基于内容的推荐系统2025年03月17日 | 阅读 9 分钟 基于内容的推荐系统通过分析用户偏好和物品的质量来生成建议。基本概念是根据用户过去感兴趣的物品的属性来推荐产品。这些系统主要依赖于物品的元数据,包括流派、关键词、描述和其他相关信息。 基于内容的推荐系统的工作原理基于内容的推荐系统遵循一个包含多个关键阶段的标准程序。目录中的每个物品首先根据其特征进行画像。例如,一部电影可以根据其导演、演员、流派和关键词来表征。详尽的画像使系统能够理解每个物品的独特属性。 随后,通过组合用户与之交互的物品的属性来形成用户画像。这些交互可以是隐式的——如点击、查看或购买——也可以是显式的——如评分。用户画像最终反映了他们的选择,这是基于他们喜欢的产品的特征。 然后,系统使用各种算法来确定物品之间的相似度,包括欧几里得距离、余弦相似度以及更复杂的算法,如词嵌入和 TF-IDF。该算法通过比较物品的特征,找出用户画像中最相似于目录中其他物品的物品。 最后,算法根据这些相似度评分生成建议。它推荐与用户画像最相似的产品,确保选择符合他们已有的品味。通过这种技术,基于内容的推荐系统可以为消费者提供高度相关和量身定制的推荐。 代码 为了更好地理解这个概念,我们将为电影构建一个内容推荐系统。 导入库读取数据集通常会有一个 EDA 来让我们了解我们要处理的数据。获取一些数据的洞察、信息甚至错误也很有用。 输出  输出  数据可视化现在,我们将从各个方面可视化数据。 输出  在这组特定数据集中,这两种电影类型的存在差异很大。 输出  电影的受欢迎程度仅受到预算和收入的一点点影响。 输出  大多数电影都高于黄线,这表明它们是有利可图的。 输出  “生活”、“一”、“找到”和“爱”等词似乎经常出现。 输出  剧情片占据了流派的主导地位,总共有 18,000 多部电影。 除了前五种流派外,数据集中还有其他流派。它们占所有电影流派的 38.67%。 输出  始于 1930 年的电影产业在过去 50 年中得到了极大的发展。 由于这些年份的数据较少,因此在 2020 年左右上映的电影总数有所下降。 输出  对于这组特定数据集中的电影,英语是原创和口语的主要语言。名单上参与度最高的演员是 Jr.,工作人员是 Cedric Gibbons。华纳兄弟是名单上影片最多的公司,有 1194 部电影。美国是许多优秀制作公司的所在地。因此,美国排名我们榜首的制片国也就不足为奇了。 输出  评分在 0 或 10 的电影主要是由于投票人数很少。随着投票次数的增加,评分可能在 5 到 8.5 之间。正如上面的曲线所示,受欢迎的电影显然会获得更高的投票数。 输出  剧情片是持续时间最长的电影流派。浪漫是前五名中最不常见的流派。与其它电影相比,动作片的制作成本更高。与其它动作片相比,其中一部影片获得了可观的利润。评分在 0 或 10 的电影主要是由于投票人数很少。随着投票次数的增加,评分可能在 5 到 8.5 之间。正如上面的曲线所示,受欢迎的电影显然会获得更高的投票数。 输出  三个关键因素将决定电影的收入:投票人数、预算以及它们的受欢迎程度。 推荐系统有很多方法可以用来构建推荐系统。我们将使用一种方法,通过它可以根据不同的特征为用户创建可以输出推荐电影的推荐系统。 如果您查看我们的数据集,里面有大量有价值的信息,如流派、概述等。之后,我们将使用这些信息来使我们的推荐系统更加强大。我们将这些信息提取到一个词袋中,然后将其与加权平均值结合,以获得电影的最终相似度。 人们看电影不仅是因为他们读到过好评,还因为围绕电影的炒作。因此,在这种情况下考虑受欢迎程度是有意义的。 加权平均值应占 40% 的权重,受欢迎程度应占 60% 的权重,这样人们就不会错过一部有话题性的电影,即使它评价不高或评分很低。您可以随意尝试这些数字。接下来,我们创建一个名为 score 的新列来保存结果。 输出 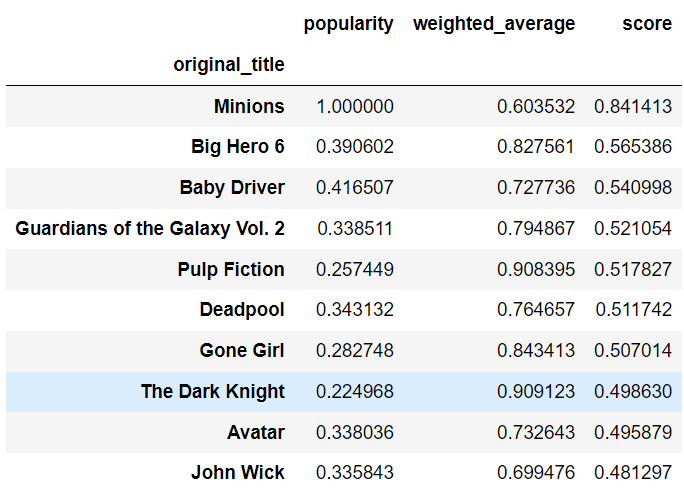 现在我们将这些分数与相似度分数结合起来。 输出  余弦相似度方法是确定两部电影相似度的流行技术。当然,您可以尝试多种技术,如 sigmoid 和欧几里得,看看哪种效果最好。 然而,计算所有电影之间的相似度成本很高。因此,由于内存限制,我们只从 weighted_df_sorted 中获取前 10,000 部电影。 输出  输出  我们可以快速确定用户大部分时间是否喜欢看剧情片。此外,他或她对该类型评价很高。我们推荐另外五部剧情片,我们认为观众也会喜欢它们,就像他们已经看过的电影一样。 下一主题情境感知推荐系统 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
