机器学习中的特征选择技术2025 年 6 月 13 日 | 阅读 8 分钟 特征选择是一种通过移除冗余、不相关或噪声特征,从原始特征集中选择最相关特征子集的方法。 在开发机器学习模型时,数据集中只有少数变量对构建模型有用,其余特征要么是冗余的,要么是不相关的。如果我们用所有这些冗余和不相关的特征输入数据集,可能会对模型的整体性能和准确性产生负面影响并降低它们。因此,识别和选择数据中最合适的特征,并移除不相关或不太重要的特征非常重要,这需要借助机器学习中的特征选择来完成。  特征选择是机器学习的重要概念之一,它极大地影响模型的性能。由于机器学习遵循“垃圾进,垃圾出”的原则,我们始终需要向模型输入最合适、最相关的数据集,以获得更好的结果。 在本主题中,我们将讨论机器学习的不同特征选择技术。但在此之前,让我们首先了解一些特征选择的基础知识。
什么是特征选择?特征是影响问题或对问题有用的属性,而为模型选择重要特征的过程称为特征选择。每个机器学习过程都依赖于特征工程,它主要包含两个过程:特征选择和特征提取。尽管特征选择和提取过程的目标可能相同,但它们彼此完全不同。它们之间的主要区别在于,特征选择是从原始特征集中选择子集,而特征提取则是创建新特征。特征选择是一种通过仅使用相关数据来减少模型输入变量的方法,以减少模型的过拟合。 因此,我们可以将特征选择定义为:“它是一个自动或手动选择最合适和最相关特征子集用于模型构建的过程。”特征选择是通过包含重要特征或排除数据集中的不相关特征来执行的,而不会改变它们。 特征选择的必要性在实施任何技术之前,了解该技术的必要性非常重要,特征选择也是如此。我们知道,在机器学习中,为了获得更好的结果,必须提供预处理好的优质输入数据集。我们收集大量数据来训练我们的模型,帮助它更好地学习。通常,数据集包含噪声数据、不相关数据和一些有用的数据。此外,大量数据也会减慢模型的训练过程,而噪声和不相关数据可能会导致模型预测和性能不佳。因此,从数据集中移除这些噪声和不重要的数据非常必要,而这正是通过特征选择技术来完成的。 选择最佳特征有助于模型表现良好。例如,假设我们想要创建一个模型,自动决定哪辆车应该被压碎以获取备件,为此我们有一个数据集。该数据集包含汽车型号、年份、车主姓名、里程数。在这个数据集中,车主姓名对模型性能没有贡献,因为它不能决定汽车是否应该被压碎,所以我们可以移除这一列,并选择其余的特征(列)来构建模型。 以下是在机器学习中使用特征选择的一些好处:
特征选择技术特征选择技术主要有两种类型:
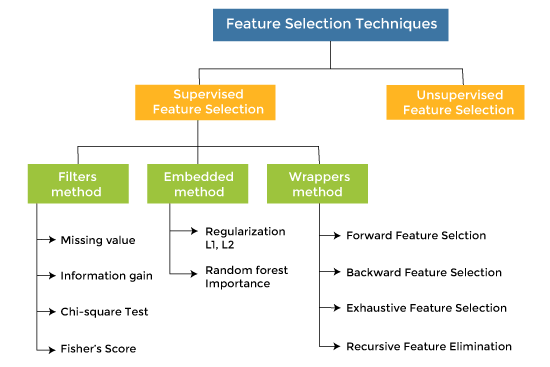 监督式特征选择下主要有三种技术: 1. 包装法 (Wrapper Methods)在包装法中,特征选择被视为一个搜索问题,其中会制作、评估和比较不同的组合。它通过迭代地使用特征子集来训练算法。 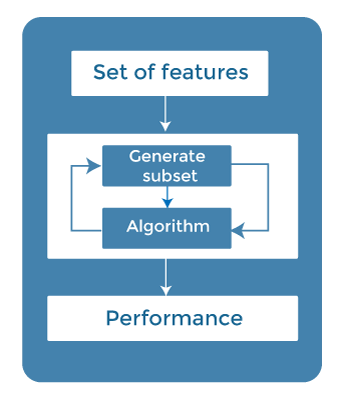 根据模型的输出,添加或减少特征,然后用这个新的特征集再次训练模型。 包装法的一些技术包括:
