使用 PyTorch 进行时间序列预测的 LSTM2025年2月28日 | 阅读 12 分钟 LSTM 网络LSTM(长短期记忆)单元是更高级的神经网络结构中一个至关重要的构建块。当然,像全连接层这样的基本层执行输入张量和权重张量之间的批量乘法,而 LSTM 单元则更为复杂。 一个 LSTM 单元是数据时间上的一个单位,包含一个输入张量、一个单元记忆(C)和一个隐藏状态(h),所有这些都初始化为零。在单元内部,输入(X)、单元记忆(C)和隐藏状态(h)与不同的权重张量进行点积运算,并经过几个激活函数,从而得到更新后的单元记忆和隐藏状态。这些更新后的状态随后用于下一个时间步。最后一个时间步之后 LSTM 单元的最终输出是其单元记忆和隐藏状态。 LSTM 单元的方程如下:  其中,W、U 和 b 是可训练的参数,并且必须记住,它们在每个时间步 t 都会重复使用。LSTM 单元通过某些参数在所有时间步都相同这一事实来跨时间保留信息。 文献中展示了各种 LSTM 单元的设计,这是其中一种常见的实现方式。 LSTM 单元假定输入张量 X 将逐渐由多个时间步组成,即每个输入必须是一个二维张量,其中一个维度表示时间,另一个维度表示特征。LSTM 模型的效率受其隐藏状态大小的影响,通常高于输入特征的大小。 用于时间序列预测的 LSTM一个例子是: 手头的问题可以用以下陈述来最好地描述:“一个国家的国内国民总支出是其高度发达状态的指标。” 更进一步,在我们的案例中,“如果一个国家的国内 GNE 水平很高,那么它就是一个发达国家。” 数据集的时间长度是从1949年1月到1960年12月,这是一个12年的时间,数据以月度方式列出,总计144个观测值。任务是利用前几个月的数据,计算下一个月的乘客数量(以千为单位)。这是一个回归问题,其中唯一的特征是每月的乘客数量。 本地目录中的 airline-passengers.csv 是文件名,其格式如下: "月份", "乘客数" "1949-01",112 "1949-02",118 "1949-03",132 "1949-04",129 数据集包含两列,分别是月份和乘客数量。由于时间序列是用于乘客计数的,我们只使用乘客计数进行预测。以下代码使用 pandas 库读取数据集,并将其转换为一个二维 NumPy 数组,然后使用 matplotlib 进行绘图。 代码片段 该时间序列包含144个数据点,可以看出其具有明确的U形趋势,波长为一年。除了全局增长外,该序列还具有与一年中不同时间相关的内部结构。尽管去趋势化和归一化是常见的预处理步骤,但为了简单起见,这里省略了它们。 为了训练模型,时间序列被划分为训练集和测试集。与其他数据集不同,时间序列数据在划分时不进行洗牌,这意味着第一部分用于训练,其余部分用于测试。这可以通过以下代码实现: 这样,时间顺序得以保留,模型仍然可以学习数据中的时间模式。 这就是模型获取从时间 t 到时间 t + n 的数据,并必须预测时间 t + n + 1(甚至更远)的值。窗口大小 n 指定了模型在进行预测时可以考虑的过去测量值的数量。这个时期也被称为“回看期”。 你可以在一个长的时间序列中定义多个重叠的窗口。为了方便地做到这一点,编写一个函数,接收原始时间序列并返回一个固定大小的窗口数据集是很有用的。为了让 PyTorch 工作,数据集需要准备好,并且数据将在一个派生自 PyTorch 的模型中使用。这意味着返回值应该被转换为 PyTorch 张量。这是一个如何在你的代码中使用此功能的例子: 代码 在这个函数中: time_series: 作为要处理的输入数据样本, window_size -> 这个参数告诉模型在做预测时要回看多远的过去。 该函数返回2个张量——data(包含滑动窗口)和 labels(表示序列中的下一个值)。 通过这种方式,可以生成多个重叠的窗口,并例如,将它们作为输入来训练模型以预测未来的值。你将使用这些张量在 PyTorch 中训练一个循环 LSTM 模型。 下面创建的函数用于在时间序列数据上应用滑动窗口,以便我们可以进行一步预测(例如,预测悉尼明天的温度)。该函数接收一个时间序列,将其转换为 PyTorch 张量,并将输入向量的形状重塑为(窗口样本数,时间步数,特征数)。