机器学习中的卷积类型2025年2月3日 | 阅读11分钟 从数学的角度来看,卷积是一个积分函数,它表示当一个函数 g 在另一个函数 f 上滑动时,f 和 g 的重叠程度。 直观地说,卷积就像一个搅拌机,通过组合函数来减少数据空间,同时保持信息。 在机器学习和神经网络方面,卷积通过使用可学习参数(以滤波器(矩阵/向量)的形式)从输入数据集中提取低维特征。 它们的一个特点是能够保持输入数据点之间的位置或空间关联。卷积神经网络在相邻层之间的神经元之间强制执行局部连接模式,从而利用空间局部相关性。 直观地说,卷积是通过将滑动窗口(一个具有可学习权重的滤波器)的思想应用于输入,并产生加权和(输入和权重的加权和)作为输出的过程。作为后续层输入的特征空间就是这个加权和。 人脸识别问题是其中的一个绝佳例子,前几层卷积层学习输入图像中重要区域的压力,然后学习边缘和轮廓,最后学习人脸。在这个例子中,输入空间被减小到一个低维空间(表示点和像素的信息),然后减小到包含形状和边缘的另一个维度,最后减小到对照片中的人脸进行分类。N 维允许使用卷积。 卷积的类型机器学习中有多种卷积类型,但我们主要可以将其分为四种类型。
实施现在我们将针对各自的问题来实现每种类型的卷积。 一维卷积 首先,我们将使用一维卷积来预测欺诈卡检测。 我们将导入所需的库。 然后我们需要读取数据集。 现在我们将数据集分割成训练集和测试集。 输出  现在,我们将定义我们的 1D 卷积网络。 现在我们需要准备我们的训练集,使其适合一维卷积。 再次,我们将准备我们的测试集,使其适合一维卷积。 显然,我们必须训练我们的模型。 输出  准确率似乎非常惊人!! 输出  准确率: 计算所有预测中正确的比例。高准确率(如 0.9992)表明模型在预测正确类标签方面做得非常好。 曲线下面积(AUC): ROC 曲线的 AUC 特别衡量模型区分正负类别的能力。AUC 为 0.902,尽管准确率看起来很高,但模型的区分能力被认为是中等。 二维卷积 现在我们将使用二维卷积来识别 MNIST 数据集中的数字。 首先,我们需要导入所需的库。 为了方便起见,我们生成随机数。 输出  我们获得了 42000 行和 785 列。 现在我们将数据集分割成训练集和测试集。 输出  现在将定义用于识别图像的二维卷积层。 输出  我们需要训练模型。 现在,我们只是将其进行测试。 输出  我们在测试集和验证集上获得了很高的准确率。 三维卷积 现在我们将为三维 MNIST 数据集使用三维卷积网络。首先,我们需要导入所需的库。 由于三维 MNIST 数据以 .h5 格式提供,让我们将整个数据集加载到测试集和训练集中。 现在我们来检查数据集的维度。 输出 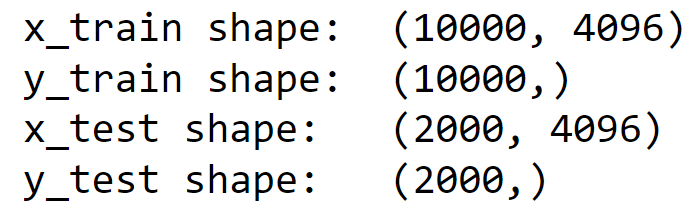 尽管此数据集是一维平坦的,但数据集的作者还在另一个数据文件中提供了原始的 x、y 和 z 数据。让我们绘制一个三维数字。为了正确查看此三维数字,我们将对其进行旋转。 输出   现在,让我们使用此数据集创建一个三维卷积神经网络。在使用二维卷积之前,我们首先将每个图像转换为三维形状——宽度、高度和通道。红色、绿色和蓝色层切片由通道表示。因此,它被配置为 3。类似地,我们将使用输入数据集的四维形状转换来启用长度、宽度、高度和通道(r/g/b)的三维卷积。 输出  三个输出层,维度为 16、16、16,一个输入层,维度为 10。应用四个卷积层,具有恒定的核大小 (3, 3, 3) 和递增的滤波器大小(典型大小:8、16、32、64)。 在第二个和第四个卷积层分别放置两个最大池化层。 现在,让我们编译并训练模型。 输出  我们可以看到验证集的准确率在模型训练过程中有所变化,这表明网络可以进一步改进。让我们预测并评估当前模型的准确率。 输出  输出  尽管模型目前不太准确,但通过架构修改和超参数调整,可以使其变得更好。 空洞卷积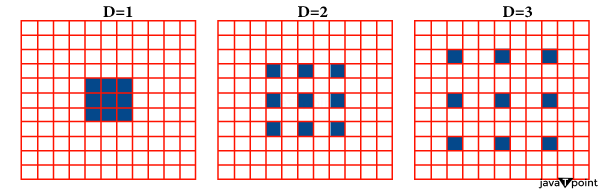 现在我们将尝试使用空洞卷积生成 CAM(分类激活图)。 首先,我们需要导入所需的库。 让我们获取数据集 我们现在创建我们的数据加载器。 现在我们将创建我们的空洞卷积网络。 输出  我们必须训练我们的模型。 输出  现在让我们生成一些 CAM 输出  下一个主题机器学习工具 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
