机器学习中的归一化2025年6月18日 | 阅读 5 分钟 归一化是最常用的数据预处理技术之一,它帮助我们将数据集中的数值列的值转换为使用相同的比例尺。  尽管机器学习中的所有数据集并非都必须进行归一化,但在数据集的属性范围不同时,通常会使用它。它有助于提高机器学习模型的性能和可靠性。在本文中,我们将简要讨论机器学习中的各种归一化技术、其用途、机器学习模型中的归一化示例等等。那么,让我们从机器学习中归一化的定义开始。 机器学习中的归一化是什么?归一化是机器学习中一种应用于数据准备的缩放技术,用于将数据集中的数值列的值转换为使用相同的比例尺。它并非对模型中的所有数据集都必需。仅在机器学习模型的特征范围不同时才需要。 在数学上,我们可以使用以下公式计算归一化
示例: 假设我们有一个模型数据集,其中特征的最大值和最小值如上所述。为了归一化机器学习模型,会移动和重新缩放值,使其范围可以在 0 和 1 之间变化。此技术也称为最小-最大缩放。在此缩放技术中,我们将按以下方式更改特征值 情况 1- 如果 X 的值为最小值,则分子值将为 0;因此归一化也将为 0。 将 X = Xminimum 代入上述公式,我们得到; Xn = Xminimum - Xminimum / (Xmaximum - Xminimum) Xn = 0 情况 2- 如果 X 的值为最大值,则分子值等于分母;因此归一化将为 1。 将 X = Xmaximum 代入上述公式,我们得到; Xn = Xmaximum - Xminimum / (Xmaximum - Xminimum) Xn = 1 情况 3- 另一方面,如果 X 的值既不是最大值也不是最小值,那么归一化值也将介于 0 和 1 之间。 因此,归一化可以定义为一种缩放方法,其中值被移动和重新缩放以将其范围维持在 0 和 1 之间,换句话说;它可以称为最小-最大缩放技术。 机器学习中的归一化技术尽管机器学习中有许多特征归一化技术,但其中一些是最常用的。它们如下
标准化缩放也称为Z-分数归一化,其中值围绕均值居中,标准差为单位,这意味着属性变为零,并且结果分布具有单位标准差。在数学上,我们可以通过将特征值减去均值然后除以标准差来计算标准化。 因此,标准化可表示为 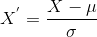 在此,µ 代表特征值的均值,σ 代表特征值的标准差。 然而,与最小-最大缩放技术不同,在标准化技术中,特征值不受限于特定范围。 此技术对于使用距离度量(如KNN、K-均值聚类和主成分分析等)的各种机器学习算法很有帮助。此外,重要的是模型是基于假设构建的,并且数据呈正态分布。 归一化与标准化的区别
何时使用归一化或标准化?哪种方法适合我们的机器学习模型,归一化还是标准化?这可能是所有数据科学家和机器学习工程师之间的一个巨大困惑。尽管这两个术语的意思几乎相同,但选择使用归一化或标准化将取决于您的问题和模型中使用的算法。 1. 归一化是一种转换技术,有助于更好地提高模型的性能和准确性。机器学习模型的归一化在您不确切了解特征分布时很有用。换句话说,数据的特征分布不遵循高斯(钟形曲线)分布。归一化必须有一个充足的范围,所以如果您数据中有异常值,它们会受到归一化的影响。 此外,它也适用于具有变量缩放技术的(如KNN、人工神经网络)数据。因此,您不能对数据分布做假设。 2. 机器学习模型中的标准化在您确切了解数据特征分布的情况下很有用,换句话说,您的数据遵循高斯分布。但是,这不一定为真。与归一化不同,标准化不一定有一个固定的范围,所以如果您数据中有异常值,它们不会受到标准化的影响。 此外,它还适用于数据具有可变维度的情况,例如线性回归、逻辑回归和线性判别分析等技术。 示例: 让我们理解一个实验,其中我们有一个具有两个属性的数据集,即年龄和薪资。其中年龄范围从 0 到 80 岁,收入从 0 到 75,000 美元或更高。假设收入是年龄的 1,000 倍。因此,这两个属性的范围彼此差异很大。 由于其较大的值,当我们在进行进一步分析(例如多元线性回归)时,收入属性将自然地对结论产生更大的影响。然而,这并不一定意味着它是一个更好的预测因子。因此,我们对数据进行归一化,以便所有变量都在相同的范围内。 此外,它还有助于预测信用风险分数,其中对除类别列之外的所有数值数据应用归一化。它使用tanh 转换技术,将所有数值特征转换为 0 到 1 之间的值。 结论归一化通过创建新值并保持数据的整体分布和比率来避免原始数据和各种数据集问题。此外,它还通过各种技术和算法提高了机器学习模型的性能和准确性。因此,归一化和标准化的概念有点令人困惑,但对于构建更好的机器学习模型至关重要。 下一个主题组在交叉验证中 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
