机器学习中的 Transformer2025年8月13日 | 阅读 4 分钟 Transformer 是一种用于解决自然语言处理(NLP)任务的序列到序列神经网络模型。Transformer 由 Vaswani 在论文“Attention is All You Need”中提出。在本文中,我们将学习机器学习中的 Transformer、其工作原理和应用。 为什么我们需要 Transformer 模型?Transformer 模型使用自注意力机制,将整个文本转换为单个文本。它克服了各种模型的挑战,例如“循环神经网络(RNN)”和“长短期记忆(LSTM)”。传统的序列模型(如 RNN)存在梯度消失问题,导致长期记忆丢失。RNN 顺序处理句子,一次分析一个文本。 一方面,增加 LSTM 中的记忆单元数量有助于解决梯度消失问题,但它仍然一次处理一个文本。这种顺序文本的处理意味着 LSMT 无法分析整个句子。 传统模型面临上下文依赖问题,而 Transformer 模型则利用其自注意力方法并行处理整个文本并解决这些问题,从而使其在上下文理解方面非常有效。 Transformer 模型架构Transformer 的架构包含组件:自注意力机制、位置编码、多头注意力、位置前馈网络和解码器架构。下面是详细讨论。 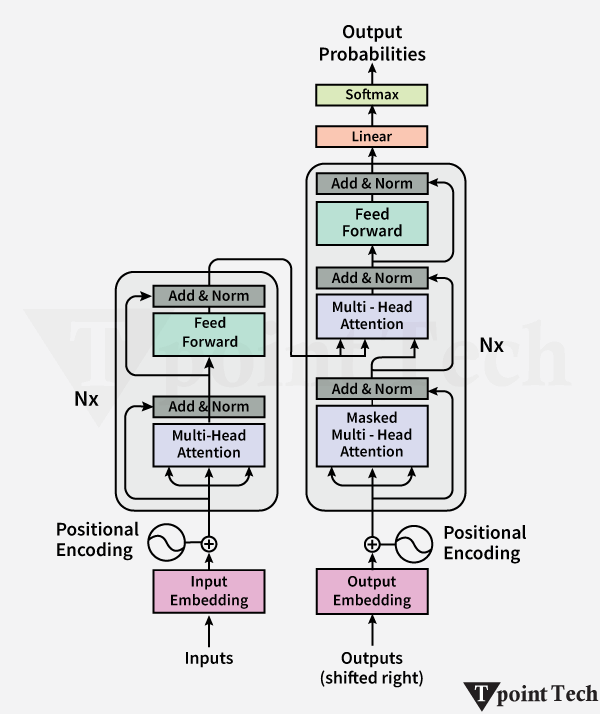 1. 自注意力机制Transformer 的自注意力机制使其能够找出文本中哪个词对其他词最重要。这是通过缩放点积来评估的。注意力机制着眼于输入序列,并在单个阶段选择序列中的哪些其他部分很重要。 文本中的一个单独的词由三个向量表征。
注意力分数通过以下方法进行评估 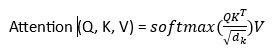 这些评估应该对其他文本给予多少注意力。 2. 位置编码与 RNN 相比,Transformer 由于文本的并行处理,在理解词语顺序方面存在固有挑战。为了解决这个问题,使用了位置编码,它添加了 token 嵌入,并提供了关于序列中每个 token 位置的信息。它提供了每个 token 的相对位置。 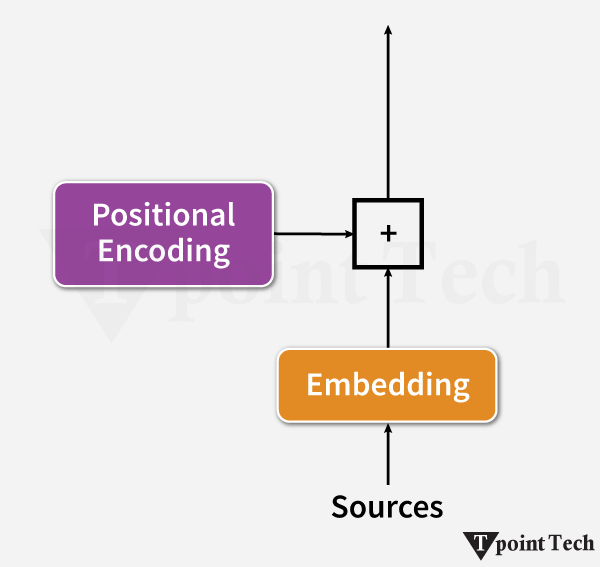 位置编码使用以下方法进行评估 当 i 为偶数时 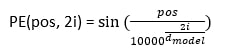 当 i 为奇数时 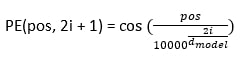 3. 多头注意力Transformer 使用多头注意力机制而不是单个注意力机制,它并行处理序列。每个头从数据中提取不同的模式,从而增强模型的理解。 4. 位置前馈网络前馈网络包含两个具有 ReLU 激活函数的线性变换函数。它独立地应用于序列中的每个位置。数学上,它描述为 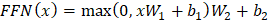 这有助于改进每个位置的编码表示。 5. 编码器-解码器架构编码器-解码器架构是 Transformer 模型的基本模块。Transformer 的编码器部分将输入序列处理成一个向量;另一方面,解码器将该向量转换为序列。编码器和解码器的单个层包含自注意力机制和前馈层。在解码器中,集成了编码器-解码器注意力层,该层专注于相关的输入部分。 考虑一个西班牙语句子:“Soy redactor de contenido。”翻译成英文是“I am a content writer”。 编码器方法包含多个层(通常是 6 层)。每层有两个重要组成部分。
解码器方法也包含 6 层,但增加了编码器-解码器注意力方法。这使得解码器在产生输出时能够专注于输入文本的重要部分。 举例说明:“The cat didn't chase the mouse because it was not hungry.”(猫没有追老鼠,因为它不饿。)这个词“it”指的是“cat”。自注意力机制有助于模型正确地将“it”与“cat”关联起来,以确保准确理解句子的结构。 Transformer 的应用以下是一些 Transformer 的应用:
|
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
