数据科学与机器学习的区别2025年4月12日 | 阅读 4 分钟 数据科学是关于数据清洗、准备和分析的研究,而机器学习是人工智能的一个分支,也是数据科学的一个子领域。数据科学和机器学习是两种流行的现代技术,它们正以惊人的速度发展。然而,这两个流行语,连同人工智能和深度学习,都是非常令人困惑的术语,因此了解它们之间的区别非常重要。在本主题中,我们将仅理解数据科学和机器学习之间的区别,以及它们之间的关系。 数据科学和机器学习密切相关,但功能和目标不同。乍一看,数据科学是研究从原始数据中获取洞察力的方法的领域。而机器学习是数据科学家团队用来使机器能够从过去的数据中自动学习的一种技术。为了深入理解区别,让我们先对这两种技术做一个简要的介绍。  注意:数据科学和机器学习密切相关,但不能互换使用。什么是数据科学?数据科学,顾名思义,就是关于数据的。因此,我们可以将其定义为“对数据进行深入研究的领域,包括从数据中提取有用的洞察力,并使用不同的工具、统计模型和机器学习算法处理这些信息。”这是一个用于处理大数据概念的领域,包括数据清洗、数据准备、数据分析和数据可视化。 数据科学家从各种来源收集原始数据,准备和预处理数据,并应用机器学习算法、预测分析来从收集的数据中提取有用的洞察力。 例如,Netflix利用数据科学技术,通过挖掘其用户的观看数据和模式来了解用户兴趣。 成为数据科学家所需的技能
什么是机器学习?机器学习是人工智能的一部分,也是数据科学的一个子领域。它是一项不断发展的技术,能够使机器从过去的数据中学习并自动执行给定任务。它可以定义为 机器学习通过计算机自身的经验,从过去中学习,它使用统计方法来提高性能并预测输出,而无需显式编程。 ML 的流行应用包括电子邮件垃圾邮件过滤、产品推荐、在线欺诈检测等。 机器学习工程师所需技能
机器学习在数据科学中的应用机器学习在数据科学中的应用可以通过数据科学的开发过程或生命周期来理解。数据科学生命周期中发生的步骤如下: 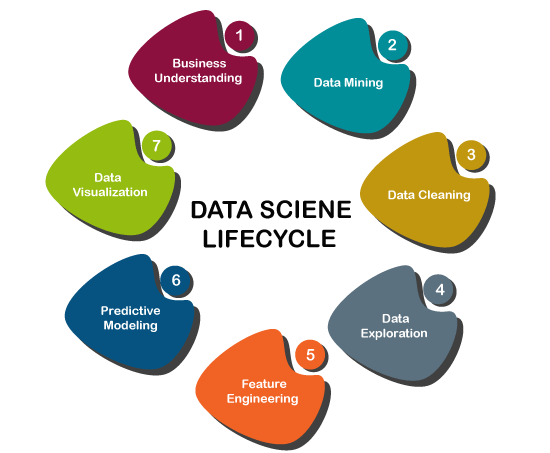
数据科学与机器学习的比较下表描述了数据科学和 ML 之间的基本区别
下一主题归纳学习与直推学习的区别 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
