机器学习中的学生辍学预测2025年3月17日 | 阅读 12 分钟  在现代教育领域,学生辍学问题是一个严峻的挑战,影响着个人和教育机构。高辍学率的后果不仅仅局限于学业成就,还会延伸到未来的职业前景和整体福祉。然而,在早期阶段检测和解决这个问题可以显著减轻其负面影响。机器学习,作为人工智能领域的一项创新技术,应运而生。机器学习算法通过利用海量数据和先进的分析技术,能够准确预测学生辍学。通过检查各种因素和复杂模式,这些模型可以识别更容易辍学的学生。本文深入探讨了机器学习在预测学生辍学方面的应用,强调了其为教育部门带来的优势、挑战和潜在影响。 要理解学生辍学的复杂局面,必须认识到导致这一现象的众多因素。学生辍学是一个多层面的事件,受到个人、社会和制度等多种因素的影响。学业困难、参与度低、社会经济限制、家庭环境和支持不足是导致辍学的常见催化剂。通过深入了解这些根本原因,教育工作者和政策制定者可以制定有针对性的干预措施和全面的战略来应对辍学挑战。在此背景下,机器学习成为一个宝贵的盟友,为解决学生辍学问题提供了独特的见解和创新的方法。 最先进的机器学习算法能够剖析海量且异构的数据集,从而能够识别复杂的模式并做出可靠的预测。在预测学生辍学方面,这些机器学习模型可以有效地利用各种数据点。人口统计信息、学业成就、出勤记录、参与度水平、社会经济指标以及一系列相关因素都发挥着作用。通过对这些丰富的数据集进行仔细分析,机器学习算法有可能揭示人类分析师可能忽略的隐藏模式和相互依赖关系。通过利用历史数据,这些算法可以学会准确评估学生辍学的可能性,利用学生的独特特征和个人情况作为其预测的关键输入。 预测学生辍学的好处在教育机构、政策制定者和学生本身方面,利用机器学习预测学生辍学带来了许多优势。首先,早期识别有辍学风险的学生可以及时采取干预措施并建立支持系统。教育工作者可以提供个性化帮助,提供补充资源,并实施有针对性的措施,以提高学生成功的可能性。这种积极主动的方法可以显著降低辍学率并提高学生留存率。 其次,预测能力有助于机构资源的有效分配。通过 pinpoint 学生辍学倾向,教育机构可以集中精力,将资源用于为这些学生提供必要支持。这种有针对性的方法可确保干预措施能够精确地应用于最能产生影响的地方,从而优化资源利用。 此外,将机器学习纳入辍学预测有助于制定基于证据的政策和战略。通过审查导致辍学的根本原因,政策制定者可以制定解决核心问题的干预措施,并营造一个更具支持性且有利于学习的环境。这种数据驱动的方法能够做出明智的决策,并有助于制定旨在提高学生成绩的有效政策。 使用机器学习预测学生辍学的挑战虽然利用机器学习预测学生辍学显示出巨大的潜力,但必须认识并解决相关的挑战和道德影响。一个关键的挑战围绕着数据的可访问性和质量。构建准确的预测模型需要充分可靠的数据。教育机构必须建立健全的数据收集、存储和隐私协议,以维护学生信息的机密性和完整性。 另一个障碍是机器学习模型中潜在的偏差。如果用于开发模型的训练数据存在偏差或不完整,预测可能会变得有偏差或不公平。解决偏差需要有意识地努力在多样化和代表性的数据集上训练模型,以促进可靠和公正的预测。 在部署机器学习来预测学生辍学时,道德考量起着至关重要的作用。预测模型的负责任使用应优先考虑学生隐私、同意和透明度。应告知学生数据收集的目的以及将如何用于预测辍学。此外,必须建立机制来解决有关隐私和数据保护的担忧,确保负责任和可问责的方法来保障学生权利。 关于数据集该数据集提供了在高等教育机构提供的各种本科课程注册学生情况的全面视图。它包括人口统计数据、社会经济因素和学业成绩信息,可用于分析学生辍学和学业成功的可能预测因素。该数据集包含多个不相关的数据库,其中包含入学时可用的相关信息,例如申请模式、婚姻状况、选择的课程等。此外,此数据还可以通过评估每学期学分的/注册的/评估的/通过的课程单位及其各自的成绩来估算学生在每学期末的总体学业成绩。最后,我们还提供了该地区的失业率、通货膨胀率和国内生产总值,这有助于我们进一步了解经济因素如何影响学生辍学率或学业成功结果。这个强大的分析工具将为激励学生继续学业或放弃学业提供宝贵的见解,涉及农学、设计、教育、护理、新闻学、管理、社会服务或技术等广泛学科。 列
