机器学习中的肝脏疾病预测2025年3月17日 | 阅读11分钟  肝脏疾病是一个重大的全球健康问题,影响着全球数百万人的健康。早期、准确地检测肝脏疾病对于有效治疗和预防进一步的并发症至关重要。近年来,机器学习已成为医疗保健领域的一个强大工具,能够开发出有助于诊断和预测包括肝脏疾病在内的各种疾病的预测模型。 机器学习在肝脏疾病预测中的应用机器学习算法在肝脏疾病预测领域有着广泛的应用。通过分析患者数据和病历,机器学习模型可以识别与肝脏疾病相关的模式和风险因素。一些主要应用包括:
使用机器学习进行肝脏疾病预测的好处将机器学习整合到肝脏疾病预测中带来了许多好处:
使用机器学习进行肝脏疾病预测的挑战尽管有许多优点,但在将机器学习应用于肝脏疾病预测方面仍存在一些挑战:
在这里,我们将尝试在代码中实现它。 数据摘要由于过度饮酒、吸入有害气体以及摄入受污染的食物、腌菜和药物,肝脏疾病患者的数量一直在不断增加。该数据集用于评估预测算法,以减轻医生的负担。 内容该数据集包含来自印度安得拉邦东北部收集的 416 名肝病患者和 167 名非肝病患者的记录。“Dataset”列是用于将组分为肝病患者(有肝病)或非肝病患者(无肝病)的类标签。该数据集包含 441 名男性患者和 142 名女性患者的记录。 任何年龄超过 89 岁的患者都被列为年龄“90”岁。 列
导入库输出  EDA输出  输出  名为“Albumin_and_Globulin_Ratio”的特征不完整,因为它缺少 583 个值。因此,我们需要在数据预处理阶段解决这个问题。现在,我们打算通过创建直方图来评估数据的平衡性。 输出  为了简化类标签,我们需要重新分配它们。对于没有肝脏疾病的患者,我们将分配标签 0,对于患有肝脏疾病的患者,我们将分配标签 1。 输出  此时,我将用零替换缺失值。 输出  输出 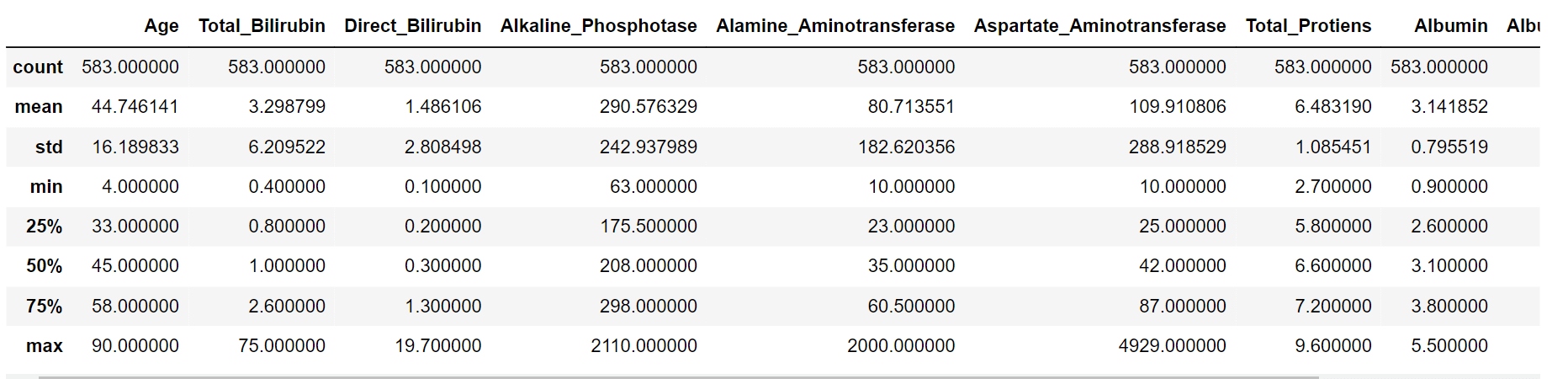 根据表中提供的信息,由于不同特征的范围不同,因此有必要进行特征缩放。 输出  现在,为了将分类数据编码为数值,我们使用了传统的 pandas 函数“get_dummies”。由于只有一个列需要编码,因此此函数足以完成此任务。 输出  为了检查特征之间的关系,使用“corr()”函数并生成热力图是一种有价值的方法。这允许对特征之间的相关性进行可视化表示。 输出  根据热力图分析,可以明显看出某些特征对之间存在很强的相关性。具体来说,“直接胆红素”和“总胆红素”、“丙氨酸氨基转移酶”和“天冬氨酸氨基转移酶”以及“总蛋白”和“白蛋白”之间存在高度相关性。 