机器学习中的交通预测2025年6月24日 | 阅读 12 分钟  交通预测一直是交通规划者和城市管理者面临的挑战。随着城市的发展和道路上车辆数量的不断增加,对准确可靠的交通预测的需求变得越来越迫切。近年来,机器学习在解决这一问题方面展现出了巨大的潜力。 交通预测涉及估算特定区域未来的交通行为。这些信息可用于多种目的,包括减少拥堵、优化交通系统和提高道路安全。过去,交通预测一直基于传统的模型,如基于规则的模型和时间序列分析。然而,这些方法在捕捉交通模式的复杂性和可变性方面往往受到限制。 另一方面,机器学习非常适合处理大型复杂数据集,使其成为交通预测的理想工具。机器学习算法可以自动识别交通数据中的模式和关系,并利用这些来预测未来的交通状况。 有几种类型的机器学习算法可用于交通预测,包括回归、时间序列分析和人工神经网络。回归模型利用历史交通数据,根据过去的趋势预测未来的交通状况。时间序列分析模型会考察交通数据随时间变化的模式,并利用这些模式进行预测。人工神经网络,其结构模仿人脑,也常用于交通预测。 机器学习在交通预测中的一个关键优势是它能够处理大型复杂数据集。例如,交通数据可能包含有关交通流量、车辆速度和交通密度信息,以及天气状况、道路状况和一天中的时间等其他因素。机器学习算法可以处理这些数据,并识别影响交通模式的最重要因素,使其成为交通预测的理想选择。 机器学习在交通预测中的另一个优势是它能够适应不断变化的情况。传统的交通预测方法在处理交通模式变化方面往往受到限制,但机器学习算法可以自动适应这些变化并继续进行准确的预测。 除了这些优势之外,机器学习还可以通过整合其他数据源,如车辆的 GPS 数据、交通摄像头和社会媒体,来提高交通预测的准确性。例如,来自车辆的 GPS 数据可以提供实时的交通状况信息,而交通摄像头可以提供详细的交通流量和密度信息。社交媒体数据,例如关于交通状况的推文,也可以用来帮助提高交通预测的准确性。 虽然机器学习在交通预测方面具有许多优势,但并非没有挑战。最大的挑战之一是用于训练机器学习算法的数据质量。 例如,交通数据可能不完整或不准确,这会影响预测的准确性。此外,机器学习算法需要大量数据才能有效,而在某些情况下,这可能难以获得。 另一个挑战是用于交通预测的算法的复杂性。机器学习算法可能难以理解和解释,从而难以识别驱动预测的因素。这使得修改算法或提高其准确性变得困难。 现在我们将探讨四个路口的交通数据集,并构建一个模型来预测它们的交通状况。通过更好地理解交通模式,这可以帮助解决交通拥堵问题,进而有助于建设消除该问题的基础设施。 代码实现导入库加载数据集 输出  关于数据 该数据集是四个路口每小时汽车计数汇编。CSV 文件中有四个特征
交通数据来自多个时间段,因为这些路口上的传感器在不同时间收集数据。其中一些路口的数据稀少或受限。 数据探索
输出  输出 Text(0.5, 0, '日期')  上图中的显著细节
特征工程在此阶段,我们正在使用 DateTime 来构建一些附加功能。即
输出  探索性数据分析现在将绘制新形成的功能。 输出   上述图表得出了以下结论
输出 Text(0.5, 0, '日期')  计数图显示,2015 年至 2016 年期间,汽车数量有所增加。但是,由于我们只有 2017 年到第七个月的数据,因此无法就 2017 年得出相同的结论。 输出  毫无疑问,现有的特征具有最大的关联性。 将使用配对图来总结我们的 EDA。任何数据都以一种有趣的整体方式表示。 输出  本次 EDA 后我们得出的结论
