机器学习中的因果关系简介2025年2月3日 | 阅读 6 分钟 引言在机器学习中,因果关系超越了相关性,旨在理解因果互动。与寻找数据模式的典型机器学习模型不同,因果模型旨在预测干预的效果并提供“假设”的答案。这涉及到用于因果推断的方法,如反事实推理和有向无环图(DAG)。理解因果关系对于构建可靠、泛化性强、在动态环境中有效运行的模型以及做出数据驱动的决策至关重要。通过区分相关性和因果性,机器学习可以更好地处理现实世界的问题,例如政策制定和个性化医疗,在这些问题中,理解行为的真实影响至关重要。 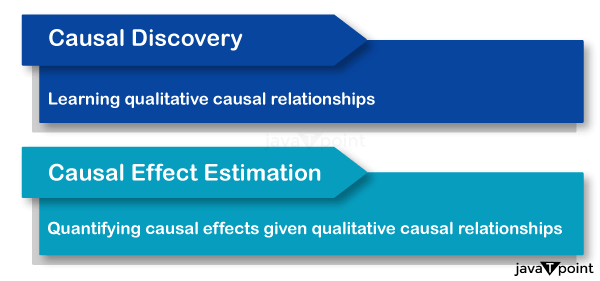 机器学习存在一系列重大问题,这对其有效性和道德应用提出了质疑。数据数量和质量都很重要,因为模型依赖大量高质量数据来正常运行。公平性和偏差是重要问题,因为模型有可能强化数据中已有的偏差,从而产生有偏见的结果。在过拟合和欠拟合之间找到平衡,使得创建能够有效泛化而不过于复杂或过于简单的模型变得困难。另一个问题是可解释性,特别是对于像深度学习这样频繁充当“黑箱”的复杂模型。为了可扩展地安装和维护模型,需要大量的计算资源。由于模型容易受到对抗性攻击和未来的数据泄露,安全和隐私也面临风险。最后,机器学习的道德影响,包括潜在的滥用和社会影响,都增加了复杂性,凸显了负责任地开发和部署这些技术的必要性。 因果机器学习——游戏的名称在过去的几十年里,科学家们创造了越来越先进的人工智能(AI)方法,这带来了越来越强大的算法以及 Alpha Go 获胜等令人惊叹的成就。随着越来越多的高性能应用进入市场,利用海量高维和异构数据源,数据科学被誉为 21 世纪最令人兴奋的职业。似乎每个人都听说过深度学习和人工智能,或者深度 AI、强 AI 等,这就像宾果游戏玩家的梦想成真。AI 似乎在很快地变得超人。 但一个问题依然存在。这些强大的系统是不可解释的。更糟糕的是,随着它们力量的增强,它们的可解释性却降低了。 与此同时,学者们警告不要将学到的模型应用于关键的现实世界情况,因为它们的可靠性取决于训练数据的质量。他们认为,虽然当代的机器学习是一个非常强大的相关性-模式识别系统,在与训练时相同分布的数据上表现出色,但它极易受到分布变化的影响。 这个问题似乎很容易解决。正如一些公司声称的那样,只需将基于相关性的识别系统替换为基于因果性的机器学习即可完成交易。将强大的因果知识与强大的机器学习技术相结合的概念是一个简单而吸引人的想法,它催生了“因果机器学习”这个短语,这个短语似乎会突然解决 AI 的最终困境。 什么是因果推断?简单来说,因果推断是一个形式化确定、量化和建模因果联系过程的研究领域。这可能对一些人来说非常简单,因为人类通过直觉非常善于从结果推断原因。例如,当你靠近沸水时感到剧痛,你对原因和结果有一定的直观感受。但从统计学角度确定因果关系并不那么简单。虽然世界上变量之间存在许多相关性,但并非所有相关性都是因果性的。考虑到这一点,可以将因果推断的目的定义为确定和衡量一个充满关联的世界的真实因果性质的过程。 关联与因果的关系在我们的数据集中,两个变量之间的关联是指这两个变量的统计依赖性,它可以表现为更一般的非线性依赖性或正相关或负相关。假设一个没有巧合依赖性的宇宙,每种关联都有两种解释。要么一个未观察到的潜在变量导致了这两个变量,要么其中一个变量导致了另一个变量。这就是所谓的 Reichenbach 的共同原因原理(Hitchcock 等人,2020)。 众所周知的晒伤和冰淇淋的例子充分证明了这一点。尽管晒伤和冰淇淋摄入之间存在很强的相关性,但它们之间没有因果关系。夏天明亮的阳光是导致这种关联的变量,因为它增加了晒伤和冰淇淋摄入的风险。  迈向因果机器学习在冰淇淋的例子中,区分原因和结果非常容易。然而,当面对一个充满变量之间相关性的观察性数据集,而你对它们之间的关系几乎一无所知时,就很难区分因果关联和纯粹的统计关联了。正是这些情况,因果推断的技术将成为你揭开这个庞大关联之谜的工具。为了处理高维和复杂数据,因果机器学习随后将其与深度学习和机器学习的能力相结合。有了这些知识,因果机器学习提供了三个好处。 利用因果发现的工具和假设,你可以学习因果图,这些图代表生成你观察到的数据的底层系统的因果关系。利用因果效应估计的工具,你可以基于因果图的定性知识,利用因果推断框架(如 do-calculus)来量化和估计因果效应。 相关性不等于因果性“相关性不等于因果性”:如果你因为听到这句话而得到一分钱,你现在可能就是百万富翁了。但它是什么意思?为什么两个事件之间的相关性并不意味着因果关系?到底是怎么回事? 相关性是指两个变量之间的关系或联系,即当一个变量发生变化时,另一个变量很可能也会发生变化。但一个变量的变化并不能引起另一个变量的变化。这就是相关性,但不是因果关系。 例如,如果你看到天空中有很多鸟,然后开始下雨,这并不意味着鸟儿引起了下雨。它们只是同时发生了。 在数学中,介于 {-1} 和 {1} 之间的相关系数表示相关性。两个变量之间的完美正相关由相关系数 {1} 表示。另一方面,当相关系数为 {-1} 时,两个变量之间存在完美的负相关。当相关系数为 {0} 时,两个变量之间没有关联。 另一方面,一个变量影响另一个变量变化的关系称为因果关系。正如因果关系的概念所暗示的那样,一个变量的变化不可避免地会影响另一个变量的变化,因果关系是一种直接的因果链。需要更彻底的调查,例如控制试验、随机实验和考虑任何混淆变量,才能确定因果关系。例如,大量的调查和控制试验表明了吸烟和肺癌之间的因果关系,表明吸烟直接增加了患肺癌的风险。 在许多学科中,包括科学、健康和经济学,理解相关性和因果性之间的区别至关重要。将相关性误解为因果关系可能会导致做出错误的决定和得出错误的结论。例如,即使一项研究表明经常锻炼的人患心脏病的几率较低,锻炼本身并不总是能降低患心脏病的风险。可能还有其他因素,如遗传或饮食也起作用。因此,为了排除其他假设并确保观察到的联系不是巧合或混淆变量的结果,证明因果关系需要严谨的研究设计和分析。 结论总而言之,理解因果关系对于机器学习中准确和安全的决策至关重要。通过将复杂的机器学习模型与因果发现和效应量化工具相结合,我们可以更深入地理解数据中潜在的因果联系。这种方法超越了简单的相关性,使我们能够构建在复杂、现实世界的场景中可靠、可解释和具有预测性的模型——所有这些最终都转化为更明智、更富有成效的决策。 下一主题Tensorflow 教程 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
