Softmax 分类器简介2025 年 8 月 11 日 | 4 分钟阅读 在机器学习中,特别是在分类问题中,Softmax 分类器在将模型的原始输出转换为概率方面发挥着重要作用。它经常用于多类分类问题。本文将探讨 Softmax 分类器以及如何使用它来解决分类任务。 理解 Softmax 函数它是一个数学函数,将实向量转换为概率分布。输出中的每个值都在 0 到 1 的范围内,并且所有概率的总和等于 1,这使得它在解决分类任务时非常有效,因为需要知道给定输入属于某个类别的概率。 Softmax 函数的公式 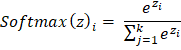 其中
Softmax 分类器的工作原理在此分类器中,神经网络的输出是每个类别的分数向量。这些分数向量,也称为 logits,然后传递给 softmax 函数,该函数将这些值转换为概率。具有最高概率的类别被选作模型预测。 考虑一个将蔬菜图像分为三类(土豆、番茄、洋葱)的示例,神经网络的分数可能是 [2.5, 1.5, 0.3]。这些值在 Softmax 函数中传递后,分数可能变为 [0.6, 0.3, 0.1],这意味着图像是土豆的概率为 60%,番茄的概率为 30%,洋葱的概率为 10%。 损失函数:交叉熵Softmax 分类器与交叉熵损失函数一起使用,该函数测量预测值与真实值之间的误差。交叉熵的公式如下: 公式 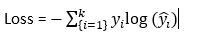 其中,
Softmax 函数与交叉熵损失相结合,使模型能够惩罚不正确的预测;另一方面,它确保总概率等于 1。 使用 Numpy 实现 Softmax 分类器让我们看看使用 NumPy 实现 Softmax 分类器,通过手动计算梯度进行多类分类。 Softmax 函数代码 函数 sm 接受输入 X,并根据公式计算 e,并返回 softmax logits。 交叉熵损失代码 ce_loss 函数分别接受预测值和实际值作为 p 和 a。计算样本数量,计算对数似然,并计算最终损失。 Softmax 分类器(训练)代码 示例 SMClassifier 类包含一个使用梯度下降的训练方法,以及一个用于根据学习到的权重预测新输入的预测方法。 完整代码 输出 Epoch 0 - Loss: 1.6008724162725934 Epoch 100 - Loss: 0.976989081975411 Epoch 200 - Loss: 0.8937152993270043 Epoch 300 - Loss: 0.8277133368313195 Epoch 400 - Loss: 0.7735497843862071 Epoch 500 - Loss: 0.7283645493979359 Epoch 600 - Loss: 0.6900568088174213 Epoch 700 - Loss: 0.6570874495324227 Epoch 800 - Loss: 0.6283231377613413 Epoch 900 - Loss: 0.6029210360252443 Predictions: [0 0 1 1 2 2] Softmax 分类器的应用Softmax 函数用于解决各种分类任务。
Softmax 分类器的优点
Softmax 分类器的局限性
|
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India

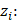 表示模型的第 i 个概率。
表示模型的第 i 个概率。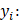 表示实际值
表示实际值 表示给定第 i 个类别的预测值。
表示给定第 i 个类别的预测值。