线性回归与逻辑回归2025 年 2 月 12 日 | 阅读 8 分钟 线性回归和逻辑回归是监督学习技术下的两种著名的机器学习算法。由于这两种算法本质上都是监督式的,因此它们都使用带标签的数据集进行预测。但它们之间的主要区别在于使用方式。线性回归用于解决回归问题,而逻辑回归用于解决分类问题。下面将对这两种算法进行描述,并附有区别表。  线性回归
 在上图中,因变量在Y轴(薪资)上,自变量在X轴(经验)上。回归线可以写成: y= a0+a1x+ ε 其中,a0和a1是系数,ε是误差项。 逻辑回归

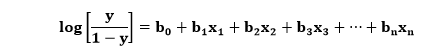 线性回归与逻辑回归的区别
高级选择题:线性回归 vs. 逻辑回归1. 您正在进行一项时间序列预测任务,股票价格是您感兴趣的变量。Fan和Tchernis(2008)的研究表明,数据存在异方差性,意味着方差不是恒定的。哪种模型对这个问题更具鲁棒性:哪种模型对这个问题更具鲁棒性?
答案: (b) 解释:异方差性违反了普通最小二乘法的假设,从而导致估计有偏。加权最小二乘法是指一种为数据点分配权重以增强模型方差的方法。 2. 一个组织希望预测客户满意度评分(介于1到5之间),这取决于他们的购买记录和客户的背景数据。考虑到所有这些因素,线性回归似乎是合理的。然而,该公司也很关心那些实际给出了5分的客户,这可以被认为是最佳满意度水平。以下哪种方法可能适用于这种情况?
答案: (b) 解释:有序逻辑回归测试也通常被称为比例优势模型。线性回归用于预测实值,而不是将它们分类到不同的类别,例如“高度满意”。因此,在对满意度分数进行排序时,有序逻辑回归将保持可解释性。 3. Lasso或L1正则化以使模型稀疏而闻名。从线性回归到使用Lasso的逻辑回归,这种属性在哪些方面发生了变化?
答案: (c) 解释:值得注意的是,稀疏性在这两种模型中的使用和功能几乎是相似的。Lasso回归通过惩罚系数或将其推向零来鼓励系数变小。两者都会呈现出基于数据和正则化程度的系数,这些系数可能变为零。 4. 您正在创建一个模型来检测欺诈。假阳性比假阴性造成的成本更高,因为真实的交易被错误地分类为欺诈。以下哪种指标最适合用于评估此任务的逻辑回归模型?
答案: (b) 解释:在欺诈检测中,假阳性的成本高于假阴性。特异度确定了被标记为欺诈类别的交易数量。 5. Dropout是一种常用于神经网络的优化方法。我们是否必须应用dropout来增强逻辑回归模型?为什么或为什么不?
答案: (c) 解释:可以通过训练网络并丢弃某些特征来对逻辑回归应用特征dropout。这样,模型就不会过度拟合某些属性,并能泛化其输出。 6. 在逻辑回归模型中,特征的系数为正表示什么意思?
答案: (a) 解释:逻辑回归中的正系数表示与正类概率呈正相关。随着特征值的增加,正类的对数优势也会增加,使其更有可能。 7. 与LASSO相比,岭回归(L2正则化)如何影响逻辑回归模型的可解释性?
答案: (b) 解释:岭回归将系数收缩至零,但不一定将其设置为零。这使得其比Lasso更易于解释,Lasso可以将系数设置为零,从而完全从模型中移除特征。 8. 在比较线性回归和逻辑回归模型的训练时间时,哪种说法最准确?
答案: (c) 解释:训练时间取决于各种因素,例如数据大小、特征数量和优化算法。没有关于哪个模型总是更快的通用规则,在许多情况下,差异可能可以忽略不计。 9. 在两个ML模型中,哪一个更容易受到高度相关特征问题的影响?
答案: (a) 解释:线性回归更容易受到多重共线性的影响,多重共线性是由高度相关的特征引起的。这可能导致系数不稳定和结果不准确。逻辑回归对此类问题不太敏感。 10. 在哪种情况下,逻辑回归通常被认为是比SVM更好的分类任务选择?
答案: (b) 解释:逻辑回归通过系数对特征与类别概率之间的关系进行建模。这些系数表明每个特征对结果的影响方向和强度。这使我们能够理解哪些特征对于做出预测最重要。 下一主题决策树分类算法 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