出于上述原因,我们认为路口应进行修改以适应每个路口的特定需求。 数据转换和预处理在此步骤中,我们将按以下顺序进行
输出  输出  如果时间序列缺乏模式或季节性,则称其为平稳序列。尽管如此,我们在 EDA 中观察到了每周的周期性和随时间增加的趋势。从上面的图表可以再次清楚地看出,路口一和二呈上升趋势。如果我们限制时间跨度,我们将能更清楚地看到每周的季节性。此时,我们将跳过该步骤,继续进行适当的数据集转换。 转换步骤
根据上述观察,应使用以下差分过程来去除季节性
转换后的数据框图输出  上述图表似乎是线性的。将运行 Augmented Dickey-Fuller 检验以确保它们是平稳的。 输出  准备神经网络数据
模型构建我们已决定在项目中使用门控循环单元 (GRU)。在此部分,我们将创建一个函数,神经网络可以使用该函数来访问和拟合所有四个路口的数据框。 拟合模型现在,我们将拟合修改后的四个联合训练集到构建的模型中,并将其与修改后的测试集进行对比。 拟合第一个路口时的预测与测试集图 输出  输出 均方根误差为 0.245881146563882。  拟合第二个路口时的预测与测试集图 输出  输出 均方根误差为 0.5585970393765944。 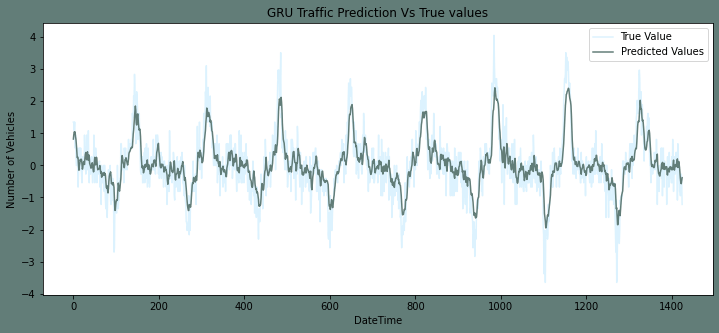 拟合第三个路口时的预测与测试集图 输出  输出 均方根误差为 0.6061366783632264。  拟合第四个路口时的预测与测试集图输出  输出 均方根误差为 1.0241982484501175。  模型结果输出 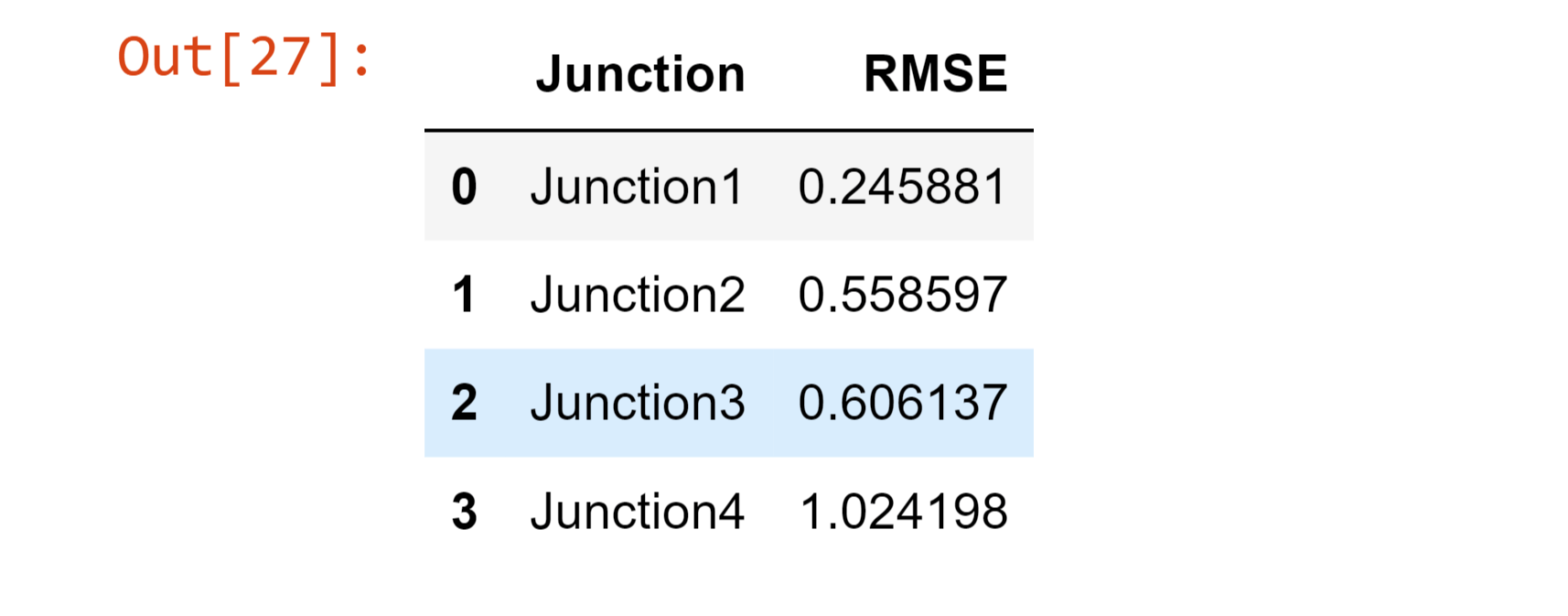 注意:均方根误差是一个非常任意的性能指标。因此,我们还在本项目中包含了结果图。数据反转换在此部分,我们将撤销我们用于去除数据集的季节性和趋势的转换。通过执行此过程,预测将恢复到之前的准确性水平。 第一个路口的逆变换 输出  第二个路口的逆变换 输出  第三个路口的逆变换 输出  第四个路口的逆变换 输出  数据集总结在此,我们训练了一个GRU 神经网络来预测四个路口的交通状况。为了创建平稳的时间序列,我们使用了归一化和差分转换。由于路口在趋势和季节性方面各不相同,我们为每个路口使用了不同的策略来使其平稳。我们将均方根误差作为模型的评估指标。此外,我们将预测结果与初始测试结果并列显示。从数据分析中得出了结论。 与路口二和三相比,路口一的汽车数量增长更快。路口四的数据非常少。因此,我们无法从中得出任何结论。 路口一的交通具有更强的每周季节性和每小时季节性。相比之下,其他路口则具有明显的线性特征。 结论总之,使用机器学习进行交通预测是解决城市交通拥堵问题的有效解决方案。随着海量交通数据的可用性,机器学习算法可以实时准确地预测交通流量和拥堵模式。这些预测可用于优化交通流量并提高运输系统的整体效率。虽然使用机器学习进行交通预测存在一些挑战,但潜在的好处是巨大的,可以带来改进的交通系统和减少经济损失。 下一主题一对一多类别分类器 |
我们请求您订阅我们的新闻通讯以获取最新更新。
我们提供所有技术(如 Java 教程、Android、Java 框架)的教程和面试问题
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
