机器学习中的竞技跑者伤病预测2025年3月17日 | 阅读 12 分钟  跑步是一项世界范围内流行的运动,有大量的人参与诸如慢跑、跑步或越野跑等活动。仅在美国,2017 年就有约 6000 万人参与这些活动。然而,令人担忧的统计数据表明,大约一半的跑步者每年都会遭受伤病。处理这些伤病可能是一个困难且耗时的过程,促使跑者采取各种策略来尽量减少受伤的可能性。其中一些预防措施包括使用泡沫轴、按摩以及寻求专业教练的指导。不幸的是,并非每个人都能负担得起这些资源,这使得伤病预防成为许多跑者面临的一个重大问题。 为了应对这一担忧,专家和数据科学家正日益拥抱机器学习的能力,以预测和避免竞技跑者的伤病。通过利用复杂的算法和广泛的数据集,机器学习模型能够彻底改变伤病预防方法,最终提升运动员的整体福祉。 利用机器学习预测竞技跑者的伤病的好处
利用机器学习预测竞技跑者的伤病的挑战虽然机器学习在伤病预测方面具有潜力,但仍存在一些重大挑战需要解决。
使用 Python 进行机器学习伤病预测关于数据集该数据集包含来自一个著名的荷兰高水平跑步队七年(2012-2019)的综合训练日志。它涵盖了参加 800 米到马拉松比赛的中长跑运动员。选择这些运动员是因为他们具有可比的耐力型训练方案。值得注意的是,在数据收集期间,该队的主教练保持一致。 数据集中有 74 名跑步者的记录,其中 27 名女性和 47 名男性。平均而言,这些运动员在队里约有 3.7 年。大多数跑步者参加国家级比赛,其中一些参加国际比赛。本研究严格遵守赫尔辛基宣言的指导方针,并获得了第二作者所在机构伦理委员会的批准。 在这里,我们将尝试预测竞争对手的伤病,并寻找最佳的伤病预测模型。
我们将从基本的数据探索开始,以确定数据集是否包含任何异常或不一致之处。 输出  输出  输出 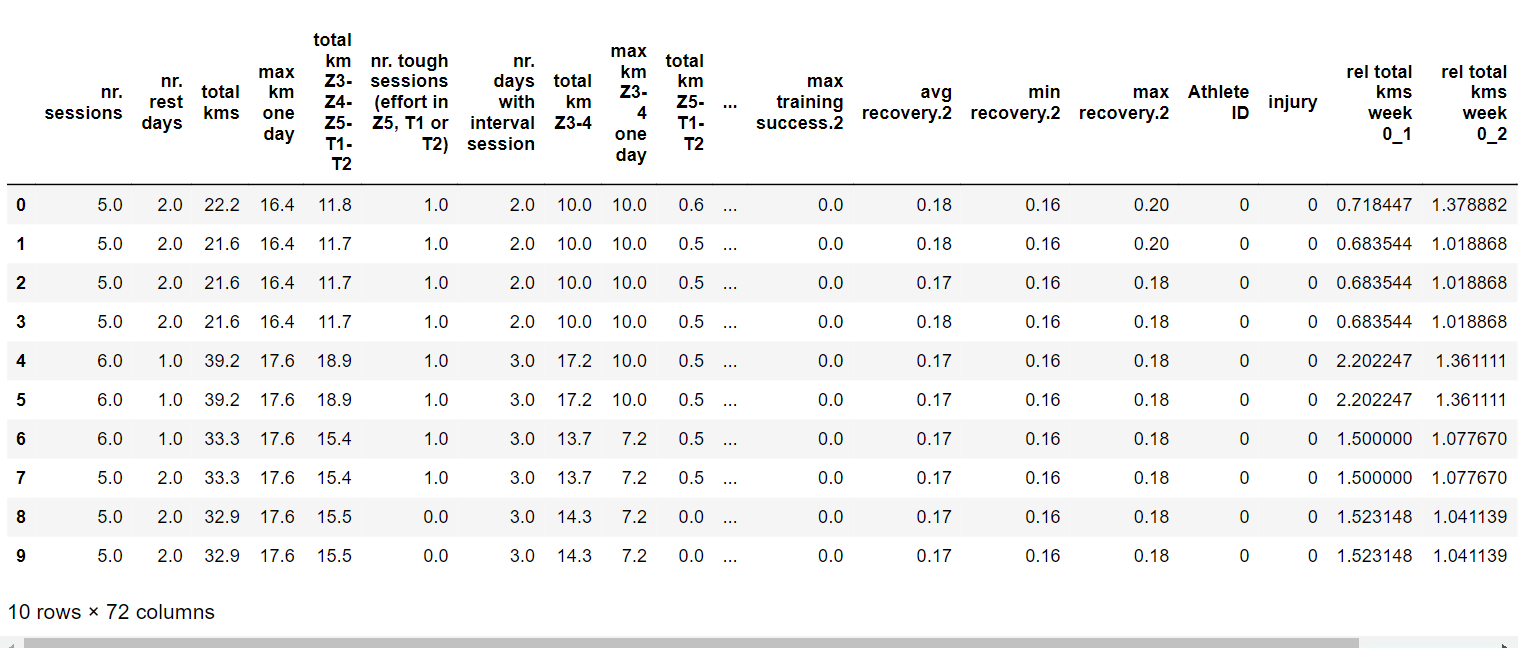 我们拥有的数据集维度非常高,这使得数据分析难以开始。为了简化流程,我们决定根据经验分析删除某些属性。具体来说,我们移除了与个人感觉有关的属性,因为我们希望仅根据量化的跑步质量来预测数据。尽管与恢复有关的属性可能提供有价值的见解,但仅依赖调查问题来评估跑步者的身体状况是具有挑战性的,并且可能无法产生准确的结果。为了保持客观并采取数据驱动的方法进行分析,我们选择排除主观属性,并侧重于更具体和可衡量的因素。 输出        经过仔细分析,我们已成功将数据集中的属性数量从 72 个减少到 41 个。虽然这一进展前景喜人,但数据集的维度仍然很高,给进一步的分析和建模带来了挑战。 输出  总共有 74 名运动员在该数据集中。现在,让我们专注于检查第一名运动员的训练数据,以了解他们的训练模式。 输出  这张图提出了一些有趣的问题。