现在我们将在代码中实现它。我们将尝试找到最佳准确率的模型来预测学生辍学率。 代码 导入库读取数据集了解数据集输出  输出  输出  输出  输出   看起来没有缺失值或重复值,但我们仍然可以检查并按需处理。 输出   输出  只有目标列是非数字的,我们可以将其转换为数字。目标列是输出列,因此我们需要以数字形式表示它,以便找到它与其他列的相关性。 输出  所以目标列中有 3 个唯一值,我们可以将其替换为
输出 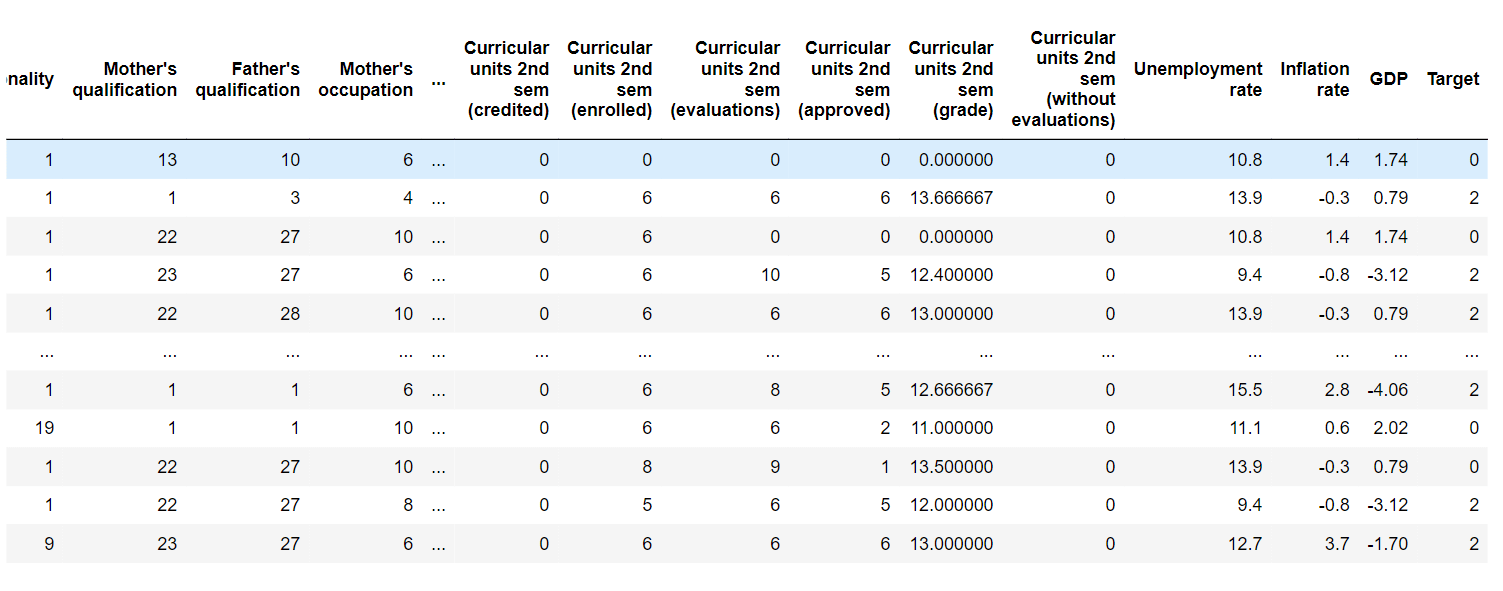 输出   输出  最后,找到目标与所有其他数值列的相关性。 输出   输出  这是考虑了相关输入和输出列的新 DataFrame。 输出  输出  输出  EDA(探索性数据分析)在我们对学生辍学数据集的探索中,我们将进行一个名为探索性数据分析(EDA)的过程。您可以将其视为我们了解和更好地认识数据的方式。这就像剥洋葱一样,揭示其真实本质。通过使用不同的工具和技术,我们将仔细检查数据集,寻找有趣的模式和见解。EDA 帮助我们了解学生辍学背后的因素,并使我们能够做出明智的决定来解决这个问题。 输出  输出  输出  输出  让我们绘制“课程单位第一学期(成绩)”列与“课程单位第一学期(成绩)”的图,并按颜色区分目标。 输出  输出  输出  输出  输出  提取输入和输出列 输出  将数据集拆分为训练集和测试集输出  建模建模是预测分析过程中的关键步骤。它涉及训练和测试各种机器学习模型,以确定其在预测学生辍学方面的准确性和性能。在此阶段,将不同的算法应用于数据集,每种算法都有其优点和缺点。 在这里,我们将训练各种模型,然后查看它们的准确性。 逻辑回归 输出  随机梯度分类器输出  感知器输出  逻辑回归 CV输出  决策树分类器输出  随机森林分类器输出  支持向量机输出  NuSVC输出  线性 SVC输出  朴素贝叶斯输出  输出  输出  输出  输出  在评估和比较了用于预测学生辍学的多个机器学习模型之后,随机森林模型成为表现最佳的模型,其准确率为 76.94%,交叉验证准确率为 77.08%,因为随机森林算法以其处理复杂数据集和捕捉变量之间复杂关系的能力而闻名。 模型选择选择准确率最高的模型。因此,我们选择随机森林,准确率为 76.94% 和 77.08%(带交叉验证)。 输出  我们将使用 GridSearchCV 对随机森林分类器模型进行超参数调优。 输出  在这里,模型的准确率有所提高。 输出 
综合以上所有观点,随机森林分类器可用作预测学生辍学的模型。 结论总之,机器学习在预测学生辍学方面的应用为教育机构提供了变革性的机会,能够有效地应对这一普遍问题。通过利用机器学习算法的能力,教育工作者、政策制定者和机构可以采取积极措施,提供有针对性的支持,并营造有利于学生成功的环境。尽管如此,为了确保这些预测模型的负责任和公平使用,务必应对数据质量、偏差和道德考量方面的挑战。随着机器学习和数据分析的不断发展,我们有潜力在减少学生辍学、提高教育成果以及培养包容和支持性的教育体系方面取得重大进展,该体系能够满足所有学生的需求。 下一个主题使用机器学习进行图像处理 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