2. 过滤法 (Filter Methods)在过滤法中,特征是根据统计度量来选择的。这种方法不依赖于学习算法,而是在预处理步骤中选择特征。 过滤法通过使用不同的度量进行排名,从模型中过滤掉不相关的特征和冗余的列。 使用过滤法的优点是计算时间短,并且不会对数据造成过拟合。 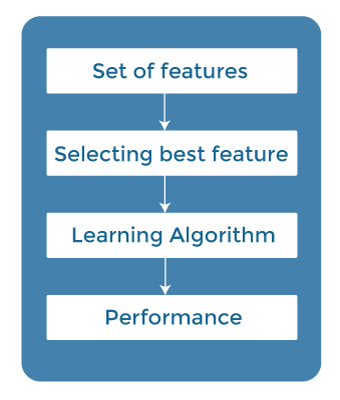 过滤法的一些常用技术如下:
信息增益:信息增益决定了在转换数据集时熵的减少量。通过计算每个变量相对于目标变量的信息增益,可以将其用作一种特征选择技术。 卡方检验:卡方检验是一种确定分类变量之间关系的技术。计算每个特征与目标变量之间的卡方值,并选择具有最佳卡方值的所需数量的特征。 费舍尔分数 (Fisher's Score) 费舍尔分数是流行的监督式特征选择技术之一。它按费舍尔准则以降序返回变量的排名。然后我们可以选择费舍尔分数较大的变量。 缺失值比例 (Missing Value Ratio) 缺失值比例的值可用于根据阈值评估特征集。获取缺失值比例的公式是每列的缺失值数量除以观测总数。超过阈值的变量可以被删除。  3. 嵌入法 (Embedded Methods)嵌入法结合了过滤法和包装法的优点,既考虑了特征的交互作用,又具有较低的计算成本。这些方法处理速度快,类似于过滤法,但比过滤法更准确。 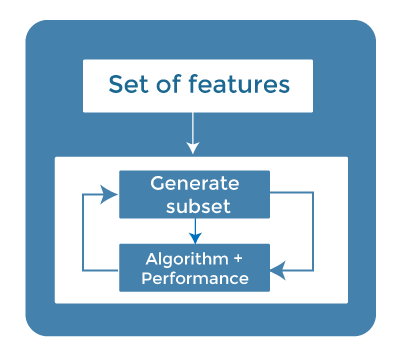 这些方法也是迭代的,它会评估每次迭代,并以最优方式找出在特定迭代中对训练贡献最大的最重要特征。嵌入法的一些技术包括:
如何选择特征选择方法?对于机器学习工程师来说,理解哪种特征选择方法将对他们的模型有效是非常重要的。我们越了解变量的数据类型,就越容易选择合适的统计度量来进行特征选择。 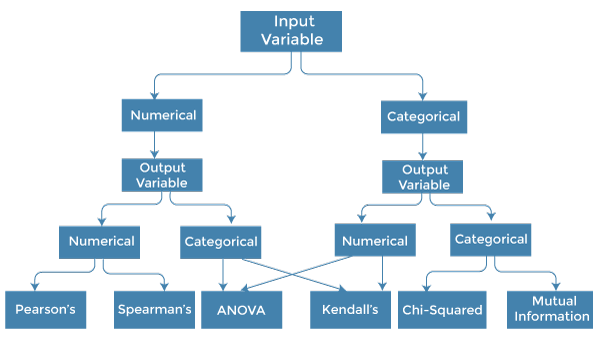 要了解这一点,我们需要首先确定输入和输出变量的类型。在机器学习中,变量主要有两种类型:
以下是一些可用于基于过滤的特征选择的单变量统计度量: 1. 数值输入,数值输出 数值输入变量用于预测回归建模。这种情况下的常用方法是相关系数。
2. 数值输入,分类输出 数值输入与分类输出是分类预测建模问题的情况。在这种情况下,也应使用基于相关性的技术,但要与分类输出结合使用。
3. 分类输入,数值输出 这是带有分类输入的回归预测建模的情况。它是回归问题的一个不同例子。我们可以使用与上述情况中讨论的相同度量,但顺序相反。 4. 分类输入,分类输出 这是带有分类输入变量的分类预测建模的情况。 这种情况常用的技术是卡方检验。我们也可以在这种情况下使用信息增益。 我们可以用下表总结上述情况及相应的度量:
结论特征选择是机器学习中一个非常复杂和广阔的领域,已经有大量的研究来发现最佳方法。没有固定的最佳特征选择方法规则。然而,方法的选择取决于机器学习工程师,他们可以结合和创新方法来为特定问题找到最佳方法。应该尝试在通过不同统计度量选择的不同特征子集上拟合多种模型。 下一主题编码器-解码器模型 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
