贪婪层向预训练2025年3月17日 | 阅读 8 分钟 人工智能得益于神经网络的发展,取得了革命性的进步,在语音识别、计算机视觉和自然语言处理等众多领域取得了显著的进展。然而,深度神经网络的训练可能很困难,特别是在处理大型、复杂的数据集时。贪婪层级预训练是一种解决这些问题的方法,它通过逐层初始化深度神经网络的参数。 贪婪层级预训练用于逐层初始化深度神经网络的参数,从第一层开始,然后依次处理后续的每一层。在每一步,一层都被训练成好像它是一个独立的模型,使用前一层的输入和后一层的输出。通常,训练的目标是开发出可用的输入数据表示。 贪婪层级预训练的过程贪婪层级预训练过程可以分阶段进行如下
贪婪层级预训练的优势以下是贪婪层级预训练的一些优势
贪婪层级预训练的缺点贪婪层级预训练具有各种优点,但也存在一些局限性。以下是贪婪层级预训练的一些缺点
代码 我们将实现三个层的自编码器,然后是一个分类任务,这个模型使用了两个预训练的自编码器层,后面跟着一个连接到 softmax 的密集层。我们将能够演示贪婪层级预训练。 导入库输出  缩放将输入缩放到 0 到 1 之间。这使得解码模型变得简单,因为我们可以将其视为二元输出。 输出  现在我们将使用自编码器实现层级预训练模型。 我们现在将配置三个具有特定参数的 SGD 优化器,并通过一系列连续降低学习率的操作,我们将说明学习率衰减计划的影响。 输出  堆叠的自编码器必须逐层训练,每一层依次被教授,其编码表示馈送到下一层。通过使用这种方法,模型能够逐渐学习输入数据的更抽象表示。 输出  输出  输出  我们必须确保在训练单个自编码器期间学习到的权重被转移到深度自编码器和非深度自编码器的相应层,这使得它们能够有效地执行编码和解码任务。 现在我们将比较原始图像与其重建图像,您可以评估自编码器模型在捕获和重现输入数据方面的性能。逐个取消注释每一行,您可以比较不同自编码器架构的重建质量。 输出  微调后输出  输出  输出 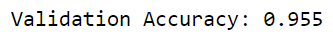 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
