统计数据分布2025年3月2日 | 13 分钟阅读 在统计学研究中,数据的分布方式决定了可能做出的决策或预测。统计学中的分布是指数据点从低值到高值的散布情况。它给出了数据集中的模式、趋势和离散度,从而使研究人员、分析师或决策者能够得出有意义的结论。 分布有多种形式,从具有其广为人知的对称钟形曲线的正常分布,到更专业的类型,如二项式、泊松和伽马分布。每种分布类型都模拟不同种类的数据和现象,从而详细说明各种结果的可能性。对这些分布的分析使研究人员能够就事件的概率得出推论,详细说明趋势,并理解生成数据的潜在过程。 无论是计算某事发生的几率、评估风险还是进行预测,统计分布基本上是这些活动中固有的概念。数据分布的类型、其特征以及在实际情况中的应用领域构成了本统计实践介绍中进行更深入分析和理解的基础。现在我们将看到每种类型的统计数据分布。 导入库正态分布正态分布是最容易识别的统计分布,因为它出现在许多自然现象中。正态分布变量的一个非常重要的特征是其均值,它给出了最高的频率。接近均值的值比其他值更有可能;一个值偏离均值越多,它出现的概率就越小。正态分布的另一个重要特性是它围绕均值对称。较高和较低的值以相同的频率出现。 正态分布在自然界中无处不在。以下是一些正态分布的例子:
这些分布涉及离散的组或上下文。热带地区的温度分布将与极地地区不同,就像简单和困难考试之间的分数分布会不同一样。这些例子都指出了日常生活中物体和现象的正态分布,作为查看和预测任何数据集可能存在的变异的基础。 现在,我们将绘制正态分布图。 输出  伯努利分布伯努利分布以雅各布·伯努利命名,是一种在自然界中经常观察到的分布类型。它描述了恰好有两种可能结果的场景。这种离散概率分布允许伯努利随机变量 (x) 只取值 0 或 1。日常生活中伯努利分布的一些例子包括:
在伯努利分布中,p 表示成功的概率,而 1-p 表示失败的概率。伯努利分布的均值由以下公式给出: E[X] = p,方差为 Var[X] = p(1-p)。  输出  由此可知,一个技术不佳的弓箭手命中靶心的概率为15%,未命中目标的概率为85%。 现在,我们将以抛硬币的概率为例。因此我们的 p 将是 0.5。 输出 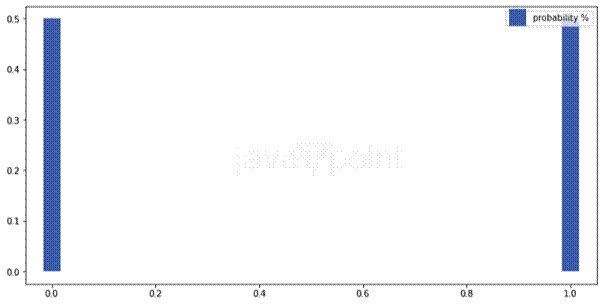 然而,在伯努利分布中,p 的值(0.5)可以变化。考虑另一个例子:篮球运动员罚球命中的概率也可以用伯努利分布来描述。最初,似乎投中或不投中各有 50/50 的机会,使其成为一个两结果场景。但是,对于技术不佳的球员来说,成功概率可能低至 0.2。 这里,我们再来看一下,但是我们的 p 将是 0.7。 输出  二项分布另一种离散概率分布,二项分布处理变量在多次试验中取两个独立值之一或 1 的概率,由一组参数 n 定义。通过进行多次伯努利试验,我们推导出二项分布。重要的是,每次试验必须完全独立于其他试验,并且每个结果——例如 0 或 1——以固定的概率发生。成功具有概率 p,而失败具有概率 1-p。 需要注意的是二项分布和伯努利分布之间的区别。伯努利分布模拟灯泡是否工作的概率,而二项分布则处理在测试的几个灯泡(例如 5、10 或 15 个)中,一定数量的灯泡将工作的概率。在例如灯泡测试中,工作灯泡的数量由二项随机变量建模。 n次独立试验的序列,例如测试一个伯努利实验的多个灯泡。例子:考虑抛掷一枚有偏硬币6次,其中出现正面的概率为0.6。如果将出现正面定义为成功,则二项分布表给出了每个可能值出现r次成功的概率。  输出  接下来,我们将展示一个参数为 n=6 和 p=0.6 的二项分布图。 输出  如果我们仔细观察,可以看到如果我们将 p 的值改为 0.5,我们将得到一个正态分布图。 输出 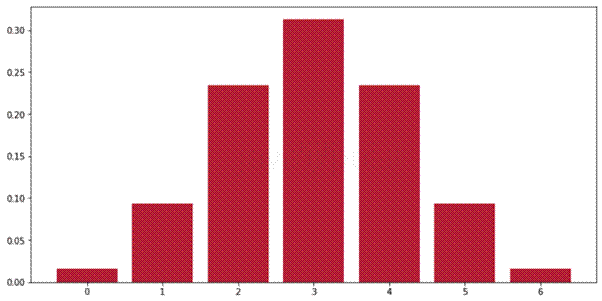 让我们看一个更真实的场景,其中二项分布适用。假设一家小型制造公司希望通过计算机器在连续生产运行中不会生产出有缺陷产品的概率来测试其可靠性。在这里,机器生产完美产品的已知概率为0.3,也就是说,30%的时间,机器生产的产品没有任何缺陷。在这种情况下,公司想知道这台机器连续多次成功生产完美产品的可能性。 它是一个重复伯努利试验序列的模型,其中单次试验代表一次生产运行,结果是无缺陷的成功产品或有缺陷的失败产品。例如,公司可能想知道在五次连续生产运行中某些事件的概率。例如,可以使用二项分布计算在连续五次运行中生产出恰好3个无缺陷产品的概率。 试验次数:5次生产运行。换句话说,每次运行都是一个独立的事件。