机器学习中的探索与利用2025年6月20日 | 阅读 7 分钟 探索与利用是强化学习中的关键概念,它们有助于智能体以更好的方式进行在线决策。 强化学习是一种机器学习方法,在这种方法中,一个智能体(计算机程序)通过与环境互动并采取行动来最大化特定情况下的奖励。这种机器学习方法目前被广泛应用于汽车、医疗保健、医学、教育等众多行业。  在强化学习中,智能体并不知道不同的状态、每个状态下的动作、相关的奖励以及到下一个状态的转换,而是通过探索环境来学习这些。然而,智能体对状态、动作、奖励和结果状态的了解是不完整的,这导致了探索-利用困境。在本主题“机器学习中的探索与利用”中,我们将结合合适的例子详细讨论这两个术语。但在开始讨论之前,让我们先了解一下机器学习中的强化学习。 什么是强化学习?与监督学习和无监督学习不同,强化学习是一种基于反馈的方法,其中智能体通过执行某些动作及其结果来学习。根据动作状态(好或坏),智能体获得正反馈或负反馈。此外,对于每个正反馈,它们会获得奖励,而对于每个负反馈,它们也会受到惩罚。 强化学习的关键点
因此,我们可以将强化学习定义为 “强化学习是一种机器学习技术,其中一个智能体(计算机程序)与环境互动,自行探索它,并在其中采取行动。” 强化学习中的探索与利用是什么在简要介绍机器学习中的探索与利用之前,让我们先用简单的词语来理解这两个术语。在强化学习中,当智能体遇到需要艰难选择的情况时,即在某个特定时间点是继续做同样的事情还是探索新事物,那么这种情况就会导致探索-利用困境,因为智能体对状态、动作、奖励和结果状态的了解始终是不完整的。 现在我们将从技术角度讨论利用和探索。 强化学习中的利用利用被定义为一种贪婪的方法,在这种方法中,智能体试图通过使用估计值而不是实际值来获得更多奖励。因此,在这种技术中,智能体根据当前信息做出最佳决策。 强化学习中的探索与利用不同,在探索技术中,智能体主要关注提高对每个动作的了解,而不是获得更多奖励,以便它们能够获得长期利益。因此,在这种技术中,智能体致力于收集更多信息以做出整体最佳决策。 机器学习中探索与利用的例子让我们通过一些有趣的现实世界例子来理解利用和探索。 煤矿开采假设 A 和 B 两人在一个煤矿里挖掘,希望能找到钻石。B 在 A 之前成功找到了钻石,高高兴兴地离开了。看到他之后,A 有点贪婪,觉得他也可以在 B 挖掘煤炭的地方找到钻石。A 的这个行为被称为贪婪行为,这种策略被称为贪婪策略。但是 A 并不知道,一个更大的钻石可能埋在他最初挖掘的那个地方,而这种贪婪策略在这种情况下可能会失败。 在这个例子中,A 只知道了 B 挖掘的地方,但对那个深度之外有什么一无所知。但在实际情况中,钻石也可能埋在他最初挖掘的地方,或者完全是另一个地方。因此,基于这种获取更多奖励的不完整知识,我们的强化学习智能体将陷入困境,是利用部分知识来获得一些奖励,还是应该探索可能带来许多奖励的未知动作。 然而,这两种技术不能同时实现,但这个问题可以通过使用 Epsilon 贪婪策略(下面解释)来解决。 机器学习中探索与利用还有一些其他例子,如下所示 示例 1:假设我们有一个在线餐厅选择点餐的场景,您有两个选择餐厅的选项。在第一个选项中,您可以选择您过去订过餐的您最喜欢的餐厅;这被称为利用,因为在这里,您只知道某个特定餐厅的信息。对于其他选项,您可以尝试一家新餐厅来探索新的食物种类和口味,这被称为探索。然而,第一个选项的食物质量可能更好,但也有可能在另一家餐厅更美味。 示例 2:假设有一个游戏平台,您可以在其中与机器人下棋。要赢得这场比赛,您有两种选择:要么走您认为最好的棋,要么走一步实验性的棋。然而,您正在下最好的棋,但谁知道新的一步可能对赢得这场比赛更具战略性呢?在这里,第一个选择被称为利用,您了解您的游戏策略,第二个选择被称为探索,您正在探索您的知识并下出新的一步来赢得比赛。 Epsilon 贪婪策略Epsilon 贪婪策略被定义为一种在利用和探索之间保持平衡的技术。然而,要在这两者之间进行选择,一个非常简单的方法是随机选择。这可以通过大部分时间选择利用并进行少量探索来实现。  在贪婪 epsilon 策略中,探索率或 epsilon(用 ε 表示)最初设置为 1。此探索率定义了智能体探索环境而不是利用环境的概率。它还确保智能体一开始会以 ε=1 的值探索环境。 随着智能体开始并了解更多关于环境的信息,epsilon 会按照预定的速率降低,因此随着智能体对环境了解得越来越多,探索的可能性就越来越小。在这种情况下,智能体将变得倾向于利用环境。 为了确定智能体在每一步是选择探索还是利用,我们生成一个 0 到 1 之间的随机数并将其与 epsilon 进行比较。如果这个随机数大于 ε,那么下一步的动作将由利用方法决定。否则,必须是探索。在利用的情况下,智能体将为当前状态采取具有最高 Q 值的动作。 示例- 我们可以通过掷骰子来理解上述概念。假设如果骰子掷出 1,智能体就会探索;否则,它就会利用。这种方法被称为 epsilon 贪婪动作,epsilon 的值为 ε=1/6,即骰子掷出 1 的概率。这可以表示为 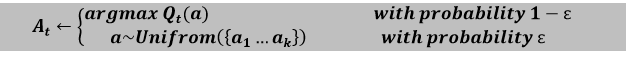 在上面的公式中,在尝试“t”时选择的动作是以 1- ε 的概率选择的贪婪动作(利用),或者以 ε 的概率选择的随机动作(探索)。  遗憾的概念每当我们做某事但没有得到应有的结果时,我们就会后悔我们的决定,就像我们之前讨论过的选择餐厅的利用和探索的例子一样。对于那个例子,如果我们选择一家新餐厅而不是我们最喜欢的餐厅,但食物质量和整体体验都很差,那么我们会后悔我们的决定,并将我们付出的视为完全损失。此外,如果我们再次从同一家餐厅订购食物,随着损失次数的增加,遗憾的水平也会增加。然而,强化学习方法可以减少损失的金额和遗憾的水平。 强化学习中的遗憾 在理解强化学习中的遗憾之前,我们必须知道最优动作“a*”,这是能产生最高奖励的动作。它表示如下  因此,强化学习中的遗憾可以定义为最优动作 a* 乘以 T 所产生的奖励与从 1 到 T 的任意动作的每个奖励之和之间的差值。这可以表示为 Regret:LT=TE[r?a^* ]-∑[r|at] 结论强化学习中的探索与利用技术在许多参数方面得到了增强,例如提高了性能、增加了学习率、改善了决策制定等。所有这些参数对于强化学习方法的智能体学习都很重要。此外,探索与利用技术的缺点是两者都需要与这些参数以及特定环境进行同步,这可能会给强化学习智能体带来更多的监督。本主题介绍了一些在强化学习中最常用的探索技术。从上面的例子中,我们可以得出结论,我们必须优先考虑探索方法以减少遗憾,并使学习过程更快、更有意义。 下一个主题为什么在强化学习中折现未来奖励 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
