机器学习中的信用评分预测2025年6月25日 | 阅读 10 分钟  在当今世界,信用评分对于贷款机构评估信用worthiness 至关重要,它们影响着从抵押贷款到租房的方方面面。随着大数据和机器学习的兴起,信用评分过程得到了革新,使其更加准确和高效。机器学习算法能够分析大量数据,并比传统的信用评分模型提供更准确的预测。本文将探讨使用机器学习进行信用评分预测,包括其好处和挑战。 信用评分及其重要性 信用评分是根据个人的信用历史、收入和其他财务因素对其信用worthiness 的数值表示。它是贷款机构和信用卡公司在决定是否批准贷款或提供信贷时的一个关键因素。信用评分的范围从 300 到 850,分数越高表示信用worthiness 越好。通常,良好的信用评分在 700 以上,而低于 600 的评分则被认为是差的。 机器学习在信用评分中的优势机器学习算法通过提供更准确的信用worthiness 预测,革新了信用评分。机器学习模型经过大量数据的训练,能够识别模式并比传统的信用评分模型做出更准确的预测。机器学习算法还可以考虑更广泛的数据,包括社交媒体等非传统数据源,以做出更准确的预测。 机器学习在信用评分中的主要优势之一是其减少偏见的能力。传统的信用评分模型通常存在基于种族或性别等因素的固有偏见。机器学习算法被设计为无偏的,因为它们基于数据进行训练,并且不包含任何先入为主的偏见。这使得信用评分决策更加公平。 与传统的信用评分模型相比,机器学习算法也更有效率。它们可以在几秒钟内分析大量数据,从而提供近乎即时的信用评分决策。这使得借贷流程对借款人和贷款人双方都更快、更高效。 机器学习在信用评分中的挑战虽然机器学习在信用评分方面具有许多优势,但也有需要考虑的挑战。
