机器学习中的电力消耗预测2024年11月13日 | 阅读 16 分钟  在当今快节奏的世界中,电力消耗在满足现代社会能源需求方面占有至关重要的地位。随着对电力需求的不断增长,优化能源使用变得极其重要。幸运的是,技术的进步促使机器学习的出现,这是一种能够以惊人的准确性预测电力消耗的强大工具。 预测电力消耗是一项复杂的任务。它需要分析大量的历史数据,例如过去的电力使用情况、天气模式、一天中的时间以及季节性变化。虽然传统方法提供了一些见解,但它们通常难以捕捉这些变量之间错综复杂的联系。 机器学习,作为人工智能的一个分支,使计算机能够从数据中学习并进行预测,而无需显式编程。机器学习算法在从海量数据集中发现隐藏模式和相关性方面表现出色,使其成为电力消耗预测的理想选择。 使用机器学习进行电力消耗预测的优势使用机器学习进行电力消耗预测具有许多优势,可以彻底改变我们管理和优化能源资源的方式。一些主要优势包括:
使用机器学习进行电力消耗预测的挑战使用机器学习预测电力消耗也伴随着挑战。虽然机器学习提供了有前景的解决方案,但了解在此过程中可能出现的障碍至关重要。一些主要挑战包括:
关于数据集该数据集是西班牙 2014 年至 2018 年电力需求、发电和价格的每日时间序列。它来自 ESIOS,这是一个由 REE(Red Electrica Española,西班牙传输系统运营商)管理的网站。 TSO 的主要职能是运行电力系统并投资于新的输电(高压)基础设施。 (https://www.ree.es/en/about-us/business-activities/electricity-business-in-Spain) 作为系统运营商,REE 预测电力需求并提供和运行日常操作。作为日常操作的结果,会产生 PBF(基本运行计划)。这是一个基本的发电调度(在此基础上,会触发各种机制来确保供应)。 能源和价格数据可从以下网址下载:https://www.esios.ree.es/en OMIE(Iberian Electricity Market Operator)负责运行这些日常操作,并提供有趣的数据。 http://www.omie.es/en/inicio 内容保留原始值,因此显示了一些西班牙语名称。列名描述了每个时间序列,因此我提供了每个名称的描述。
注意:保留了原始数据格式,以防需要附加从 Esios 下载的新数据。因此,地理列为空。代码导入库读取数据集输出  输出  输出  输出  我们很幸运!数据集中没有缺失值,并且有四年的数据可供我们使用。现在,让我们深入研究令人兴奋的部分,并计算一些与日期相关的特征,以使我们的分析继续进行。 输出  EDA(探索性数据分析)分析目标变量涉及研究其季节性和趋势。我们的目标是直观地理解时间序列数据的模式和波动,而无需过多依赖分解等统计技术。通过图形化检查数据,我们可以深入了解可能存在的潜在模式和趋势。 目标分析(正态性)输出  在数据分布方面,负偏度表明数据并非完美对称,并且具有较长的左尾。此外,低于 3 的峰度值表明与正态分布相比,分布的尾部略薄。这种特性被称为“低峰度”,表明遇到极端值的可能性比正态分布低。 输出  输出  总的来说,数据不呈现正态分布,因为它显示出比正态分布数据更短的左尾和更低的观察极端值的可能性。 输出  输出  输出  输出  在考虑季度和月份等较短时间段时,波动性趋于变化,但在长期(年度窗口)内,波动性相对稳定。因此,潜在的预测因子需要考虑方差中的季节性模式。 输出  输出  输出  正如预期的那样,在考虑季度和星期几(星期一表示为 0)时,数据中观察到了明显的季节性模式。 输出  输出  输出  能源需求显示出积极的线性趋势,或略微衰减的趋势,这可归因于从衰退中复苏带来的稳定经济增长。 特征工程当前的挑战在于开发能够有效处理季节性、趋势和波动变化的自动化特征。这些特征应能够适应数据中观察到的不断变化的模式和波动。 标准化数据是应用对尺度敏感的模型(如神经网络或支持向量机 (SVM))的必要步骤。通过标准化数据,我们确保分布形状保持不变,而仅改变第一个和第二个矩,即均值和标准差。此过程允许使用这些特定的机器学习算法对数据进行更准确有效的建模。 输出  输出  输出  一些特征,例如 AR_6(自回归滞后 6)和 MOVAVE_7(7 天移动平均),与目标变量表现出相对较强的线性相关性。为了验证此假设并进一步研究其预测能力,我们将构建各种模型并使用这些特征来评估它们的性能。通过评估模型的准确性和预测能力,我们可以确定这些特征在多大程度上为模型的整体预测能力做出了贡献。 模型构建在此步骤中,我们使用 Scikit-Learn 中的一个方便的特征 MultiOutput Regression 构建了两个候选模型。此功能允许我们高效地自动拟合能够同时预测多个目标变量的模型。通过利用此框架,我们可以以简化的方式训练模型来预测多个目标变量。这不仅简化了建模过程,而且使我们能够有效地评估模型在多个目标上的性能。 首先,我们将使用线性回归拟合一个基线模型,并将其与更高级的模型(如随机森林)进行比较。线性回归模型不需要广泛的超参数调优,并为我们的分析提供了坚实的基础。但是,有几个考虑因素需要牢记:
