反向传播 - 算法2025年3月17日 | 阅读11分钟 反向传播是训练人工神经网络的一个至关重要的算法,它使得神经网络能够学习数据中复杂的模式和关系。该系统首先进行前向传播,输入数据通过网络,在每一层经历加权求和和激活函数。然后将计算出的输出与实际目标值进行比较,生成一个量化差异的损失。在随后的反向传播过程中,利用微积分链式法则计算损失函数对网络权重和偏差的梯度。这些梯度指导着在梯度相反方向上调整权重和偏差,以最小化损失。通过使用优化算法(通常是梯度下降),模型会迭代地优化其参数。这种前向传播和反向传播的迭代循环一直持续到网络收敛到可以根据给定输入集预测输出的状态。反向传播是神经网络训练的基础,它使它们能够从训练数据中泛化模式,从而对新的、未见过的数据进行预测。 神经网络,就像所有其他监督学习算法一样,通过使用作为训练数据提供的(输入,输出)对集合来学习将输入映射到输出。特别是,神经网络通过对输入应用一系列变换来执行这种映射。神经网络由多个层组成,每一层都由单元(也称为神经元)组成,如下所示:  在上图中,输入首先通过第一个隐藏层进行转换,然后是第二个隐藏层,最后才预测输出。每次转换都由一组权重(和偏差)指导。为了学习东西,网络必须在训练过程中修改这些权重,以最小化预测输出与它从输入映射出的输出之间的误差(也称为损失函数)。使用梯度下降优化技术,权重在每次迭代中按如下方式调整:
如上所示,损失函数关于权重的梯度在每次迭代中从权重中减去。这就是所谓的梯度下降。梯度 损失函数最小化任务最终与上述梯度的评估相关联。为了进行此评估,我们将分析三个提案:
为了简化我们的理解,我们将假设网络的每一层由一个单元组成,并且只有一个隐藏层。网络现在看起来像这样:  让我们来谈谈输入是如何被转换以创建隐藏层表示的。在神经网络中,通过执行前面一层两个操作来创建一层:
因此,在我们的场景中,有一个输入层、一个隐藏层和一个输出层,所有这些都由一个单元组成,并命名为 x、h 和 y,我们可以写出:
现在,我们可以通过应用一系列变换来确定输出 y 相对于输入 x 的值。这被称为前向传播,因为计算沿着网络向前移动。 接下来,我们需要将预测结果与实际结果 (yT) 进行比较。如前所述,我们使用损失函数来评估网络在预测时犯的错误。在本节中,我们将使用平方误差作为损失函数,如下所示: 如前所述,权重(和偏差)必须根据该损失函数 L 相对于这些权重(和偏差)的梯度进行更新。这里的问题是评估这些梯度。第一个选项是手动推导它们。 解析微分尽管这种方法费时且容易出错,但为了更好地理解问题,值得进行研究。由于只有一个隐藏层和一个单元,我们在这里大大简化了问题。然而,解析推导需要非常小心。  我们已经计算了相对于 w_2 的梯度,而计算相对于 w_1 的梯度将更加困难。因此,这种解析技术很难应用于复杂网络。此外,这种技术在计算上会相当浪费,因为我们无法利用梯度具有通用定义的事实,我们很快就会证明这一点。为了获得这些梯度,数值近似将是一个更简单的选择。 数值微分为了简单起见,我们可以通过以下方法确定梯度:  如前所述,虽然比解析推导简单,但这种数值微分的精度也较低。此外,为了评估每个梯度,我们必须至少计算一次损失函数。一个拥有 100 万个权重参数的神经网络将需要 100 万次前向传播,这显然效率低下。现在让我们探索反向传播策略,以找到一个更好的解决方案,这也是本文的重点。 反向传播在深入研究反向传播之前,让我们先描述一下导致损失函数评估的计算图。  此图中的节点表示为计算损失 L 而获得的所有值。如果一个变量是通过对另一个变量执行操作而计算出来的,则在两个变量节点之间形成一条边。查看此图并应用微积分链式法则,我们可以将 L 相对于权重(或偏差)的梯度描述为:  这里一个非常重要的事情是,梯度  方程右侧的前四项与 如上面的方程所示,我们从计算图的末端开始计算梯度,然后向后工作,以获得损失相对于权重(或偏差)的梯度。由于其反向评估,该算法被称为反向传播。下图说明了反向传播算法:  实际上,现在一次梯度下降迭代只需要一次前向传播和一次反向传播就可以计算从输出节点开始的所有偏导数。因此,它比早期技术效率高得多。在 1986 年发表的第一篇关于反向传播的文章中,作者(包括 Geoffrey Hinton)使用反向传播来使内部隐藏单元学习领域属性。 现在,为了更好地理解,我们将使用 MNIST 数据集来实现反向传播。 代码 导入库读取数据集分析数据我们将可视化某个索引点的数据,并通过更改索引来查看其他元素。创建一个图表来显示数据集中特定元素出现的频率。 输出  输出  输出  输出  激活函数激活函数是人工神经网络的重要组成部分,用于引入非线性,使其能够学习复杂的模式。两个常用的激活函数是 ReLU(整流线性单元)和 Softmax。
激活函数的导数激活函数的导数在反向传播算法中至关重要,尤其是在反向传播过程中,用于计算梯度并更新神经网络的权重。
前向传播前向传播用于确定特定节点的激活输出。`linear_forward` 函数用于确定 Z 值(z=wa+b)。然后将其通过激活函数(g(z))进行处理,以获得激活后的输出或下一层的输入。N 个隐藏层使用 ReLU,而输出层使用 Softmax 来提供十个类别的输出(0-9)。 成本计算值(也称为损失或目标函数)是神经网络的预测输出与实际目标值(地面实况)之间的差异度量。在使用 Softmax 激活函数作为输出层时,用于分类的成本函数通常是分类交叉熵。 反向传播现在我们将更新参数。 定义架构定义 `layers_dim` 来指定所需的神经网络设计。第一个元素是输入层,像素值为 28*28=784。最后一个部分是十类输出层(0 到 9)。其他元素包括具有指定节点数的隐藏层。(例如,第一个隐藏层包含 500 个节点,第二个隐藏层有 400 个节点,依此类推)。 输出  正如我们所见,随着迭代次数的增加,成本有所降低。这表明它工作良好。理解激活函数的操作知识,以及前向传播和后向传播,将为用户提供更大的灵活性和对该概念的理解。它提供了对网络的更深入的洞察。 下一个主题VGGNet-16 架构 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India

 ,其中 L 是损失函数,ϵ 是学习率。
,其中 L 是损失函数,ϵ 是学习率。 衡量了权重对损失的贡献。因此,梯度越大(绝对值),权重在每次梯度下降循环中的修改就越多。
衡量了权重对损失的贡献。因此,梯度越大(绝对值),权重在每次梯度下降循环中的修改就越多。
 。因此,一层的值 y 可以表示为 y=σ(z)=σ(xw+b),其中 x、w 和 b 的定义如上。
。因此,一层的值 y 可以表示为 y=σ(z)=σ(xw+b),其中 x、w 和 b 的定义如上。
 的评估可以重用梯度
的评估可以重用梯度 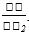 评估期间进行的一些计算。如果我们评估梯度
评估期间进行的一些计算。如果我们评估梯度