StandardScaler、MinMaxScaler 和 RobustScaler 技术2025年6月24日 | 阅读 8 分钟 特征缩放是机器学习中的一种过程,其中数值数据被适当地分布,以便能够高效地学习模型。许多算法在具有适当归一化特征时效果最佳,特别是那些基于距离度量的算法,例如 K 近邻、支持向量机和梯度下降优化。最常见的三种特征缩放类型是 StandardScaler、MinMaxScaler 和 RobustScaler,它们适用于不同的分布。 StandardScaler 是一种重要的标准化技术,它使数据围绕均值进行去中心化,并保持单位方差;它使整个数据集的均值为 0,标准差为 1。它通常适用于假设数据集服从正态分布的算法:逻辑回归、支持向量机 (SVM) 和主成分分析 (PCA)。MinMaxScaler 将原始数据从最小值线性重缩放到最大值,通常在 0 到 1 之间。它在不改变原始值之间的关系的情况下,非常适合需要输入值限制在特定范围内的模型,例如神经网络和 KNN。然而,由于它基于数据的最小值和最大值,因此此方法对离群值更敏感。RobustScaler 是一种 Scikit-learn 中的缩放器,可以在包含离群值的数据集上使用,它不是使用均值和标准差进行缩放,而是关注四分位距 (IQR) 方法。简单来说,RobustScaler 对极端值或离群值的存在具有鲁棒性。该技术是处理可能严重扭曲缩放的离群值数据集(例如金融或传感器数据集)的更好选择。 选择正确的缩放技术取决于您的数据集和将使用的机器学习算法。StandardScaler 适用于近似正态分布的数据;MinMaxScaler 适用于有界数据;RobusScaler 用于离群值会影响缩放机制的数据集。当使用合适的方法时,模型性能会得到提升,因此它是预处理步骤中的一个重要部分。 代码 输出  让我们看一下头部。 代码 输出  让我们检查可用资源。 代码 输出  用于附加的汇总统计信息。 代码 输出  让我们绘制一张图。 代码 输出  添加值更大的特征 代码 输出 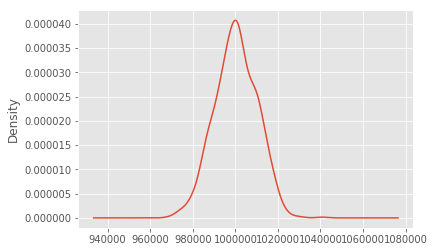 这里,均值是正常的大的。 代码 输出 1000258.722664037 我们的分布相当正常,均值约为 1,000,000。如果与原始分布一起显示,最早的列甚至不可见。 代码 输出 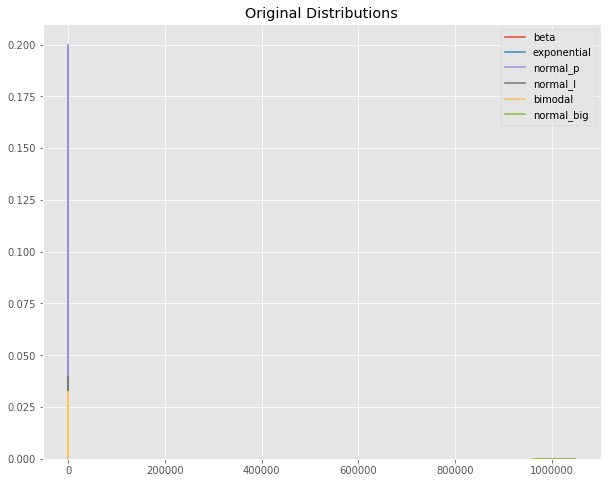 最右边是新的、高价值的分布。这里可以找到值的图。 代码 输出  再次是数据的摘要。 代码 输出  MinMaxScalerMin-Max 是最常用的缩放技术,用于将数值数据拟合到 0 和 1 之间的特定范围。此技术确保零均值,这意味着所有特征具有相同的范围,从而确保没有变量可以因为其大小而主导其他变量。它主要用于应用需要计算距离的机器学习算法时,例如 k-nearest neighbor 和基于梯度下降的模型,如神经网络。 Min-max 缩放保留了数据点之间的关系,同时标准化了它们的比例,从而保留了分布的原始形状。因此,当一个人希望保留数据的可解释性时,这种方法是理想的。此技术的主要缺点是它对离群值敏感。事实上,Min-Max 仅基于最小值和最大值来故意缩放数据,即使是少数离群值也会极大地扭曲转换后的数据集,从中只有很少的模型可以令人满意地执行。 代码 输出  观察每个分布的形状如何保持不变,但值现在在 0 到 1 的范围内。 MinMaxScaler 后的最小值。 代码 输出 0.0 MinMaxScaler 后的最大值。 代码 输出 1.0 在缩放之前,让我们检查每列的最小值。 代码 输出  在缩放之前,让我们检查每列的最大值。 代码 输出  在 MinMaxScaler 之后,让我们检查每列的最小值。 代码 输出 [0.0, 0.0, 0.0, 0.0, 0.0, 0.0] 在 MinMaxScaler 之后,让我们检查每列的最大值。 