机器学习的“没有免费午餐”定理2025年8月12日 | 阅读 7 分钟 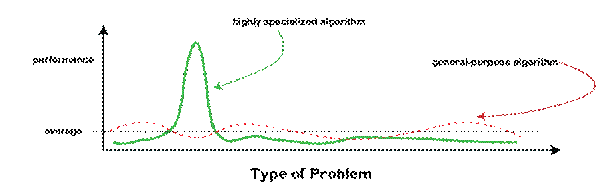 这是优化和机器学习中的一个基本定理,它指出没有优化算法在所有可能的问题上都优于所有其他算法。这些原则最初由 David Wolpert 和 William Macready 在 20 世纪 90 年代提出,它们实际上提供了对算法设计固有局限性的洞察,并理解应该用什么方法来处理什么样的问题。尽管该定理本身具有成为一个成熟的、理论驱动的、纯粹的数学发现的所有特征,但它对现实世界应用的影响非常广泛,尤其是在机器学习、进化算法和人工智能领域。 NFL 定理源于优化领域,优化就是从一组可行解中找到问题最佳解决方案的追求。优化问题有各种各样的形式和形状,从最小化成本和最大化与业务相关的收入到训练机器学习模式。 在 NFL 定理出现很久之前,人们普遍认为有些算法在解决优化问题方面明显优于其他算法。例如,已经证明大多数算法在包括梯度下降、模拟退火和遗传算法在内的各种应用中都取得了成功。另一方面,Wolpert 和 Macready 的定理表明,如果考虑所有可能的优化问题,没有一个算法最终会比所有其他算法都好。也就是说,一个算法的成功与其问题的特定特征是相辅相成的。如果一个算法在一个类型的问题上表现得非常好,那么它几乎肯定会在另一个问题上表现得很糟糕。 NFL 背后的核心思想机器学习的免费午餐(NFL)定理指出,没有一个算法对所有潜在问题都是最佳的。如果一个算法对一种任务有效,那么它在其他任务上仍然表现不佳。每个算法都对数据的分布或结构做出了某些假设,这就是发生这种情况的原因。当假设被数据验证时,算法效果很好。当假设不正确时,它的表现会更差。例如,决策树可能适用于结构化的表格数据,但不适用于语音或图像数据。该定理指出,成功取决于问题数据的类型和领域,并且不存在通用的最佳模型。对于金融预测,用于医疗诊断的有效模型可能不适用。 因此,机器学习专家不应依赖单一的模型或技术。相反,他们应该分析数据,尝试不同的算法,并使用交叉验证等技术来确定哪些算法效果最好。正如 NFL 定理所强调的,测试领域知识模型和做出深思熟虑的设计选择至关重要。选择现实的模型对于在现实世界中取得成功至关重要,它提醒我们,问题总是决定机器学习算法的有效性。 免费午餐定理的数学表述现在可以对优化问题的免费午餐定理进行正式表述如下: “给定任意两个优化算法 X 和 Y,X 在所有可能问题上的平均性能等于 Y 在所有可能问题上的平均性能。” 更简单地说,这意味着对于一个算法可以应用的任何问题,没有一个算法比所有其他算法都更适合该问题。事实上,这适用于确定性和随机算法,其结果是无论它如何选择策略——随机的还是固定的——它在所有问题上的策略选择都不会更好。 机器学习的 NFL 定理指出,考虑到机器学习算法可以学习的所有函数,不同算法的准确性平均而言是相同的;因此,不存在更好的学习算法。 NFL 定理背后的直觉为了理解 NFL 定理背后的直觉,可以考虑一个类比。假设你有一个工具箱,里面放着各种工具:锤子、螺丝刀、扳手等等。每种工具都有其特定的工作或熟练度。例如,锤子非常适合敲钉子的工作。另一方面,螺丝刀非常适合拧螺丝的工作。锤子拧螺丝的效果不好,而螺丝刀敲钉子的效果也不好。 从这个意义上说,优化算法就是工具。每种算法都旨在利用手头问题的某些特定属性。当算法用于具有这些属性的问题时,它可以高效地解决它们。当试图将其用于不具备算法设计特性的问题时,其性能会下降。NFL 定理只是将这种直觉形式化,表明不存在可以最优地解决所有问题的“通用工具”或算法。 免费午餐定理的影响NFL 定理主要意味着算法的选择取决于问题。它的意思直接表明,没有一个优化算法或机器学习算法可以在所有问题上都表现良好。首先,从业者必须理解问题的特性,如结构特性、约束或数据性质。 例如,梯度下降算法用于凸优化,当解决方案空间只包含一个全局最小值时。非凸问题有局部最小值。在这些问题中,使用梯度下降可能难以识别全局最优解,而模拟退火或遗传算法则更合适。 免费午餐(NFL)定理在现实世界中的例子和情况在现实世界的机器学习应用中,一个常见的观察是免费午餐(NFL)定理。以下是一些强调其重要性的现实世界示例。
NFL 在监督学习 vs 无监督学习中的应用免费午餐(NFL)定理的基本原则——没有单一的算法是所有潜在问题的最佳选择——在监督学习和无监督学习中的应用方式不同。 1. 监督学习中的 NFL 在监督学习中,算法通过标记数据进行训练以生成预测。NFL 定理意味着它
2. 无监督学习中的 NFL 在无监督学习中,目标是在无标记数据中寻找结构或模式。
常见问题1. 为什么 NFL 定理在模型选择和评估中很重要? NFL 定理警告从业者不要盲目依赖知名或经过训练的模型,这就是它在模型选择和评估中如此重要的原因。相反,它鼓励谨慎的验证和测试。由于没有一种算法在所有领域都更好,数据科学家必须仔细考虑问题领域,并通过交叉验证来测试不同的模型以分析性能。它确保模型选择是基于任务的适用性而不是趋势。 2. NFL 定理是否适用于监督学习和无监督学习? 取决于噪声和数据分布,监督学习算法(如决策树或神经网络)可能在某些任务上表现良好,而在其他任务上表现不佳。PCA、DBSCAN 和 k-means 是无监督学习技术的例子,它们的表现会根据数据的密度、尺度和形状而有所不同。根据 NFL 定理,无论学习范式如何,没有单一的方法能够对所有类型的数据输入都达到最优。 3. NFL 定理能否通过结合使用集成方法的算法来打破? 尽管集成方法通常能产生更好的泛化能力,但它们并不违反 NFL 定理。集成仍然依赖于底层模型的假设以及数据的属性。尽管它们能够减少偏差和方差,但如果数据与主要学习器的假设存在实质性差异,它们也无法奏效。 下一主题国防/军事中的机器学习应用 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