Python 实现现在我们将尝试在代码中实现它。 目的根据客户的月度客户画像,目标是估算他们未来无法偿还信用卡账单的可能性。通过跟踪最近信用卡账单之后的 18 个月的表现来派生二元目标变量,如果消费者在账单日期后的 120 天内未按时付款,则认为发生了违约事件。 关于数据数据集中包含每个客户在每个账单日期的汇总画像特征。在匿名化和标准化后,特征分为以下几大类:
以下特征是分类的
输出  训练数据集包含 5531451 行和 190 列。 输出 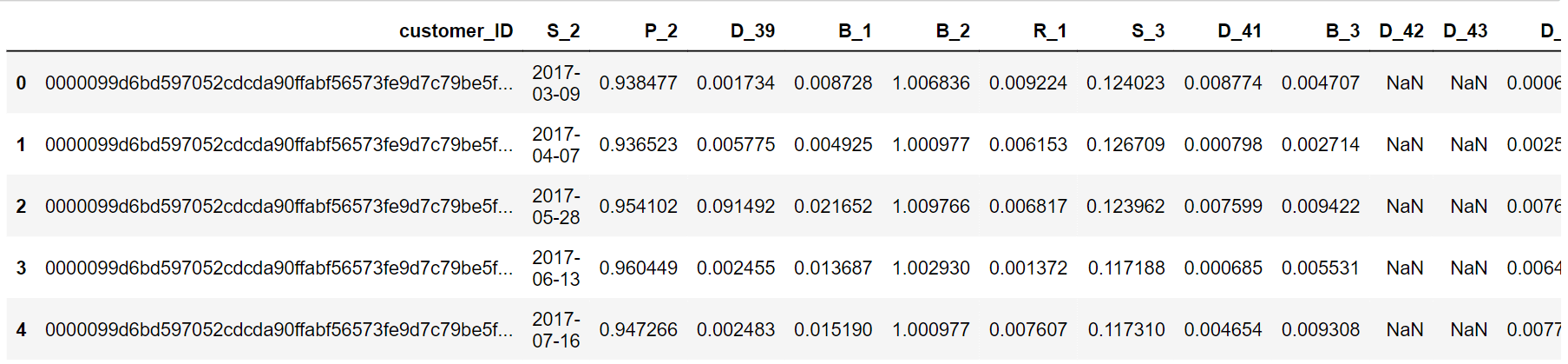
输出  此处,0 --> 非违约,1 --> 违约
输出  我们可以看到训练-测试数据中没有用户重叠。 输出  输出  时间线上也没有重叠。 输出   我们可以看到,从 10 月到 4 月,测试画像增加,而训练画像保持一致。 输出 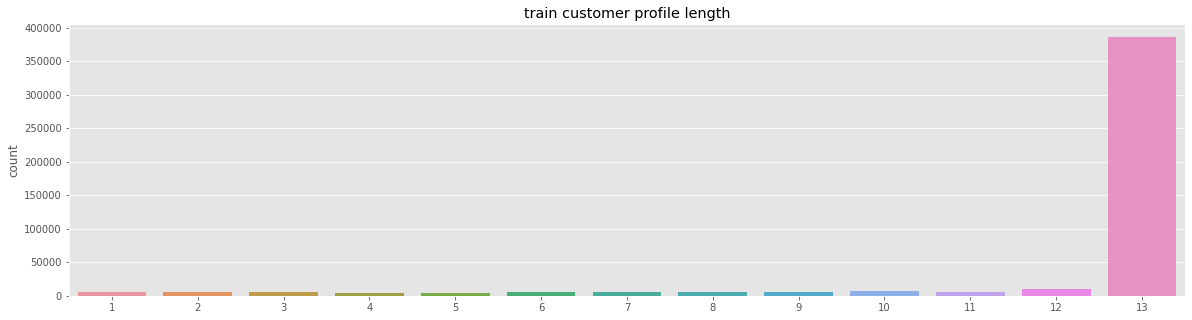  我们可以看到训练和测试画像长度的分布是相似的。
信息值是选择预测模型中的重要变量最有效的技术之一。它有助于根据变量的重要性进行排序。  如果 IV 统计量是
现在,为了选择特征,我们正在计算每个特征的 IV 值。 输出  输出  输出  我们可以观察到,排名前 75 的特征的 IV 值大于 0.5,因此这 75 个 IV 值最高的特征是强预测因子。 证据权重 (WOE)证据权重表明独立变量在多大程度上可以预测因变量。它经常被称为衡量好坏客户分离度的指标,因为它源自信用评分领域。错过贷款还款的客户被称为“坏客户”。“好客户”是指偿还了贷款的客户。 
