神经网络的数学2025年8月21日 | 阅读11分钟 神经网络是模拟人脑功能的AI。它们通过接触大量示例进行训练:接收输入,处理并做出预测,然后将其与真实结果进行比较。差异或错误随后用于修改内部参数(权重),以便下次做出更准确的预测。 神经网络看似复杂,但它们是基于线性代数和多元微积分的元素构建的。本文深入探讨了神经网络学习周期中一次遭遇的完整数学影响。 生物学启示人脑中大约有860亿个神经元,它们连接形成一个复杂的网络。这些神经元之间的通信通过突触完成,突触更常被称为信号可以建立或衰减以影响信息传输方式的连接点。这种动态系统是学习过程、适应和记忆的核心基础。 人工神经网络基于这种生物学结构。这些是数字神经元(或节点)的网络层。系统中的数据进入输入层,在隐藏层中进行处理,并通过输出层提供输出。网络中单元之间连接的强度(或权重)随着新数据呈现给网络而更新,其方式类似于大脑加强或减弱突触。 从感知器到深度学习的历史神经网络始于1958年,Frank Rosenblatt发明了感知器,这只是一个可以执行与二元分类相关的基本任务的简单模型。这是更高层次架构(即多层感知器(MLP))的先驱,MLP增加了隐藏层以学习数据中更复杂的模式。 这后来发展为深度学习——一种利用多层神经网络的策略。这种深度架构能够利用大量数据进行学习,并推动了人工智能的一些突破,例如玩围棋和自动驾驶汽车。 通过模式学习神经网络的基本优势在于,它们能够无需任何明确编程即可识别模式。这是通过一种称为训练的活动完成的,在该活动中,网络通过定位数据中的趋势和模式来创建知识,从而使其能够做出准确的预测或决策。 这种灵活性使神经网络在图像和语音识别、语言翻译甚至金融预测等各种领域都变得如此强大。它们告诉我们机器如何处理过去需要人类本能和智能才能完成的任务。 神经网络类型有了这些基础知识,让我们在深入了解它们的结构和数学原理之前,先看看最广泛的神经网络类型。它们都有各自的优点和应用,这表明了神经网络的灵活性和潜力。我将在稍后详细讨论这些内容——所以请关注本专栏! 前馈神经网络(FNN) 前馈神经网络采用最简单和最基本的信息处理形式,其中数据沿单一方向流动;从输入到输出,通过一个或多个隐藏层。没有循环或记忆。它们在解决简单问题(例如基本分类和回归问题)时表现出色。 卷积神经网络 (CNN) 图像相关操作通过使用CNNs进行。它们旨在识别空间模式,并可以通过卷积层识别图像的边缘、纹理和形状。您的手机之所以能够识别人脸、区分图像中的猫以及使用CNNs驾驶自动驾驶汽车,都归功于CNNs。 循环神经网络 (RNN) RNNs擅长处理序列数据。它们具有某种记忆,能够记住序列早期阶段的信息。因此,它们适用于语言模型、语音识别器、时间序列预测器等,在这些应用中上下文很重要。 长短期记忆(LSTM) LSTM是RNNs的一种更复杂的类型,它被开发用于在更长的序列中存储信息。它们解决了标准RNNs遗忘旧数据的问题。LSTMs擅长机器翻译、文档摘要或数据中长期趋势建模等应用。 生成对抗网络或GAN GAN由两个神经网络组成,即生成器和判别器。生成器生成新的、人工数据,而判别器试图确定它是人工数据还是真实数据。这种对抗性安排导致了非常逼真的结果:GANs可以创建逼真的图像、音频甚至类似人类的文本。 神经网络的架构人工构建的神经元或节点模仿人脑中的生物神经元,是神经网络的核心。神经元是构成输入、信息处理和输出传输的基本单元。它们用于构建网络并执行导致学习和决策的关键任务。名称已经够多了,现在是时候了解这些神经元是什么以及它们如何工作了。 神经元结构 神经元可以直接以已知原始数据的形式接收输入,也可以接收其他神经元的输出。此类输入表示数据的各种特征或属性。 神经元执行的计算非常简单,即根据每个输入,它乘以一个权重并添加一个偏差。权重指定该输入的重要性,偏差有助于调整给定神经元的输出。网络在训练期间修改这些权重和偏差以提高其正确性。 神经元随后将所有加权输入与偏差相加,并将输出应用于某个激活函数。此操作导致非线性,使神经元能够识别数据中的复杂模式。ReLU、Sigmoid和Tanh等其他激活因子是常见的,它们有自己不同的转换输入的方法。 神经网络中的层神经网络的结构像蛋糕的层一样,由一组层组成,每一层都包含多个神经元。层的结构决定了网络的结构。 输入层 这是数据首次引入网络的地方。该层中的每个神经元对应于输入数据的一个特定特征。例如,它可能是图像中的一个像素;每个像素将有一个输入神经元。它是图中左侧的第一层,通常包含与输入特征数量相同的神经元。 隐藏层 输入和输出之间是隐藏层,它执行大部分计算。一个网络可以只有一个隐藏层或多个隐藏层。这些层的作用是检测模式并将输入转换为对最终预测有用的内容。 层数和神经元数量越多,网络能够捕获的模式就越复杂。然而,更深的网络涉及更多的计算,并且可能存在过拟合的风险,即模型学习训练集太好而泛化能力差。 输出层 这是输出层,网络在此层产生输出。根据任务,该层的结构有所不同。在分类问题的情况下,它可能每个类别有一个神经元,通常通过softmax函数输出概率。在回归中,例如所提到的图像中,输出层可能只有一个神经元来提供连续类型的输出值。 基本过程前向传播数据输入神经网络并通过系统进行转换以提供预测的过程称为神经网络中的前向传播。这以将输入馈送到所有层的形式进行,每层中的每个神经元都执行加权和加上使用激活函数添加偏差的操作。一层的结果随后作为另一层的输入,这会持续到最后一个输出层。这是网络根据其已知知识(权重和偏差)进行猜测的方法。 涉及的步骤