另一方面,像随机森林这样的高级模型需要仔细的超参数调优才能实现最佳性能。通常,这是使用 GridSearch 和交叉验证 (CV) 等技术完成的。然而,使用传统的 CV 方法处理时间序列数据会带来挑战。这是因为数据不应该被打乱,因为它遵循特定的时间结构。 幸运的是,Scikit-Learn 提供了一个有用的解决方案,称为 TimeSeries Split。这项技术允许我们在时间感知的方式下执行 GridSearch,方法是保留数据的时序顺序。它将数据分成按时间顺序排列的折叠,确保每个折叠都尊重观测值的时间顺序。 通过使用 TimeSeries Split,我们可以通过不同的超参数组合来迭代地训练和评估我们的随机森林模型。这种方法使我们能够找到最大限度地提高模型在未见过的未来数据点上性能的最佳超参数集。 以时间感知的方式应用超参数调优对于时间序列数据至关重要,因为它确保了我们模型的性能更加现实和可靠。通过利用 Scikit-Learn 中的 TimeSeries Split 功能,我们可以有效地优化我们的随机森林模型,而不会违反数据的时序结构。 输出  数据拆分为了确保对我们模型性能的无偏评估并进行彻底的残差分析,我们将 2018 年的数据点保留为一个单独的保留数据集。这意味着我们在模型开发过程中不会触碰这些数据。 输出   基线模型:线性回归输出  使用时间序列拆分训练随机森林以调优超参数在此特定示例中,我们演示了 TimeSeriesSplit 框架的使用。通过这种方法,每个数据折叠的构建方式使得训练数据更接近预测周期的开始。 输出    输出  与线性回归相比,使用随机森林可以显著提高性能。但是,必须谨慎行事,因为随机森林模型是通过对数据进行自举来构建的,这可能会导致数据集丢失一些时间结构。 特征重要性输出  模型结果与相关性分析的结果不符,这凸显了复杂关系和交互对模型性能的影响。这一点至关重要,尤其是在处理 ARIMA 等模型时。 模型评估在评估模型性能时,选择平均绝对百分比误差 (MAPE) 作为性能指标,而不是常用的均方根误差 (RMSE)。MAPE 被认为更适合此分析,因为它更容易理解和沟通。MAPE 将使用一个周期的超前模型来计算测试周期。 输出 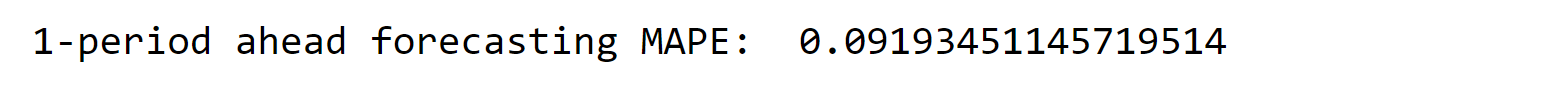 输出  MAPE 值略高于 10%,考虑到电力需求与天气状况的高度相关性,这非常出色。此外,重要的是要注意,二月份经历了异常寒冷的气温,这使得结果更加惊人。 输出  通过绘制实际值与预测值,我们可以直观地评估模型拟合训练数据并将其泛化到测试数据的能力。 残差分析输出  输出  输出  预测多周期超前模型构建一旦确定了最佳的超参数集,我们就可以使用最新和最相关的数据训练一个新的随机森林模型实例。通常,建议至少有两年的数据来生成长期的每日预测。让我们继续使用 MultiOutput Regression 功能重新训练一系列随机森林模型。 最后,重要的是评估多个周期的预测准确性,使用 MAPE(平均绝对百分比误差)指标,并确定其是否保持一致和稳定。 输出  输出  正如预期的那样,在考虑较短周期时,预测准确性会提高。值得注意的是,拥有更多数据并不总是保证更好的结果。此外,MAPE 随着预测范围的扩大而趋于增加,但总体而言,它显示出相对稳定的模式。 实际值 vs. 预测值如前所述,评估模型拟合的便捷方法是绘制实际值与预测值,并检查数据点的分布。 输出     很明显,随着预测周期的延长,数据点的分散度增加,尤其是对于极端值。 预测 30 天输出  输出  机器学习的未来展望机器学习在能源行业具有巨大的潜力。通过分析包括电力使用、天气模式和季节性变化在内的海量历史数据,机器学习算法可以提供准确的预测。像变量之间复杂的相互作用等挑战正通过先进的技术得到解决。该领域的未来看起来充满希望,准确性不断提高,物联网和智能电网数据不断整合,以及实时预测分析。这将实现高效的能源分配、需求侧响应以及可再生能源的无缝整合。此外,机器学习将支持能源基础设施的预测性维护,并促进能源节约和可持续发展。人工智能与人类专业知识的合作至关重要,透明的人工智能模型将建立信任和责任感。总而言之,机器学习将彻底改变能源行业,并为更可持续、更高效的能源生态系统铺平道路。 结论使用机器学习进行电力消耗预测是能源行业的一项游戏规则改变者。通过利用数据和高级算法的力量,我们正在为高效的能源管理和更绿色的明天解锁新的可能性。随着机器学习的不断发展,我们可以期待一个电力消耗将变得更加可持续、经济实惠和环保的未来。拥抱这种尖端方法将为更光明、更可持续的能源未来铺平道路。 下一主题数据分析与机器学习 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
