机器学习中的损失函数2025年6月8日 | 阅读12分钟 机器学习算法使用损失函数将模型的预测值与实际发生的情况连接起来。它们利用模型预测值与实际发生值之间的差异来检查模型的准确性。这种损失需要在引导优化过程以获得更好的模型方面发挥关键作用。在本章中,我们将讨论一系列在机器学习问题中经常应用的损失函数,并按回归或分类进行分类。 机器学习中损失函数的重要性机器学习模型通过使用损失函数来学习使其预测值与实际数据匹配;如果我们训练时保持低损失水平,模型会变得越来越准确。 选择最佳损失函数非常重要,因为它会极大地影响模型的输出。模型的选择必须基于手头问题的类型——回归、分类或其他——才能获得最佳结果。 损失函数对于训练机器学习模型至关重要,因为它实现了几个主要目的:
通过这个分数,可以清楚地判断模型预测的准确性与实际结果的比较。
通过损失函数,模型被指示如何调整其参数(权重)以减少误差并随时间做出更好的预测。
合适的损失函数支持偏差和方差之间的平衡,从而在训练期间未使用的模型数据上获得更好的结果。
模型的行为可能取决于所使用的损失函数——有些可以保护模型免受异常值的影响,而另一些则可能根据应用的目標来突出或惩罚某些错误。 损失函数如何工作?即使损失函数有不同的形式,它们都衡量模型预测与目标值之间的差异。这种测量被称为预测误差。误差对于机器学习很重要,因为它表明了在优化步骤中如何进行权重调整。每次模型使用新数据进行训练时,它都会使用损失来更新其设置,帮助它进行正确的预测并减少错误。 在机器学习和神经网络领域,经验风险最小化(ERM)的思想经常适用。ERM通过旨在最小化在测试训练数据集中的每个示例时出现的损失来帮助您选择最佳参数。 在ERM中,通过从已知数据中学习来降低风险,侧重于从过去的样本中学习。其要点是构建一个在训练数据上表现良好,并且还能成功处理具有相似统计模式的数据的模型。因此,ERM在确保模型既合适又可靠方面发挥着关键作用。 不同类型的损失函数机器学习算法通过损失函数进行评估。测试人们的方法通常按所需思维类型进行分类。 回归损失函数:当数值预测是连续的时,模型可以用于回归。 分类损失函数模型帮助为结果选择多个预定义结果之一时,该函数起作用。 选择正确的损失函数很重要,因为它有助于模型对预测或分类任务的独特要求做出适当的响应。 机器学习中的回归损失函数回归涉及学习如何预测与类别无关的值,您经常在股票价格、房价和温度读数中找到这些类型的数字。让我们看看解决回归问题最常见的损失函数。 1. 均方误差,也称为 L2 损失MSE,也称为 L2 损失,在解决回归问题中被广泛使用。它计算预测值与实际目标值之间差异的平均值的平方。将误差乘以自身,使得 MSE 对远大于平均值的偏差具有更高的敏感性。通过对平方误差取平均值,可以为每个案例提供模型性能的无偏度量。 您可以使用以下公式计算 MSE:  Python 实现 何时使用 MSE?当您想重罚回归模型中的较大误差时,均方误差 (MSE) 是一个绝佳的选择。MSE 通过使用平方差来实现这一点,这意味着模型在减少主要误差方面分配了更大的权重。 当异常值代表重要信息时,MSE 最适合此任务。当大的错误导致大后果或重罚时,使用 MSE 是合理的。另一方面,在数据中包含带有噪声信息的异常值会导致模型过拟合。 机器学习的一个例子是预测房地产价格,考虑位置、大小以及房产离重要便利设施的距离。由于一个区域的房价往往遵循可预测的模式,因此对主要的异常值进行惩罚至关重要。一栋 20 万美元的房子按低于广告价 5% 的价格购买,意味着 1 万美元的误判,因此 MSE 确保增加对更大错误的惩罚。 使用 MSE 的优点和缺点优点
缺点
