机器学习流水线2025 年 6 月 20 日 | 阅读 8 分钟 什么是机器学习管道?机器学习管道是自动化完成的完整机器学习任务工作流的过程。它可以通过实现一系列数据转换和模型之间的关联,以便进行分析以获得输出。典型的管道包括原始数据输入、特征、输出、模型参数、ML模型和预测。此外,ML管道包含多个连续步骤,以模块化方法执行从数据提取和预处理到模型训练和部署的全部内容。这意味着在管道中,每个步骤都被设计为一个独立的模块,所有这些模块都绑定在一起以获得最终结果。 ML管道是“spark.ml”包内MLlib的高级API。典型的管道包含各种阶段。然而,有两种主要的管道阶段: 
机器学习管道的重要性要理解机器学习管道的重要性,我们首先需要理解ML任务的典型工作流。 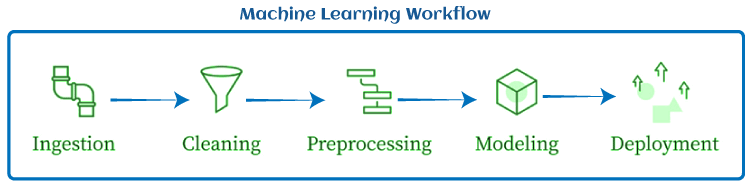 典型的 ML 工作流包括数据摄取、数据清洗、数据预处理、建模和部署。 在ML工作流中,所有这些步骤都与同一个脚本一起运行。这意味着同一个脚本将被用于提取数据、清洗数据、建模和部署。然而,这可能会在尝试扩展ML模型时产生问题。这些问题包括:
为了解决以上所有问题,我们可以使用机器学习管道。使用ML管道,工作流的每个部分都作为一个独立模块。因此,每当我们想更改任何部分时,我们可以选择那个特定的模块并根据我们的需求使用它。 我们可以通过一个例子来理解这一点。构建任何ML模型都需要大量的训练数据。由于数据是从不同来源收集的,因此有必要清洗和预处理数据,这是ML项目中的一个关键步骤。然而,每当包含新数据集时,我们需要在将其用于训练之前执行相同的预处理步骤,这对ML专业人员来说是一个耗时且复杂的过程。 为了解决这类问题,可以使用ML管道,它可以记住并自动化整个预处理步骤,并保持相同的顺序。 机器学习管道的步骤根据ML模型的用例和组织的具体需求,每个机器学习管道在一定程度上可能会有所不同。然而,每个管道都遵循/工作于通用的机器学习工作流,或者有些共同的阶段是每个ML管道都包含的。管道的每个阶段都接收其前一个阶段的输出,作为该特定阶段的输入。典型的ML管道包含以下阶段: 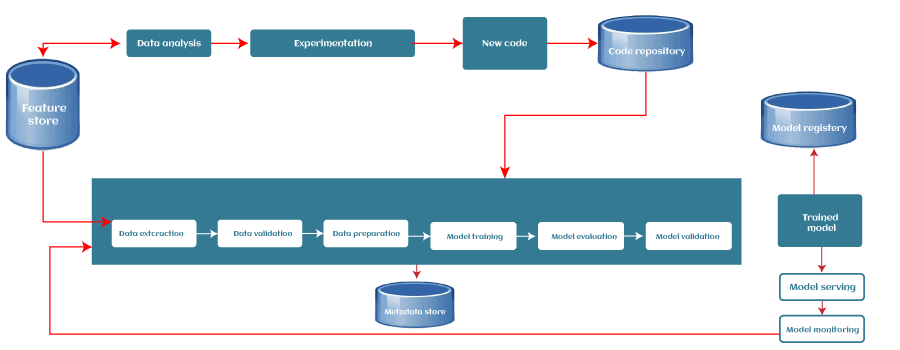 1. 数据摄取每个ML管道都从数据摄取步骤开始。在此步骤中,数据被处理成一个组织良好的格式,适合应用于后续步骤。此步骤不执行任何特征工程,而是可能执行输入数据的版本管理。 2. 数据验证下一步是数据验证,在训练新模型之前需要执行此步骤。数据验证侧重于新数据的统计信息,例如范围、类别数量、类别分布等。在此步骤中,数据科学家可以检测数据中是否存在任何异常。有各种数据验证工具可以帮助我们比较不同的数据集以检测异常。 3. 数据预处理数据预处理是每个ML生命周期和管道中最关键的步骤之一。我们不能直接将收集到的数据输入以训练模型,而不进行预处理,因为这可能会产生不理想的结果。 预处理步骤包括准备原始数据并使其适合ML模型。该过程包括不同的子步骤,例如数据清洗、特征缩放等。数据预处理步骤的产品或输出成为可用于模型训练和测试的最终数据集。ML中有各种用于数据预处理的工具,其范围可以从简单的Python脚本到图模型。 4. 模型训练与调优模型训练步骤是每个ML管道的核心。在此步骤中,模型被训练以接收输入(预处理后的数据集)并以最高可能的准确度预测输出。 然而,对于大型模型或大型训练数据集,可能会有一些困难。因此,需要高效地分配模型训练或模型调优。 管道可以解决模型训练阶段的这个问题,因为它们是可扩展的,并且可以同时处理大量模型。 5. 模型分析模型训练后,我们需要使用准确率损失指标来确定最优参数集。除此之外,对模型性能进行深入分析对于模型的最终版本至关重要。深入分析包括计算其他指标,如精度(precision)、召回率(recall)、AUC(Area Under the Curve)等。这也有助于我们确定模型对训练中使用的特征的依赖性,并探索如果我们改变单个训练样本的特征,模型的预测会如何变化。 6. 模型版本管理模型版本管理步骤跟踪哪些模型、超参数集和数据集被选为下一个要部署的版本。在各种情况下,仅仅通过应用更多/更好的训练数据而不更改任何模型参数,模型性能可能会出现显著差异。因此,记录新模型版本的所有输入并跟踪它们很重要。 7. 模型部署在训练和分析模型后,是时候部署模型了。ML模型可以通过三种方式部署,它们是:
然而,部署模型的常用方法是使用模型服务器。模型服务器允许同时托管多个版本,这有助于运行模型的A/B测试,并为模型改进提供有价值的反馈。 8. 反馈循环每个管道都形成一个闭环以提供反馈。通过这个闭环,数据科学家可以确定已部署模型的有效性和性能。此步骤可以根据需求自动化或手动完成。除了两个手动审查步骤(模型分析和反馈步骤)之外,我们可以自动化整个管道。 机器学习管道的优点使用管道进行ML工作流的一些优点如下:
构建机器学习管道时的注意事项
ML管道工具在机器学习中,有许多不同的工具用于构建管道。以下是一些及其用法:
下一主题什么是 Xavier 初始化 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