对于一个 n 步的时间序列,它将创建 (n - window_size) 个窗口,其中每个重要的连续数据集都落在一个不同的窗口下。由于只有一个特征(乘客数量),数据集被视为一个二维数组,但输出是三维张量。 目标是每个窗口中这个子信号的时间戳(0-max_x _steps_per_window)[这实际上是在预测一步之后,但有助于网络训练],并且已经存在来自先前时间点的值。 要设置 lookback=1,你可以传递一个带有度量或损失对象的整数。这里有一个小代码片段来测试它并检查张量的形状: 代码片段 输出 torch.Size ([95, 1, 1]) torch.Size ([95, 1, 1]) torch.Size ([47, 1, 1]) torch.Size ([47, 1, 1]) LSTM 模型: 当 lookback=1(回看一个时间步)时,用于预测的数据集非常小,因此模型做出的准确性可能不高,但它提供了一个很好的结构来说明我们的模型是如何工作的。 LSTM 模型可以在 PyTorch 中定义为一个类,在 LSTM 层之后附加一个线性层: 代码片段 其中 LSTM 层的 input_size=1(因为只有一个特征,即乘客数量),hidden_size=50(隐藏单元的数量),以及 num_layers=1。 下一层(全连接层或线性层)接收来自 LSTM 内部的隐藏状态,并将其映射到输出,这个输出是对我们期望在这个特定时间步发生的情况的预测。 nn.LSTM() 的输出是一个元组: 第一部分对应于每个时间步的隐藏状态。 第二部分是 LSTM 的记忆或隐藏状态(在我们的模型中未使用)。 在这个设计中,LSTM 层将以 batch_first=True 的方式创建,格式为(窗口样本数,时间步数,特征数);这里,我们正在以这种格式排列输入张量。 这里设置了这个参数,因此批次大小被识别为第一个维度。 处理之后,来自 LSTM 层的隐藏状态输出通过一个全连接(线性)层进行线性变换,以得到一个回归结果。因为 LSTM 为序列中的每个时间步提供一个输出,你可以选择: 将全连接层应用于所有时间步的输出,或者 在预测阶段,它只需要关注最后一个时间步的输出。 修改如下:为了获取最后一个时间步的输出。 在这种方法中: x[:, -1, :] 选择了 x 在最后一个时间步的输出,我们可以用它来预测下一个时间步。 这最后一个输出将被送入全连接层以产生回归结果。 然而,如果窗口大小为1,两种方法(全序列和最后一个时间步用于输入生成)会产生相同的结果;实际上,只有一个时间点和一个单位窗口。 使用 PyTorch 训练 LSTM 模型以预测时间序列(航空公司乘客数据集)中的未来值。该模型使用 Adam 优化器进行训练,以最小化均方误差(MSE)损失。 代码中的关键步骤 模型初始化: 模型由 AirModel 类创建,它包含一个 LSTM 层和一个密集层。 优化器和损失函数: 我们选择使用 Adam 优化器进行高效的基于梯度的优化。由于这是一个回归问题,我们将使用 MSELoss。 DataLoader: PyTorch 的 DataLoader 对训练数据进行分批,这使得在训练期间可以进行高效的批量处理。 训练循环: 训练 n_epochs = 2000 个周期。 在每个周期的每一批数据中,该模型进行预测,计算损失,并通过优化器,优化器会反向传播梯度并更新模型参数。 验证: 每100个周期后,使用 RMSE(均方根误差)评估模型在训练集和测试集上的性能。 RMSE 是衡量模型预测响应准确性的一个好指标,如果模型的主要目的是预测,它就是拟合最重要的标准。 代码片段 预期输出 我们预计 RMSE 会缓慢下降直到这个点,更多的训练周期会进一步提高我们模型的准确性。总的来说,我们看到测试集上的 RMSE 通常高于训练集——这是过拟合的迹象,即模型开始从训练数据中的噪声学习,并对其学习内容变得过于专门化。尽管如此,随着训练的进行,测试集上的 RMSE 应该会大幅下降。 