机器学习中的销售预测2025年6月24日 | 阅读 14 分钟  机器学习是一种强大的工具,可用于预测销售并改善业务成果。在本文中,我们将讨论如何使用机器学习来预测销售以及可以用于此目的的不同方法。 机器学习销售预测方法
使用 Python 进行销售预测那么,现在我们将尝试使用各种机器学习技术来预测销售。 代码1. 导入库2. 数据加载与探索在将数据转换为每个模型将使用的结构之前,必须先加载数据。最基本的形式是,每行数据反映 10 家商店中一家商店一天的销售额。由于我们的目标是预测月度销售额,我们将首先将所有商店和天数相加,以获得总月度销售额。 输出  现在,我们将创建一个函数,用于提取 CSV 文件,然后将其转换为 pandas 数据框。 输出   上述函数返回一个数据框,其中每行代表按月计算的总销售额,列包括“日期”和“销售额”。 输出  在上述数据框中,现在每行代表商店在特定月份的总销售额。 输出  在上述数据框中,现在每行代表商店在特定年份的总销售额。 输出 <matplotlib.legend.Legend at 0x27280058fa0>  注意有许多替代模型可用于预测时间序列,包括加权移动平均模型和自回归积分移动平均(ARIMA)模型。其中一些需要先去除趋势和季节性。例如,如果您正在分析网站上的活跃访客数量,并且该数量每月增长 10%,则您需要从时间序列中排除此趋势。要获得最终预测,您需要在模型训练并开始进行预测后将趋势加回来。同样,如果您试图预测防晒霜的月度销售额,您可能会看到明显的季节性:由于防晒霜在夏季销售良好,因此每年都会重复相同的模式。 通过计算每一步的值与一年前的值之间的差值,例如,您将能够从时间序列中消除这种季节性(此技术称为差分)。同样,要获得最终预测,您需要在模型训练并进行多次预测后重新添加季节性模式。 3. EDA(探索性数据分析)我们将计算每个月销售额之间的差值,并将其添加为数据框中的新列,以使其平稳。 sales_time() 函数将以天、年和月为单位打印商店的总耗时。 输出  上述函数表示每个商店的销售额。 输出   上图表示每个商店的总销售额。 从上图可以看出,Store Id 2 的销售额最高,为6120128,Store Id 7 的销售额最低,为5856169。 输出  4. 确定时间序列的平稳性基本思想是模拟或估计序列中存在的趋势和季节性,然后将其减去以获得平稳序列。然后,该序列可以使用统计预测技术。通过重新添加趋势和季节性限制,预测值将随后被转换回原始尺度。 输出  5. 差分我们将使用这种方法来计算序列中后续词语之间的差值。通过差分通常可以消除变化的均值。 输出  现在,我们将为各种模型类型设置数据,以便它代表月度销售额,并且已被修改为平稳。 为此,我们将定义两个不同的结构
ARIMA 建模ARIMA(自回归积分移动平均)是一种流行的时间序列预测模型,用于单变量时间序列数据。 ARIMA 模型拟合时间序列数据以预测未来值。拟合 ARIMA 模型的过程包括选择AR、I 和 MA 分量的阶数,以及每个分量的系数。这些系数使用最大似然估计或数值优化等优化算法进行估计。然后可以使用生成的模型为时间序列的未来值生成预测。 输出  观察滞后观察滞后是 ARIMA 建模过程中的一个重要步骤。观察滞后的目标是确定 ARIMA 模型中自回归 (AR) 分量的阶数。自回归分量基于时间序列的过去值,AR 分量的阶数决定了用作预测变量的过去值的数量。 要观察滞后,通常会绘制时间序列的自相关函数 (ACF) 和偏自相关函数 (PACF)。ACF 是时间序列与其滞后版本之间相关性的图,而 PACF 是时间序列与其滞后值之间相关性的图,同时控制了任何中间滞后的影响。 为了构建一个新的数据框供其他模型使用,我们将每个字符分配给前一个月的销售额。