2. 平均绝对误差 / L1 损失L1 损失或平均绝对误差 (MAE) 是一种您经常用于回归问题的损失函数。它是实际目标值与预测值之间绝对差的平均值。MAE 与均方误差 (MSE) 的主要区别在于,MAE 为所有误差分配的权重与 MSE 转化为平方误差的权重相同,而 MAE 则是...。这并不意味着这样做会不成比例地惩罚较大的误差。 MAE(L1 损失)的公式为:  Python 实现 何时使用 MAE 例如,平均绝对误差 (MAE) 计算预测值与实际值之间的绝对差的平均值,并且与均方误差 (MSE) 相比,它对异常值的敏感度较低,因为它不对误差进行平方。MSE 因所有误差相等而重罚大误差,而 MAE 则所有误差都相等。 在异常值不应对模型产生不成比例影响的情况下,MAE 非常有用。例如,如果您在 UberEats 或 DoorDash 这样的公司工作,并且您试图预测送餐给顾客所需的时间,那么由于天气或交通等原因造成的罕见延迟可能属于异常值。 由于 MAE 不会过度惩罚这些异常,因此模型也能学习预测这些情况,同时提供更均衡、更现实的送餐时间估算。因此,这种统一的误差处理可以防止极端情况的过度或低估。 MAE 使用的优点和缺点 优点
缺点
3. 平均偏差误差 (MBE)与均方误差不同,平均偏差误差产生准确结果的能力稍弱。主要优点是它告诉你预测误差可能向哪个方向发展。使用 MBE,通过指出模型是持续高估还是低估测量值,可以找出模型是否持续存在偏差。因此,模型可以进行调整以发现和处理系统性问题。即使它不是判断准确性的最佳方法,MBE 也有助于揭示模型的优势和劣势,并显示在哪里可以提高性能。 公式  Python 实现 4. Huber 损失 / 平滑 MAEHuber 损失结合了 MSE 和 MAE 的优点,因此在需要鲁棒性和敏感性的回归中非常完美。如果预测仅有轻微不准确,该方法的功能与 MSE 相同,增加了模型的敏感性。当出现较大误差时(通常是由于异常值),平均值会被 MAE 取代,因此对学习结果的影响较小。 在 MSE 和 MAE 之间的边界处,有一个称为 delta 的超参数,它决定了损失函数何时从一种模式跳转到另一种模式。因此,该函数始终是光滑的,并且可以使用梯度进行优化。由于数据集可能包含噪声或一些异常值,因此它在实际情况下非常有用,可以提供经过仔细平衡的训练过程。 公式  Python 实现 Huber 损失或平滑平均绝对误差的使用如果用于回归的数据包含异常值和噪声,Huber 损失通过同时提高准确性且不忽略小误差来帮助您很好地管理误差。它使用两种不同的操作方式,由阈值 delta 决定。如果预测误差小于 δ,Huber 损失的行为就类似于均方误差 (MSE),开始惩罚小的预测误差,以帮助模型变得更准确。 当误差大于 δ 时,该指标使用像 MAE 这样的线性方法,这可以控制异常值,并使罕见的极端情况不那么重要。Huber 损失的工作方式允许该方法处理数据中的误差,同时保持良好的性能。 Huber 损失的优缺点优点
缺点
机器学习中的分类损失函数这些类型的函数计算分类模型标记数据的正确程度。它们通过查找预测类别与实际类别不同的次数来衡量模型的性能。分类损失函数是根据问题类型和所用模型的类型来选择的。 1. 交叉熵损失在大多数情况下,机器学习中的分类任务会求助于交叉熵损失,也称为负对数似然。它区分了预测值与实际发现值之间的差异,并根据置信度分数对错误的答案进行收费。 每当图片实际情况的预测概率降低时,损失也会增加。当预测概率与真实标签相差甚远时,误差就会增加。由于这种特性,交叉熵可以引导模型走向更高的预测准确性。在训练时,模型会改变其参数,以便预测概率更能匹配真实标签。