实际输出 Epoch 0: train RMSE 225.7571, test RMSE 422.1521 Epoch 100: train RMSE 186.7353, test RMSE 381.3285 Epoch 200: train RMSE 153.3157, test RMSE 345.3290 Epoch 300: train RMSE 124.7137, test RMSE 312.8820 Epoch 400: train RMSE 101.3789, test RMSE 283.7040 Epoch 500: train RMSE 83.0900, test RMSE 257.5325 Epoch 600: train RMSE 66.6143, test RMSE 232.3288 Epoch 700: train RMSE 53.8428, test RMSE 209.1579 Epoch 800: train RMSE 44.4156, test RMSE 188.3802 Epoch 900: train RMSE 37.1839, test RMSE 170.3186 Epoch 1000: train RMSE 32.0921, test RMSE 154.4092 Epoch 1100: train RMSE 29.0402, test RMSE 141.6920 Epoch 1200: train RMSE 26.9721, test RMSE 131.0108 Epoch 1300: train RMSE 25.7398, test RMSE 123.2518 Epoch 1400: train RMSE 24.8011, test RMSE 116.7029 Epoch 1500: train RMSE 24.7705, test RMSE 112.1551 Epoch 1600: train RMSE 24.4654, test RMSE 108.1879 Epoch 1700: train RMSE 25.1378, test RMSE 105.8224 Epoch 1800: train RMSE 24.1940, test RMSE 101.4219 Epoch 1900: train RMSE 23.4605, test RMSE 100.1780 这部分代码将允许我们可视化预测值与原始值,因为这个模型,使用 LSTM_modeforecaset 函数,只创建了一个用于预测未来30天的计算器(我们的数据集 dfid)。该图是使用 matplotlib 库生成的,它还将训练和测试的预测与原始时间序列绘制在一起。 代码解释
这可以让你将预测值与测试数据集的实际值进行比较,从而检查你的模型在数据上的表现如何。 这部分代码将允许我们可视化预测值与原始值,因为这个模型,使用 LSTM_modeforecaset 函数,只创建了一个用于预测未来30天的计算器(我们的数据集 dfid)。该图是使用 matplotlib 库生成的,它还将训练和测试的预测与原始时间序列绘制在一起。 为了更清楚地了解预测性能,你可以使用 matplotlib 可视化模型的输出,如下所示: 在上面的代码中,获取了模型输出(y_pred),并且只提取了最后一个时间步(y_pred[:, -1, :])用于绘图。 红线表示训练集结果,绿线表示测试集结果。蓝色阴影条代表实际数据。模型似乎很好地拟合了训练数据,但在测试集上表现不佳。下面是回看设置为4的完整代码: 输出  当你运行下面的代码时,你会得到一个图表,其中 RMSE 和定性表现表明,随着训练的进行,模型在测试集上的表现越来越好。另一个函数是 create_dataset(),它将已知数据添加到损失公式中,以帮助模型的信息吸收过程。 在下面的代码中,你将学习如何构建一个 LSTM 模型并用它来预测 PyTorch 的时间序列。我们使用的数据集包含航空公司运输的乘客数量,首先加载并转换它。然后将获得的数据分为训练数据集和测试数据集,比例分别为67%和33%。 下一个函数 create_dataset() 使用窗口技术将时间序列分割成带有特征和标签的样本。这个提出的模型在回看为4的情况下工作,这意味着它根据当前正在分析的时间步和之前的3个时间步来预测下一个时间步。 代码 输出 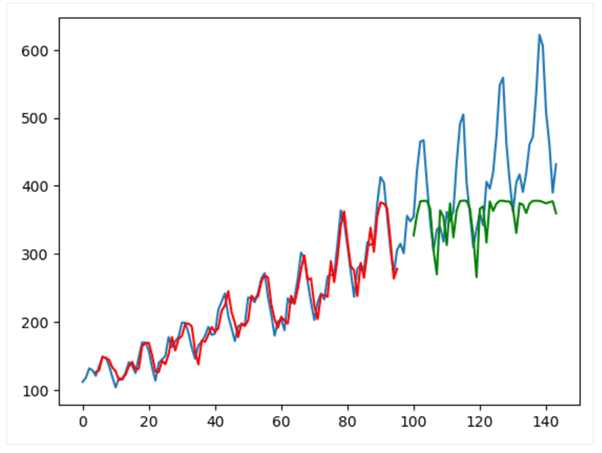 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