我们将查看自相关图和偏自相关图,并使用 ARIMA 建模中选择滞后的指南来决定在我们的特征集中包含多少个月。通过这种方式,我们可以为 ARIMA 模型和回归模型保持恒定的回顾时间。 输出  回归建模回归建模是一种统计方法,用于对因变量和一个或多个自变量之间的关系进行建模。回归建模的目的是识别自变量和因变量之间的关系,并利用这种关系来预测因变量。 让我们创建一个 CSV 文件,其中包含销售额、因变量以及每个滞后的先前销售额的列,以及每行的月份。EDA 用于构建 12 个滞后特征。回归建模使用数据。 输出  输出  我们将分离数据,以便最后 12 个月属于测试集,其余数据用于训练模型。 训练和测试数据输出  6. 数据缩放数据缩放是指转换数据集中变量的值,使其处于相似的范围。这通常是为了防止某些变量因其较大的尺度而对模型产生不当影响。 输出  7. 反向缩放反向缩放是指将一组缩放后的变量转换回其原始尺度。当您希望根据原始变量而不是缩放后的变量来解释建模分析的结果时,可能需要这样做。反向缩放过程取决于用于缩放数据的方法。 现在我们有两个不同的数据结构
8. 预测数据框模型分数模型分数函数是衡量预测模型准确性或性能的函数。分数函数提供了模型做出准确预测的能力的量化度量,并用于比较不同的模型并为特定任务选择最佳模型。 这个辅助函数会将我们预测的均方根误差 (RMSE) 和平均绝对误差 (MAE) 保存到比较模型的性能。 Graph使用这个 plot_results() 函数,它将绘制模型的折线图。 建模我们将为我们的任务使用基础回归模型
现在我们将尝试通过每个模型找到 RMSE、MAE 和 R2 分数。 1. 线性回归线性回归是一种统计方法,用于对因变量和一个或多个自变量之间的线性关系进行建模。它是一种监督学习,这意味着它用于根据输入变量进行预测。 输出   随机森林回归器随机森林回归器是一种用于回归问题的集成学习方法。它是决策树算法的扩展,其中将多个决策树组合形成一个森林。 输出  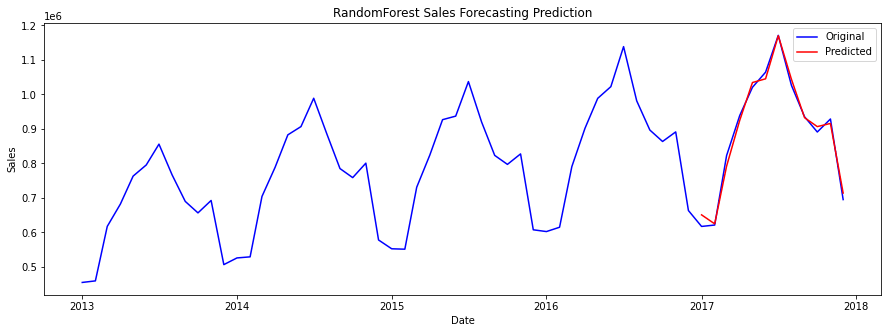 3. XGBOOSTXGBoost 回归是 XGBoost 算法在回归问题中的一个特定实现,其目标是预测连续的目标变量。它可以处理自变量和因变量之间的线性关系和非线性关系,还可以处理大型数据集和缺失数据。 输出   LSTMLSTM 是一种循环神经网络,特别适用于预测序列数据。 输出    ARIMA 建模输出   输出  比较模型在构建预测模型过程中,比较不同的机器学习模型是一个重要步骤。在比较模型时,应考虑几个因素,包括;准确性、训练时间、可伸缩性、模型复杂性、过拟合、可解释性、灵活性、预测时间等。 但在我们这里,我们将考虑 RMSE、MAE 和 R2 分数。 输出   输出  输出  在比较模型时,我们发现 XGBoost 的 RMSE 分数最低,为 13574.854582,这表明它在所有其他模型中的准确性最高。 通过百分比测试,我们发现 XGBoost 的预测占实际预测的 1.3%。 总的来说,机器学习可以成为预测销售和改善业务成果的强大工具。无论您是使用回归分析、时间序列分析、基于决策树的算法还是神经网络,机器学习都可以帮助您做出更准确的预测并采取行动来提高您的销售额。 注意:需要注意的是,与任何预测模型一样,预测的准确性将取决于用于训练模型的数据的质量和数量。因此,要设计一个好的模型,就必须对数据和潜在的业务问题有深刻的理解。结论总而言之,机器学习可以是企业手中预测销售和做出明智决策的强大工具。通过结合各种算法、历史数据和神经网络,企业可以提高销售额并为未来做出更好的决策。 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