我们想知道为什么这位特定运动员的训练会持续这么长时间显著下降。如果每个数据点代表一周,受伤超过一百周似乎不寻常。或者,如果数据点表示天数,受伤一百天仍然相当多,值得进一步调查。 数据集中带有 '.1'、'.2' 和 '.3' 的属性令人困惑。即使参考了元数据文件,我们也难以理解它们与日期属性的相关性。这些属性的含义和相关性仍然不清楚,需要进一步澄清。 输出      此数据集中“日期”属性也令人费解。为了更清楚地理解其重要性,我们将尝试将其可视化并探索其模式。 输出   运动员的“日期”属性从 400 突然跳到 700 令人困惑并引发疑问。为了进行准确的预测和有效分析数据,我们需要连续且顺序的日期。尽管存在一些不确定性和潜在的见解缺失,我们仍将尝试对跑步数据进行分类。此外,我们的数据探索揭示了数据集中非受伤数据点存在显著偏差。这种不平衡可能会影响模型的性能和预测。 输出  在此可视化中,我们可以清楚地看到数据集在非受伤情况上的倾斜程度。 输出  为了防止我们的预测模型过拟合,我们已经使用抽样技术平衡了数据集。这确保了受伤和未受伤的病例在训练数据中都有同等的代表性。
在这里,我们将采用各种机器学习算法以及它们的准确性和混淆矩阵。 让我们首先演示偏斜数据集的影响。在不平衡的数据集中,分类器的准确性似乎非常高,因为它只是将所有数据点识别为未受伤。然而,这种方法对于本项目お目标无益,因为它未能准确预测受伤病例。 输出  输出 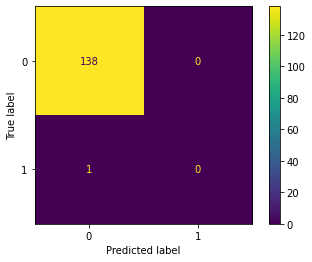  在上图的混淆矩阵中,所有数据点都被分类为未受伤。为了解决这个问题,我们将继续使用平衡数据集。 输出  在此分析中,我们观察到随着 k 参数的增加,训练准确性明显下降(从约 80% 降至 65%),而测试准确性略有提高(从约 58% 升至 60%)。为了评估模型在处理未受伤和受伤数据方面的性能,我们将使用混淆矩阵。 输出   当 k 值为 2 时,分类器在预测未受伤数据方面表现出更高的准确性。 输出    当使用 k 值为 21 的高值时,伤病预测变得更准确。然而,这也导致了对未受伤数据的误报显著增加,这意味着分类器错误地将更多未受伤的人识别为受伤。 经过对各种参数值的广泛实验,我们确定了 k 值为 12 的最佳平衡点。该分类器实现了 60% 的整体准确率,其中预测未受伤数据点的准确率为 52%,预测受伤数据点的准确率为 68%。考虑到数据集固有的偏差,这个准确性水平是值得称赞的。尽管如此,我们仍在探索替代的二元分类器和不同的平衡方法,以进一步提高我们预测的准确性。 下面的代码演示了使用**支持向量机分类器**对数据点进行伤病预测。为了处理数据集不平衡的性质,我们采用了欠采样技术。通过平衡受伤和未受伤病例的代表性,我们旨在提高分类器在预测这两个类别方面的准确性。 