保险欺诈检测 - 机器学习2025年6月25日 | 阅读 10 分钟  保险公司面临着严重的保险欺诈问题,每年给它们造成数十亿美元的损失。保险欺诈可能以多种方式出现,包括捏造或夸大索赔。机器学习可以在这里用于检测保险欺诈。 机器学习算法可用于分析大量数据,以发现可能表明欺诈的趋势。这些实时数据处理方法使保险公司能够快速发现并阻止虚假索赔。 许多机器学习方法,包括决策树、随机森林、逻辑回归和神经网络,都可以用于检测保险欺诈。算法的选择将取决于应用程序的特定需求。这些算法各有优缺点。 机器学习在欺诈检测方面的优势以下是使用机器学习进行保险欺诈检测的一些好处:
数据不平衡是保险欺诈检测中的一个主要问题。由于欺诈性索赔相对于有效索赔的发生率较低,因此开发能够可靠识别欺诈的模型可能具有挑战性。可以通过过采样、欠采样和成本敏感学习等技术来平衡数据,以提高模型的性能,从而解决此问题。 Python 实现在这里,我们将看到可用于保险欺诈检测的各种模型及其准确性。
输出 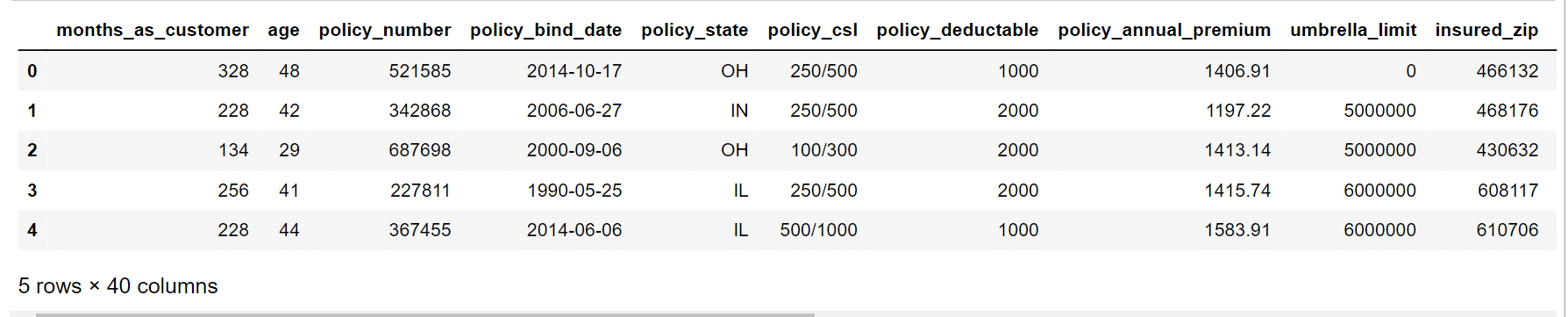 该数据集包含 40 列。 输出  输出  
数据预处理是机器学习的关键步骤,涉及数据清理、转换、编码、选择、集成和缩减,以准备用于训练机器学习模型。数据的质量以及数据的准备方式会对模型的准确性和性能产生重大影响。 在这里,我们将执行以下操作:
输出   我们的数据存在缺失值。
缺失值可能对机器学习模型造成问题,因为它们可能导致有偏见或不准确的结果。因此,可视化它们有助于理解缺失数据的范围和模式。 输出 
我们将把缺失值分配为 0 作为替代来处理缺失值。 输出   现在,我们的数据中没有缺失值。 输出  输出   输出  输出  从上图可以看出,年龄和客户月数之间存在高度相关性。我们将删除“年龄”列。此外,总索赔金额、伤害索赔、财产索赔和车辆索赔之间也存在高度相关性,因为总索赔是其他索赔的总和。因此,我们将删除总索赔列。 输出  输出  