对于涉及两个以上或仅两个唯一类的问题尤其有用。 公式  Python 实现 何时应尝试使用二元交叉熵损失(对数损失) 对于需要将输入分组为两个类的情况,二元交叉熵 (BCE) 损失是常态。该方法通过查找每个数量的平均值来计算损失,一个用于正样本 y×log(f(x)) 的情况,另一个用于负样本 (1−y)×log(1−f(x)) 的情况。它找出模型预测样本应标记为 0 还是 1 的准确程度。 BCE 鼓励模型对样本的概率预测更接近真实标签。当 BCE 训练期间经历的损失较小时,模型能够更好地进行正确的二元分类,这就是为什么它仍然是这类问题中的关键损失函数。 2. Hinge 损失最大间隔分类任务,例如支持向量机 (SVM) 中的任务,通常使用多类 SVM 损失,通常称为 Hinge 损失。它确保点被正确分配,并且免受用于泛化或进行未来预测的决策边界的影响。 作为一个凸函数,Hinge 损失使模型更容易训练,并帮助它们以更清晰的间隔分割类别。由于此功能,它在减少错误分类数据和使模型更鲁棒方面表现更好。在某些情况下,当按最大间隔分离类别最重要时,Hinge 损失在 SVM 模型中被广泛使用。 公式 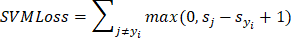 Python 实现 3. KL 散度作为 Kullback-Leibler 散度KL 散度是一种衡量一个概率分布与参考或真实分布的差异程度的方法。它提供了一种比较不同分布的方法,这在我们模型的概率生成时非常有用。 您可以在分类中看到 KL 散度的使用,主要与softmax 一起使用,当它为各种类别生成概率时。KL 散度较低的模型能够预测与真实标签分布非常匹配的标签。得益于此,它在语言、生成新数据的模型和变分推理中很有用。 公式  Python 实现 选择正确损失函数的步骤您的深度学习模型的成功在很大程度上取决于您使用的损失函数。让我们看一些要点,以帮助您找到正确的。 1. 理解任务 检查您的模型要解决的问题类型。对于回归,选择均方误差或平均绝对误差;对于分类,选择交叉熵;考虑对比损失或三元组损失用于排名,并使用 Dice 或 Jaccard 损失用于分割。 2. 考虑输出类型 注意您的模型创建的输出类型。如果您的变量是连续的,请选择 MSE 或 MAE 等回归损失。对于分类标签,请选择分类损失函数。CTC 损失最适合语音或手写数据中的损失估计。 3. 处理不平衡数据 当您的数据集不平衡,一个类别更常见时,请选择旨在处理这种情况的损失函数。得益于 Focal Loss,模型更有可能关注困难或不常见的案例,这有助于其学习过程。 4. 对异常值具有鲁棒性 当您的数据中存在异常值时,请选择不受其太大影响的损失函数。Huber 损失证明很有用,因为它保留了 MSE 和 MAE 的优点,使计算对异常值具有鲁棒性。 5. 性能和收敛性 选择有助于网络快速学习并高效工作的损失函数。有时,SVM 中使用的 Hinge 损失技术在分类工作中优于交叉熵。 结论总之,损失函数衡量预测结果与真实结果之间的差异,这有助于模型在训练期间学习。模型的成功和准确性在很大程度上取决于为任务选择合适的损失函数:回归、分类、排名或分割。使用不同的损失函数会改变它们对异常值的反应方式、它们的鲁棒性以及它们可以处理的输出数据类型。 了解这些函数及其作用有助于数据科学家做出决策。当我们选择正确的损失函数时,模型可以更好地处理训练,更快地找到解决方案,并且其预测更准确,从而使机器学习模型更值得信赖。 下一主题机器学习中的特征选择技术 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