输出   在下面的代码中,我们使用支持向量机分类器来预测一个数据点是否对应于伤病。为了解决我们不平衡数据集的问题,我们采用了过采样技术。这种方法通过复制或生成少数类(受伤数据)的额外实例来创建更平衡的数据表示,从而使分类器能够更准确地预测受伤和未受伤的病例。 输出   在下面的代码中,我们实现了一个带欠采样的 Bagging 分类器来预测一个数据点是否对应于伤病。 输出   在下面的代码中,我们实现了一个带过采样的 Bagging 分类器来预测一个数据点是否对应于伤病。 输出   在这里,我们使用 Bagging 分类器来预测一个数据点是否受伤,并使用欠采样技术来应对我们不平衡的数据集。 输出   我们采用**Bagging 分类器**来确定一个数据点是否对应于伤病,通过使用过采样技术来解决数据集的不平衡。 输出   模型准确性主要受所使用的采样方法的影响。过采样方法在对未受伤数据点进行分类方面表现更好,而欠采样方法在准确识别受伤数据点方面表现出色。 为了平衡数据集,我们应用了**采样、过采样和欠采样**等各种策略。之后,我们使用 KNN、SVM、Bagging 和 XGBooster 等多种二元分类器评估了不同的平衡数据集。**XGBooster 和 Bagging** 取得了最佳性能,准确率高达约 99%。 利用机器学习预测竞技跑者伤病的未来展望机器学习在运动医学和运动员护理方面具有巨大的潜力。随着可穿戴技术和数据收集方法的进步,机器学习模型可以分析全面的数据集,提供对运动员表现、生物力学和生理参数的更深入的见解。整合多模式数据,如遗传学和环境条件,可能会揭示导致伤病风险的新模式。纵向研究对于通过长期监测运动员来构建准确的预测模型至关重要。 此外,机器学习可以根据个体特征提供个性化的伤病预防计划。通过接受这些进步,伤病预测可以优化运动员的表现,并培养一个更健康、更成功的运动社区。 结论利用机器学习预测竞技跑者的伤病,为革新运动医学和改善运动员福祉带来了巨大希望。借助先进的算法和广泛的数据集,机器学习模型提供了实时的伤病风险评估、个性化的训练指导以及数据驱动的伤病预防策略。 然而,通过解决数据质量、模型可解释性以及考虑复杂的风险因素相互作用等挑战,可以充分实现机器学习在伤病预测中的全部优势。数据科学家、运动医学专家、教练和运动员之间的合作将是克服这些障碍并充分发挥机器学习在竞技跑步中的潜力的关键。 随着研究人员和从业者探索各种可能性,通过机器学习进行伤病预测可以彻底改变竞技跑者进行训练、恢复和伤病预防的方式,最终带来一个更健康、更成功的运动社区。 下一个主题利用机器学习进行蛋白质折叠 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