一次运行的结果不会影响其他运行的结果。 现在我们所拥有的概率是 0.3,这意味着机器在任何一次运行中都不会产生任何缺陷产品。 当我们使用二项分布时,它可用于计算公司各种结果的概率。例如,我们可以检查所有生产的产品是否有缺陷。我们还可以检查一定数量的产品是否符合质量标准。考虑到上述所有信息,公司可以检查产品质量、检查生产单元的可靠性或检查生产过程。借助二项分布,公司可以获得有趣的见解,了解风险、机械和产品质量。 输出  根据下面的结果图,最有可能出现一个缺陷产品,其次是两个,然后依次是零、三个、四个和五个。 泊松分布泊松分布是另一种离散分布,常用于测量在一定时间段内发生某些事件的概率。为了理解泊松分布,我们来看以下示例。 假设我们知道公司支持团队每分钟收到的电子邮件平均数量。我们可以使用泊松分布来估算支持团队在未来一小时内可能收到的电子邮件数量。基于此,支持团队可以进行资源分配并相应地规划他们的工作量。 泊松分布也可以应用于预测工厂机器在一个月内发生故障的概率。此外,这种分布广泛用于假设检验中,以检验事件发生的速率。  现在我们将绘制一个简单的泊松分布图。 输出  假设当地图书馆每三十分钟定期借出一本书。换句话说,每半小时借出的书籍平均数量为一本。您可以使用泊松分布计算在接下来的30分钟内借出X本书的可能性。借出的书籍数量X可能有以下可能值:[0, 1, 2, 3, 4, 5]。 输出  鉴于平均每30分钟有1位顾客光顾餐厅,泊松概率分布图显示了在接下来的30分钟内光顾图书馆的顾客数量变化的 likelihood。 假设我们正在徒步旅行。在 10 公里的距离内,我们以每 2 公里的速度遇到溪流和泉水等水源。换句话说,在 10 公里范围内,我们通常会遇到两个水源。我们可以使用泊松分布来确定在接下来的 10 公里内遇到 0、1、2、3、4 或 5 个水源的可能性。 输出  鉴于沿 10 公里路段水源出现的平均次数为 2,泊松概率分布图显示了遇到不同数量水源(从 0 到 5)的可能性。 指数分布指数分布模拟连续事件发生之间的时间。该分布类似于泊松分布,也使用“事件率”参数λ,尽管在某些情况下,人们可能更喜欢使用事件率的倒数 1/λ。 当在一个事件持续、独立且以恒定平均速率发生的过程中,对独立事件的连续发生之间的时间间隔进行建模时,指数分布是一个受欢迎的选择。当您想要预测事件发生前的时间量时,例如灯泡的寿命、客户到达服务中心的时间或某个地区的下一次地震,您可以利用这种分布来发挥您的优势。 指数分布的无记忆性是其主要特征之一,它表明未来事件发生的可能性不受已过去时间量的影响。这使得指数分布独一无二,特别适用于模拟那些发生历史不影响未来概率的过程。 均匀分布 均匀分布:一种概率分布,其中特定范围或区间内的每个值都有同等可能的机会出现。也就是说,a 和 b 之间(恩斯特·巴拉赫)的值。因此,b 被认为是均匀分布,因为它们每个都有同等被选择的概率。例如,在一个公平的轮盘赌中,轮盘上的每个数字都有同等被选择的机会;因此,它遵循均匀分布。考虑任何其他示例,我们任意选择一条直线段上的任何一点。那么,落在该线段任何一点的概率是相等的。 这种分布被称为“均匀”是因为所有结果的概率都相同。与在图表中间达到峰值的正态分布不同,均匀分布是平坦的,结果同样可能,没有一个结果比其他任何结果更有可能。 均匀分布 识别均匀分布 有两种最常用的统计检验适用于数据集的均匀性检验:Kolmogorov-Smirnov 检验和卡方检验。这两种检验都将样本的分布与理论均匀分布进行比较,以确定样本与均匀分布的一致程度。 伽马分布伽马分布是一种连续概率分布,用于模拟右偏数据。这种现象包括机械系统故障的时间、产品寿命以及某些事件发生之间的时间,统计学家通常使用这种分布进行建模。伽马分布模拟在给定事件发生恒定平均速率λ(lambda)的情况下,事件发生所需的时间。请注意,所讨论的事件必须相互独立。 它之所以被称为伽马分布,是因为其概率密度函数涉及伽马函数,伽马函数是阶乘函数的推广。 决定伽马分布的两个主要因素是速率参数 λ(lambda),它是尺度参数的倒数,以及形状参数 k,有时也称为阶或形状因子。速率参数控制事件发生的步调,而形状参数设置分布的形式,改变其偏度和峰度。k 的小值通常会产生更严重的偏斜分布,而 k 的大值会产生更接近正态的分布。 下一个主题印度机器学习公司列表 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