它涉及将分类数据转换为机器学习模型可以处理的数值数据。 我们将把分类变量编码为数值数据,以便我们的模型更容易预测保险欺诈。 输出  输出  输出  输出  输出  输出  数据看起来不错。让我们检查一下异常值。
称为异常值的数据点与其他数据集中的数据点差异很大。异常值可能出现的原因有多种,包括测量错误、数据输入问题或固有数据变异性。统计分析和机器学习模型可能会受到异常值的影响,因为它们可能会提供有偏见的估计或不准确的预测。 我们将尝试查找数据中的异常值。 输出 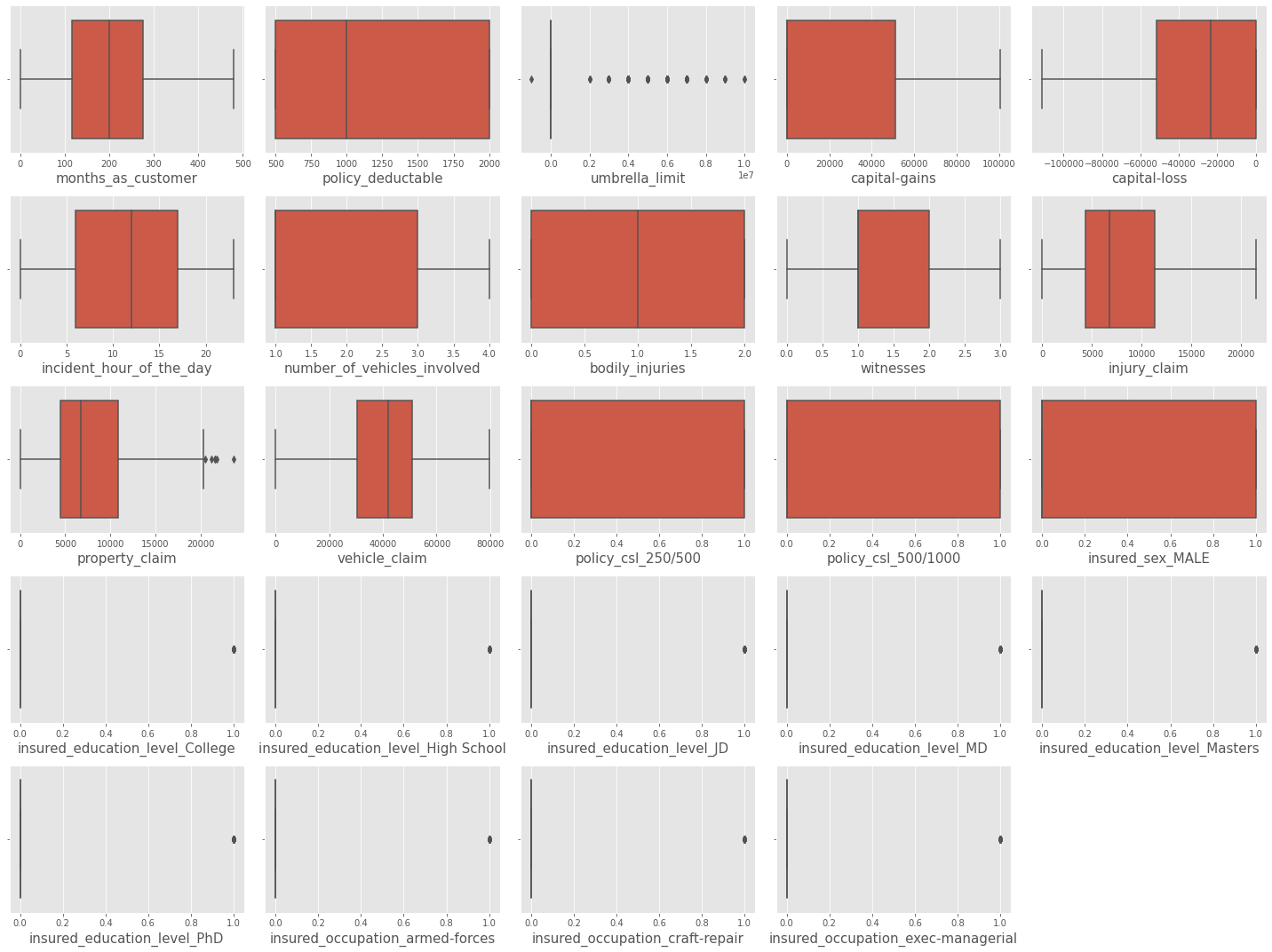 某些数值列存在异常值。稍后我们将对数值列进行缩放。 输出  输出  输出 
现在,我们将训练和测试以下模型:
我们还将检查模型的准确性。 1. SVM 输出  2. KNN 输出  3. 决策树分类器 输出  输出  输出  输出  4. 随机森林分类器 输出  5. Ada Boost 分类器 输出  输出  输出  6. 梯度提升分类器 输出  7. 随机梯度提升 (SGB) 输出  8. XGBoost 分类器 输出  输出  输出  9. Cat Boost 分类器 输出  输出  10. 极端随机树分类器 输出  11. LGBM 分类器 输出  12. 投票分类器 输出  输出  比较模型我们已经训练和测试了我们的模型,现在是时候进行比较了,以便我们能够找到最适合保险欺诈检测的模型。 输出  决策树分类器的性能最高,为 79%,而随机梯度提升 (SGB) 的性能最低,为 31%。 因此,我们可以说 DTC 是保险欺诈检测的最佳模型之一。
输出  结论保险欺诈是一个严重的问题,会对保险公司及其客户产生负面影响。通过定位数据中的模式和异常,可以使用机器学习算法来检测和阻止欺诈。为确保模型的准确性和效率,选择合适的方法并管理数据的不平衡性至关重要。 请记住,我们在选择模型时需要非常谨慎,因为它将对预测产生更大的影响。 下一个主题微分和积分微积分 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