示例 输出 Weighted sum (z): 2.1000 Prediction (y_hat): 0.8909 反向传播学习步骤称为反向传播,网络通过其所做的预测进行学习。前向传播完成后,使用损失函数将输出与目标值进行比较。然后,反向传播算法通过链式法则计算梯度,从而计算每个权重和偏差对误差的贡献。 然后,使用这些梯度更新权重和偏差,以便在下一次迭代中最小化误差。这实际上是纠正网络的阶段。 涉及的步骤
示例 输出 Forward Propagation: Prediction (y_hat): 0.8909 Loss: 0.0060 Backward Propagation: Gradient w1: -0.0108, Updated w1: 0.4011 Gradient w2: -0.0215, Updated w2: 0.6021 Gradient b: -0.0108, Updated b: 0.5011 神经网络的数学加权和 神经网络的计算始于输入的加权和。将每个输入乘以其权重,并向操作添加偏差项。这也被称为线性组合,以确定输入对神经元输出影响的总和。 在数学上,我们有 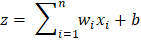 加权和至关重要,因为神经元的原始输入被纳入加权和中。它允许网络线性地添加输入,并且每个权重都表示给定输入对神经元输出的影响有多大。这是网络在训练期间学习和改变每个输入准备。 激活函数 如前所述,激活函数在确定神经网络的输出中起着关键作用。这些数学映射根据输入确定神经元是否应该被激活。激活函数通过向网络引入非线性,使网络能够捕获非线性且高度复杂的数据模式和关联。 这是因为深度学习模型具有这种非线性能力,使它们能够解决图像识别、语言处理等领域的复杂问题。 下面介绍了一些最广泛使用的激活函数及其重要性。 Sigmoid 函数 任意输入值的 sigmoid 函数可以在0和1之间渲染,因此被转换为类似于概率的东西。无论输入有多高或多低,输出都不会超过此限制。 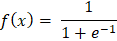 这主要适用于二元分类模型的输出层,在这些模型中必须在两个类别中做出选择——是/否、真/假或1/0。 双曲正切函数或Tanh函数 Tanh函数将值转换为-1到1之间的空间,输出以0为中心。这种以零为中心的特性将有助于后续层更好地工作。 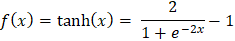 它通常用于隐藏层,因为它可以通过保持均匀大小的输入信号传递到进一步处理来捕获和绘制复杂模式。 整流线性单元(ReLU) ReLU是一种过滤器类型,意味着正值被允许通过,而负值被更改为零。这种简单的行为使其在解决深度神经网络中的标准训练问题时具有高效和有效性。 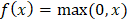 ReLU由于其速度和可靠性而成为最流行的激活函数之一,尤其是在卷积神经网络(CNN)和其他类型的深度学习网络中。 Leaky Rectified Linear Unit (Leaky ReLU) Leaky ReLU确保负输入具有非常小的非零斜率,以便即使神经元不激发也能继续学习过程。这避免了常规ReLU常见的死神经元问题,使网络的所有部分都能持续运行。 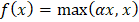 指数线性单元(ELU) ELU使用参数alpha(用作比例因子)缩放负输入,使负输出呈现更平缓的下降,而不是突然下降。它使平均激活更接近零,这可能使学习更有效,特别是在ReLU具有尖锐阈值可能阻碍训练的深度网络中。 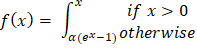 Softmax 函数 原始输出分数(即逻辑数,也称为logits)通过softmax算法转换,通过指数化并除以所有结果的总和进行归一化和概率化。这使得输出可以直接解释为类别的概率。在处理多分类问题时,这是输出层的通常选择,其中类别被编码为神经元,旨在识别最可能的类别。 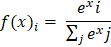 示例 输出 Hidden layer output (a1): [0.52 0.13] Output before activation (z2): 0.629 Final prediction (y_hat): 0.652014 下一个主题使用机器学习进行IPL预测 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