代码 输出 [1.0, 1.0, 1.0000000000000002, 0.9999999999999999, 1.0, 1.0] RobustScalerRobustScaler 是一种特征缩放方法,特别适用于处理包含离群值的数据集。与可能因极端值而波动的 MinMaxScaler 不同,RobustScaler 使用中位数和 IQR 转换的绝对值,因此它对离群值的感知度较低。因此,它有利于在其中极端值会扭曲缩放过程的数据集,从而对学习模型产生负面影响。 RobustScaler 的最大优点是它将数据围绕中位数而不是均值进行了中心化,因此由离群值引起的大偏差不会不成比例地影响缩放后的值。尽管如此,这对于包含异常值或不规则模式的实际数据集非常有帮助。另一方面,这不会像 MinMaxScaler 那样将值限制在某个特定范围内;因此,转换后的数据可能仍然包含很大的值,但那些值实际上并未受到扭曲的影响。 代码 输出  在 RobustScaler 之后,让我们检查每列的最小值。 代码 输出  在 RobustScaler 之后,让我们检查每列的最大值。 代码 输出  双峰分布的值现在被压缩到两个小组中,并且每个特征的值范围比 MinMaxScaler 更宽、变化更大,但仍然明显小于原始特征。 StandardScalerStandardScaler 是一种常用的特征缩放技术,通过将数值数据中心化为零均值和单位方差来对其进行标准化。这使得每个特征的均值为零,标准差为一,因此它对于假设数据服从正态分布的任何算法(如线性回归、支持向量机和主成分分析)特别有用。 StandardScaler 的主要优点在于,在对不同特征的比例进行归一化时,它能保留分布的原始形状。这使得机器学习模型能够更有效地运行,因为它避免了某些特征由于数量级范围宽而对模型产生非常高影响的情况。虽然 MinMaxScaler 在定义的范围内缩放值,但 StandardScaler 保留了数据点之间的相对关系,使其能够有效地处理没有大量离群值的数据集。 代码 输出  在 StandardScaler 之后,让我们检查每列的最小值。 代码 输出  在 StandardScaler 之后,让我们检查每列的最大值。 代码 输出  范围与 RobustScaler 非常相似。 NormalizerNormalizer 是一种特征缩放方法,适用于其中每个特征独立转换的数据集,使得数据集中的每个单独样本都具有单位范数。我们将 Normalizer 与其他关注特征的缩放方法进行比较,例如 StandardScaler、MinMaxScaler 和其他处理行缩放的方法,并确保每个数据点都根据其幅度进行调整。这种处理方式在处理文本分类、基于余弦相似度的模型开发以及某些机器学习算法(如 K-Nearest Neighbors (KNN) 和聚类)等底层问题领域时非常有用。 Normalizer 的主要优点在于数据需要分散开,并且方法会抑制尺度比较,因为单个样本的幅度差异很大。当数据集具有截然不同的特征值时,这一点非常有用。对每个观测值进行归一化可以使模型稳定且高效,尤其是在高维数据的情况下。 代码 输出  在 Normalizer 之后,让我们检查每列的最小值。 代码 输出  在 Normalizer 之后,让我们检查每列的最大值。 代码 输出  此外,Normalizer 将特征调整到了可比较的尺度。观察我们值相当大的特征现在如何被分组到一个非常小的范围内。9999999999。 总而言之,让我们检查我们原始和修改后的分布。Normalizer 将不包含在内,因为在大多数情况下,您希望更改特征而不是样本。 代码 输出  显然,在任何更改之后,分布都处于可比的尺度上。此外,观察 MinMaxScaler 没有扭曲每个特征中值之间的距离。 下一个主题使用机器学习检测网络钓鱼网站 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
