注意力机制2025年3月17日 | 阅读 10 分钟 就像在“注意力”中一样,在现实生活中,当我们看一张图片或听音乐时,我们通常会对某些部分给予更多关注,而对其他部分给予更少关注。深度学习中的注意力机制遵循相同的趋势,在处理输入时更多地关注输入的特定区域。注意力是网络架构的一个组成部分。 如果您遵循指定的任务,编码器和解码器将是不同的。在机器翻译中,编码器通常设置为 LSTM/GRU/Bi_RNN,但在图像字幕中,编码器通常设置为 CNN。 翻译句子:“le chat est noir”到英语句子(这只猫是黑色的)输入由四个单词和一个结尾的 EOS 标记(一个停止词)组成,相当于翻译成英语的五个步骤。注意力在每个时间步通过给输入单词分配权重来应用;更重要的单词被赋予更大的权重(使用反向传播梯度过程)。因此,分配了 5 个不同的时间权重(对应 5 个时间步)。以下是 seq2seq 的通用架构  没有注意力机制时,解码器中的输入由两部分组成:初始解码器输入(通常首先设置为 EOS 标记(起始词))和最终隐藏编码器。这种方法的缺点是,在处理过程中,可能会丢失来自第一个编码器单元的一些信息。为了解决这个问题,注意力权重被应用于所有编码器输出。  正如我们所看到的,编码器输入的注意力权重颜色会随着每个解码器输出词的重要性而不同地改变。 您可能想知道我们如何才能正确地加权编码器输出。解决方案是,我们只是随机设置权重,反向传播梯度机制将在训练期间处理它。我们必须做的是正确构建前向计算图。  计算注意力权重后,我们有三个组成部分:解码器输入、解码器隐藏层和(注意力权重 * 编码器输出),我们将其输入解码器以返回解码器输出。 注意力分为两种类型:Bahdanau 注意力和 Luong 注意力。Luong 注意力是在 Bahdanau 注意力的基础上构建的,并在各种活动中表现出卓越的性能。这个内核以 Luong 的注意力为中心。 Luong 注意力的计算图 步骤 1:计算编码器隐藏状态步骤 2步骤 3:研究注意力类并计算对齐分数Luong 注意力中有三种计算对齐分数的方法(点积、通用和连接)。
实现注意力类为了更好地理解,我们现在将使用注意力机制实现一个翻译系统 代码 导入库输出  数据预处理输出  输出  在这里,我们将定义用于预处理英语句子的函数 在这里,我们将定义用于预处理葡萄牙语句子的函数 现在,我们将生成带有起始和结束标记的干净的英语和葡萄牙语句子对。 输出  现在,我们将创建一个类,用于将每个单词映射到索引,反之亦然,适用于任何给定的词汇表。 分词和填充分割数据集输出  GRU 单元我们将使用 GRU 而不是 LSTM,因为我们只需要创建一个状态,并且实现会更容易。 编码器的输入将是英语句子,输出将是 GRU 的隐藏状态和单元状态。 下一步是定义解码器。解码器将有两个输入:来自编码器的隐藏状态和单元状态,以及输入句子,它实际上将是开头附加了一个标记的输出句子。 现在,我们将从各自的类中创建编码器和解码器对象。 在这里将定义优化器和损失函数。 训练在这里我们将不得不训练我们的模型。 输出   测试输出  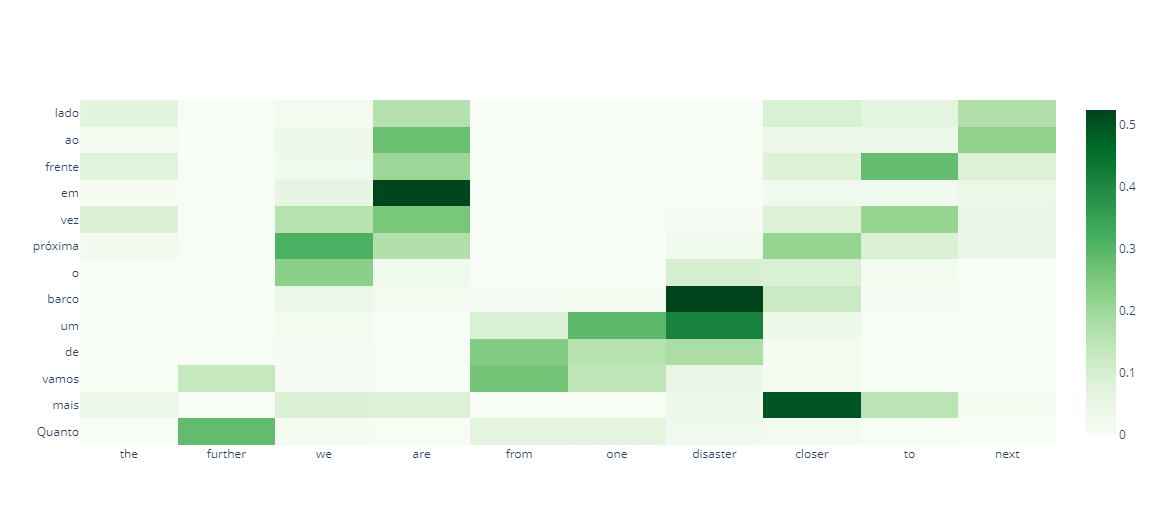 输出   输出   输出   经过一段时间,我们可以看到模型正在改进。 下一主题反向传播算法 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