计算 WOE 的步骤
对于一个特征,我们将尝试描述 woe 值和一个 woe 图。 输出 
输出 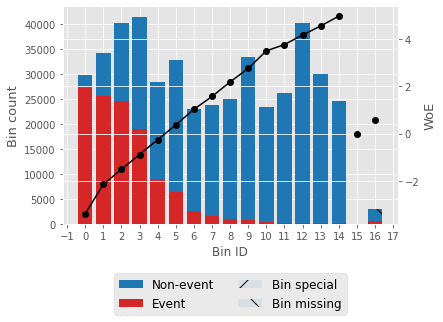
输出            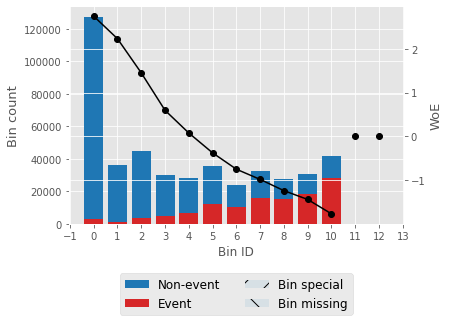 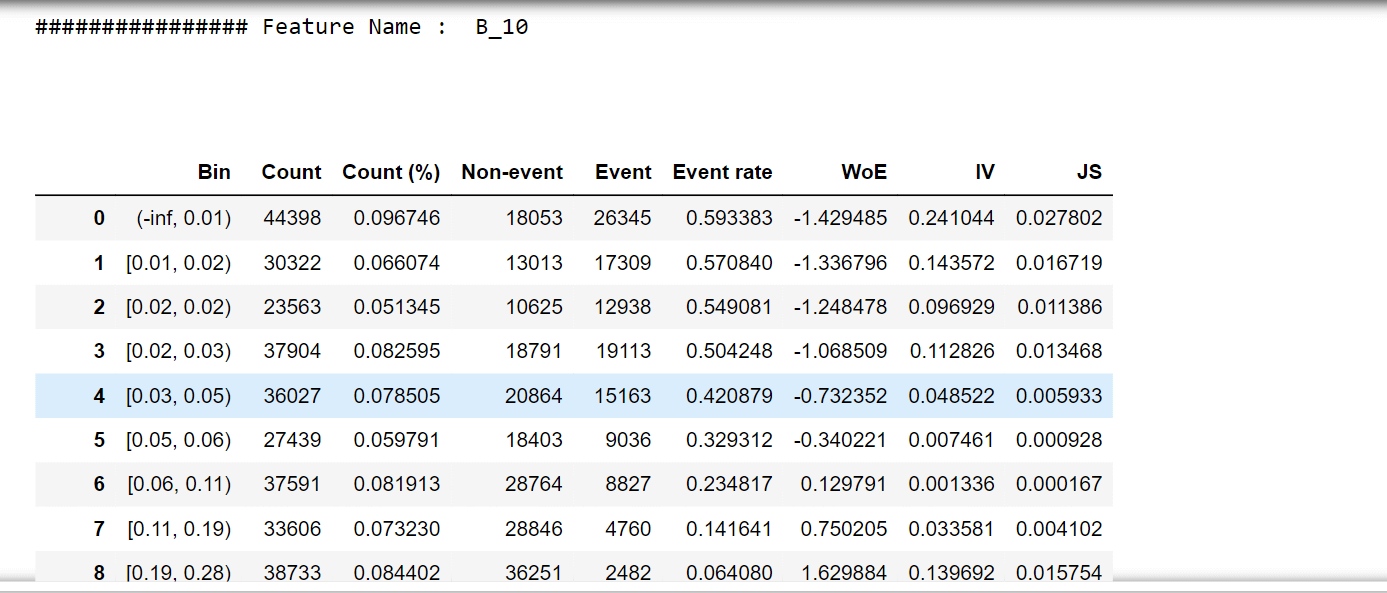     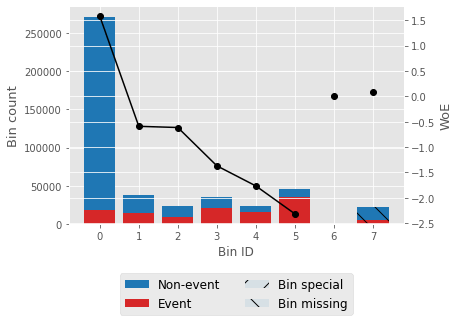 选择 IV 值大于 0.5 的特征。 相关性热力图输出  输出 
输出  输出  输出  输出 
输出  我们获得了 75% 的准确率。 输出   输出  输出  输出  我们获得了 87% 的准确率。 输出 
输出 
输出  我们可以看到很多分数卡在 650-750 的范围内。 输出  结论机器学习算法通过提供更准确、更高效的信用评分决策,革新了信用评分过程。它们能够分析海量数据并识别模式以做出更准确的预测。然而,也存在需要考虑的挑战,例如机器学习模型的复杂性以及对大量高质量数据的需求。隐私也是一个问题,贷款机构必须采取措施确保借款人的数据受到保护和安全。尽管存在这些挑战,机器学习在信用评分方面的优势是显而易见的,并且机器学习很可能在未来的信用评分中继续发挥越来越重要的作用。 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