现在,我们将仅使用支持向量分类器 (SVC) 对不使用任何采样技术的数据库进行操作,以评估其性能。 输出 输出  输出  输出   根据混淆矩阵,我们观察到没有真阴性,这是算法的一个错误结果。这表明算法不平衡,并且持续预测患者患有肝脏疾病。我们需要调整模型。 输出  输出  根据 ROC 曲线和混淆矩阵的分析,很明显需要最小化假阳性数量,因为它们代表了错误的预测。为了优化模型,我们使用了 GridSearchCV 方法。 输出  输出  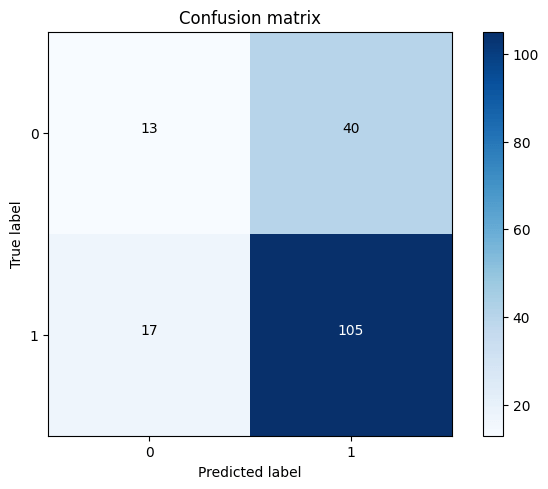 随着真阴性病例的包含,ROC 曲线有望显示出更好的性能。 输出  输出  与未优化的模型相比,ROC 曲线的 AUC 提高到 0.58。然而,这仍然不能算是一个高度有效的模型。这可能归因于数据集的不平衡性,这限制了 AUC 的改进。此外,数据集相对较小的规模也可能导致模型性能的局限性。 我将应用过采样技术来平衡数据集并增加数据量。 输出  输出  输出   召回率指标显示值较低,表明需要优化模型以获得改进。 输出 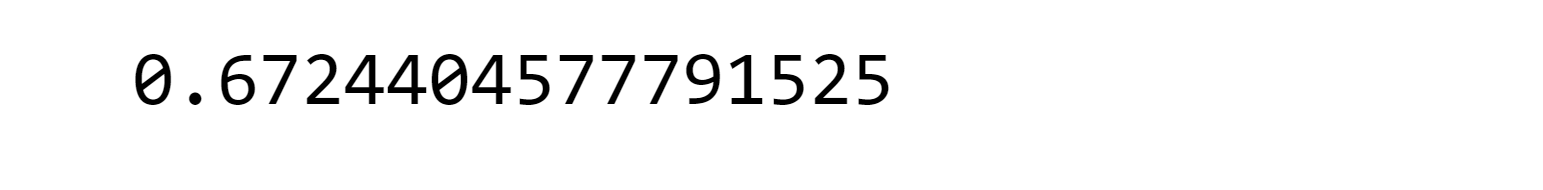 输出  输出  输出   输出  输出  尽管采用了 SMOTE 技术,SVC 的性能仍然不令人满意。召回率指标和 AUC 分数都约为 0.67,未能达到期望水平。因此,我们决定探索 RandomForestClassifier 作为替代方法。 输出  输出   使用 RandomForestClassifier 后,召回率指标相比 SVC 有所提高。然而,模型仍需要进一步调整以优化其性能。 输出  输出  输出  输出   输出  输出  在应用 GridSearchCV 优化 RandomForestClassifier 后,该模型在 ROC 曲线上的召回率指标为 0.76,AUC 为 0.69。 使用机器学习进行肝脏疾病预测的未来方面随着机器学习的不断发展,一些未来的方面有望为肝脏疾病预测带来希望:
结论机器学习已成为肝脏疾病预测的宝贵工具,在准确性、早期检测和个性化医疗方面提供了显著的优势。然而,数据可用性、模型可解释性和伦理考量等挑战需要解决。未来,机器学习技术有望取得进一步的进展,从而实现更准确、更有效的肝脏疾病预测。通过利用机器学习的力量,我们可以改善患者的治疗效果,并在与全球肝脏疾病的斗争中取得重大进展。 下一个主题机器学习中的多数投票算法 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
