专门化处理输入中的不同区域。它能推广到许多子空间,关注各种特征,并帮助模型更好地泛化。这使得它在NLP、计算机视觉等领域的应用取得了巨大成功。 对于设计高级深度学习应用程序的人来说,学习多头注意力的原理是必不可少的。我建议进行的一项实验是尝试不同的配置以及它们如何影响结果。如果您有任何问题或想法,都可以分享,之后会有新的机器学习见解。 下一主题如何检查机器学习模型的准确性 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
